Mapreduce其他部分
1.hadoop的压缩codec
Codec为压缩,解压缩的算法实现。 在Hadoop中,codec由CompressionCode的实现来表示。下面是一些实现:

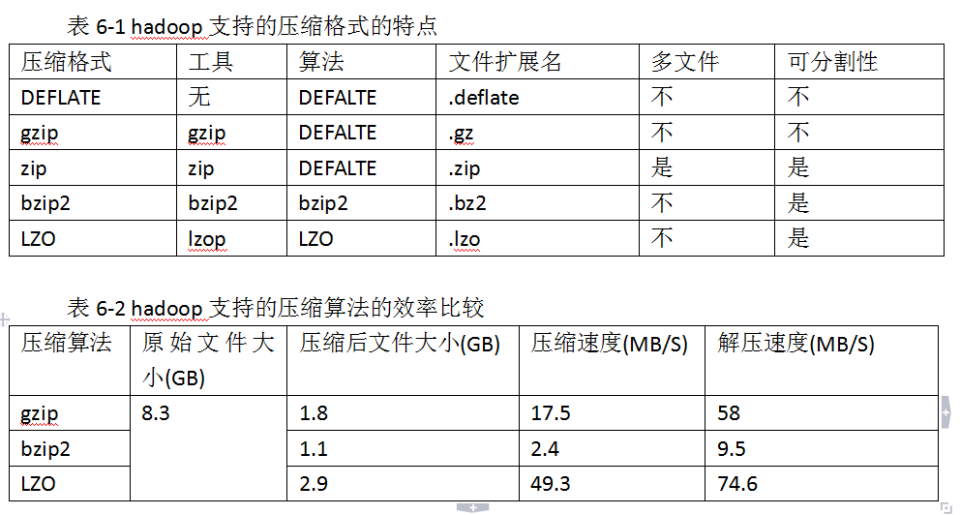
可分割性:可分割与不可分割的区别:文件是否可被切成多个inputsplit。
对于不能切割的文件,如果使用mapreduce算法,需要切割成一个inputsplit,那么这个文件在网络传输的时候必须连着传输
中间一旦传输失败就必须重传,一个inputsplit一般都比较小,对于文件比较大的文件可否分割也是影响性能的重要因素。
压缩比和压缩速度上综合相比LZO好一些,压缩速度是其他的十几倍,但是压缩比相差不大。
mapreduce中那些文件可压缩?
1. 输入文件可能是压缩文件
2.map输出可能是压缩文件
3.reduce输出可以压缩
代码:

完整的测试代码:
package Mapreduce; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.yarn.webapp.hamlet.Hamlet.MAP; /**
* 压缩文件实例
*
*
*/
public class CompressTest {
public static void main(String[] args) throws Exception {
//必须要传递的是自定的mapper和reducer的类,输入输出的路径必须指定,输出的类型<k3,v3>必须指定
//2将自定义的MyMapper和MyReducer组装在一起
Configuration conf=new Configuration();
String jobName=CompressTest.class.getSimpleName();
//1首先寫job,知道需要conf和jobname在去創建即可
Job job = Job.getInstance(conf, jobName); //*13最后,如果要打包运行改程序,则需要调用如下行
job.setJarByClass(CompressTest.class); //3读取HDFS內容:FileInputFormat在mapreduce.lib包下
FileInputFormat.setInputPaths(job, new Path("hdfs://neusoft-master:9000/data/hellodemo"));
//4指定解析<k1,v1>的类(谁来解析键值对)
//*指定解析的类可以省略不写,因为设置解析类默认的就是TextInputFormat.class
job.setInputFormatClass(TextInputFormat.class);
//5指定自定义mapper类
job.setMapperClass(MyMapper.class);
//6指定map输出的key2的类型和value2的类型 <k2,v2>
//*下面两步可以省略,当<k3,v3>和<k2,v2>类型一致的时候,<k2,v2>类型可以不指定
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//7分区(默认1个),排序,分组,规约 采用 默认 //**map端输出进行压缩
conf.setBoolean ("mapred.compress.map.output",true);
//**reduce端输出进行压缩
conf.setBoolean ("mapred.output.compress",true);
//**reduce端输出压缩使用的类
conf.setClass("mapred.output.compression.codec", GzipCodec.class, CompressionCodec.class);
//接下来采用reduce步骤
//8指定自定义的reduce类
job.setReducerClass(MyReducer.class);
//9指定输出的<k3,v3>类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//10指定输出<K3,V3>的类
//*下面这一步可以省
job.setOutputFormatClass(TextOutputFormat.class);
//11指定输出路径
FileOutputFormat.setOutputPath(job, new Path("hdfs://neusoft-master:9000/out11")); //12写的mapreduce程序要交给resource manager运行
job.waitForCompletion(true);
}
private static class MyMapper extends Mapper<LongWritable, Text, Text,LongWritable>{
Text k2 = new Text();
LongWritable v2 = new LongWritable();
@Override
protected void map(LongWritable key, Text value,//三个参数
Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] splited = line.split("\t");//因为split方法属于string字符的方法,首先应该转化为string类型在使用
for (String word : splited) {
//word表示每一行中每个单词
//对K2和V2赋值
k2.set(word);
v2.set(1L);
context.write(k2, v2);
}
}
}
private static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
LongWritable v3 = new LongWritable();
@Override //k2表示单词,v2s表示不同单词出现的次数,需要对v2s进行迭代
protected void reduce(Text k2, Iterable<LongWritable> v2s, //三个参数
Reducer<Text, LongWritable, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
long sum =0;
for (LongWritable v2 : v2s) {
//LongWritable本身是hadoop类型,sum是java类型
//首先将LongWritable转化为字符串,利用get方法
sum+=v2.get();
}
v3.set(sum);
//将k2,v3写出去
context.write(k2, v3);
}
}
}
压缩文件实例
结果对比:
1.无压缩时运行mapreduce的时间
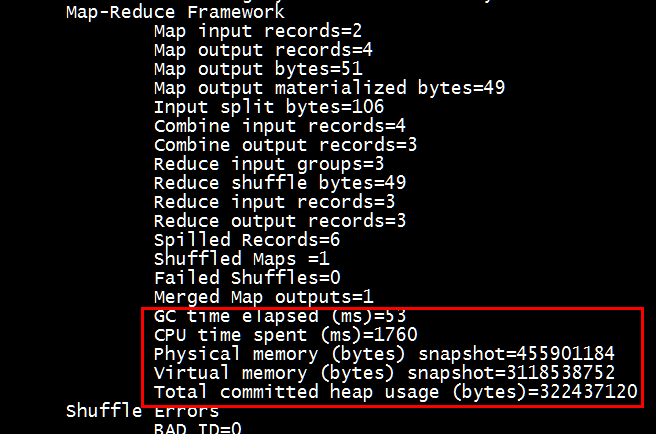
2.带压缩的运行时间
[root@neusoft-master filecontent]# hadoop jar CompressTest.jar
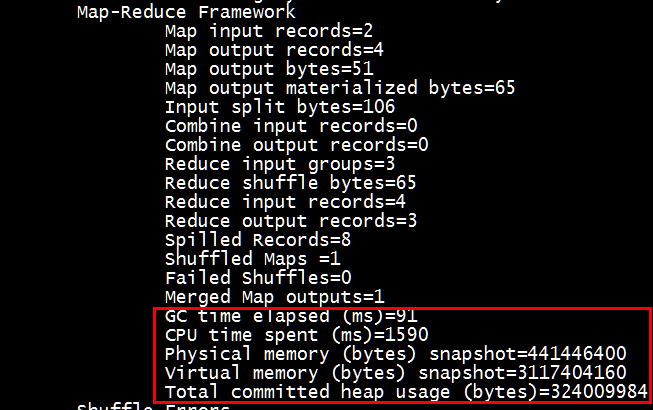
从时间上可以看出,运行时间和效率方面有了很大的提升,可以作为优化的一种。
2.mapreduce调度算法
hadoop目前支持以下三种调度器:
FifoScheduler:最简单的调度器,按照先进先出的方式处理应用。只有一个队列可提交应用,所有用户提交到这个队列。没有应用优先级可以配置。
CapacityScheduler:可以看作是FifoScheduler的多队列版本。每个队列可以限制资源使用量。但是,队列间的资源分配以使用量作排列依据,使得容量小的队列有竞争优势。集群整体吞吐较大。延迟调度机制使得应用可以放弃跨机器或者跨机架的调度机会,争取本地调度。 详情见官网http://hadoop.apache.org/docs/r1.2.1/capacity_scheduler.html
FairScheduler:多队列,多用户共享资源。特有的客户端创建队列的特性,使得权限控制不太完美。根据队列设定的最小共享量或者权重等参数,按比例共享资源。延迟调度机制跟CapacityScheduler的目的类似,但是实现方式稍有不同。资源抢占特性,是指调度器能够依据公平资源共享算法,计算每个队列应得的资源,将超额资源的队列的部分容器释放掉的特性。 详情见官网http://hadoop.apache.org/docs/r1.2.1/fair_scheduler.html

(1) FairScheduler的配置:
修改mapred-site.xml,然后重启集群 更多配置见conf/fair-scheduler.xml

(2)CapacityScheduler配置
修改mapred-site.xml,然后重启集群 更多配置见conf/capacity-scheduler.xml

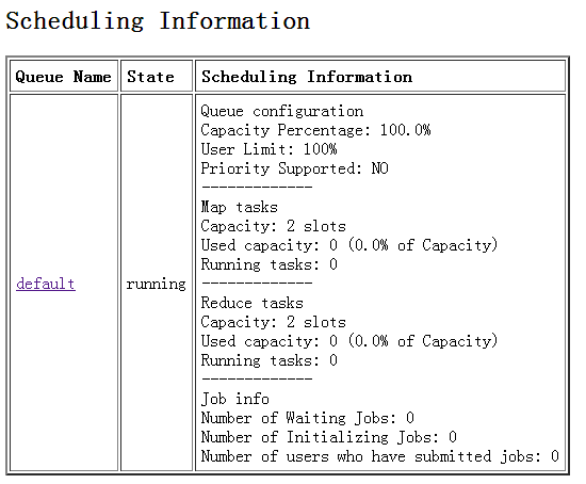
CapacityScheduler运行结果:
3.Hadoop Streaming
Hadoop Streaming是Hadoop提供的一个编程工具,它允许用户使用任何可执行文件或者脚本文件作为Mapper和Reducer,通过Hadoop Streaming编写的MapReduce应用程序中每个任务可以由不同的编程语言环境组成
4.MapReduce的job如何调优
- 如果存在大量的小数据文件,可以使用SequenceFile、自定义的CombineFileInputFormat
- 推测执行在整个集群上关闭,特定需要的作业单独开启,一般可以省下约5%~10%的集群资源
- mapred.map.task.speculative.execution=true; mapred.reduce.task.speculative.execution=false;
- 开启jvm重用 mapred.job.reuse.jvm.num.tasks=-1
- 增加InputSplit大小 mapred.min.split.size=268435456
- 增大map输出的缓存 io.sort.mb=300
- 增加合并spill文件数量 io.sort.factor=50 map端输出压缩,
- 推荐LZO压缩算法 mapred.compress.map.output=true; mapred.map.output.compression.codec=com.hadoop.compression.lzo.LzoCodec;
- 增大shuffle复制线程数 mapred.reduce.parallel.copies=15
- 设置单个节点的map和reduce执行数量(默认值是2) mapred.tasktracker.map.tasks.maxinum=2 mapred.tasktracker.reduce.tasks.maxinum=2
5.MapReduce常见算法
单词计数 数据去重 排序 Top K 选择 投影 分组 多表连接 单表关联
6.MapReduce中的join操作
- reduce side join
- map side join
Mapreduce其他部分的更多相关文章
- Mapreduce的文件和hbase共同输入
Mapreduce的文件和hbase共同输入 package duogemap; import java.io.IOException; import org.apache.hadoop.co ...
- mapreduce多文件输出的两方法
mapreduce多文件输出的两方法 package duogemap; import java.io.IOException; import org.apache.hadoop.conf ...
- mapreduce中一个map多个输入路径
package duogemap; import java.io.IOException; import java.util.ArrayList; import java.util.List; imp ...
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- [Hadoop in Action] 第5章 高阶MapReduce
链接多个MapReduce作业 执行多个数据集的联结 生成Bloom filter 1.链接MapReduce作业 [顺序链接MapReduce作业] mapreduce-1 | mapr ...
- MapReduce
2016-12-21 16:53:49 mapred-default.xml mapreduce.input.fileinputformat.split.minsize 0 The minimum ...
- 使用mapreduce计算环比的实例
最近做了一个小的mapreduce程序,主要目的是计算环比值最高的前5名,本来打算使用spark计算,可是本人目前spark还只是简单看了下,因此就先改用mapreduce计算了,今天和大家分享下这个 ...
- MapReduce剖析笔记之八: Map输出数据的处理类MapOutputBuffer分析
在上一节我们分析了Child子进程启动,处理Map.Reduce任务的主要过程,但对于一些细节没有分析,这一节主要对MapOutputBuffer这个关键类进行分析. MapOutputBuffer顾 ...
- MapReduce剖析笔记之七:Child子进程处理Map和Reduce任务的主要流程
在上一节我们分析了TaskTracker如何对JobTracker分配过来的任务进行初始化,并创建各类JVM启动所需的信息,最终创建JVM的整个过程,本节我们继续来看,JVM启动后,执行的是Child ...
- MapReduce剖析笔记之六:TaskTracker初始化任务并启动JVM过程
在上面一节我们分析了JobTracker调用JobQueueTaskScheduler进行任务分配,JobQueueTaskScheduler又调用JobInProgress按照一定顺序查找任务的流程 ...
随机推荐
- TIMEOUT HANDLING WITH HTTPCLIENT
https://www.thomaslevesque.com/2018/02/25/better-timeout-handling-with-httpclient/ The problem If yo ...
- js中forEach,for in,for of的区别
<!doctype html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- XSS三重URL编码绕过实例
遇到一个很奇葩的XSS,我们先来加一个双引号,看看输出: 双引号被转义了,我们对双引号进行URL双重编码,再看一下输出: 依然被转义了,我们再加一层URL编码,即三重url编码,再看一下输出: URL ...
- mongo数据库查询结果不包括_id字段方法
db.GPRS_PRODUCT_HIS_FEE.find({"条件字段" : "412171211145135"},{_id:0}) db.GPRS_PRODU ...
- Oracle 常用函数备查
ORACLE日期时间函数大全 TO_DATE格式(以时间:2007-11-02 13:45:25为例) Year: yy two digits 两位年 显示值:07 yyy three digits ...
- Win10 如何安装 Ubuntu
在 Microsoft Store 中安装 Ubuntu ( 如下图1 ) 把开发者模式打开 ( 如下图2 ) 把 WSL ( Windows下的Linux子系统 ) 打开并重启电脑 ( 如下图3 )
- C# - 获取类中属性的名称
用反射控制的,不过获取属性名称的方法,用方法形式获取的,不知道消耗大不大 using System; using System.Collections.Generic; using System.Li ...
- 【抓包分析】 charles + 网易mumu 模拟器数据包
charles 的使用.我就不再多说了.可以参考以往文章,传送门: https://www.cnblogs.com/richerdyoung/p/8616674.html 此处主要说网易模拟器的使用 ...
- php判断正常访问和外部访问
php判断正常访问和外部访问 <?php session_start(); if(isset($_POST['check'])&&!empty($_POST['name'])){ ...
- Java toString()方法的自动调用
如果某一个对象出现在字符串表达式中(涉及“+”字符串对象的表达式),toString()方法就会被自动调动.