drop解决过拟合的情况
用到的训练数据集:sklearn数据集
可视化工具:tensorboard,这儿记录了loss值(预测值与真实值的差值),通过loss值可以判断训练的结果与真实数据是否吻合
过拟合:训练过程中为了追求完美而导致问题
过拟合的情况:蓝线为实际情况,在误差为10的区间,他能够表示每条数据。
橙线为训练情况,为了追求0误差,他将每条数据都关联起来,但是如果新增一些点(+),他就不能去表示新增的点了

训练得到的值和实际测试得到的值相比,训练得到的loss更小,但它与实际不合,并不是loss值越小就越好
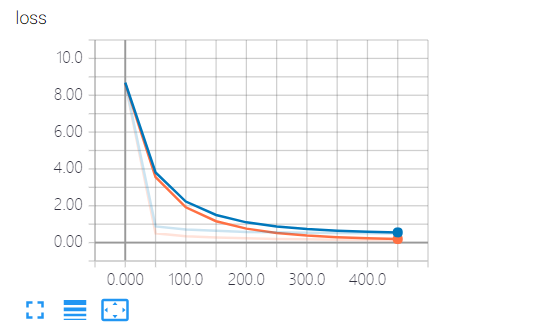

drop处理过拟合后:

代码:
import tensorflow as tf
from sklearn.datasets import load_digits
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import LabelBinarizer # load data
digits = load_digits()
X = digits.data
y = digits.target
y = LabelBinarizer().fit_transform(y) # 转换格式
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3) def add_layer(inputs, in_size, out_size, layer_name, active_function=None):
"""
:param inputs:
:param in_size: 行
:param out_size: 列 , [行, 列] =矩阵
:param active_function:
:return:
"""
with tf.name_scope('layer'):
with tf.name_scope('weights'):
W = tf.Variable(tf.random_normal([in_size, out_size]), name='W') #
with tf.name_scope('bias'):
b = tf.Variable(tf.zeros([1, out_size]) + 0.1) # b是一行数据,对应out_size列个数据
with tf.name_scope('Wx_plus_b'):
Wx_plus_b = tf.matmul(inputs, W) + b
Wx_plus_b = tf.nn.dropout(Wx_plus_b, keep_prob=keep_prob)
if active_function is None:
outputs = Wx_plus_b
else:
outputs = active_function(Wx_plus_b)
tf.summary.histogram(layer_name + '/outputs', outputs) # 1.2.记录outputs值,数据直方图
return outputs # define placeholder for inputs to network
keep_prob = tf.placeholder(tf.float32) # 不被dropout的数量
xs = tf.placeholder(tf.float32, [None, 64]) # 8*8
ys = tf.placeholder(tf.float32, [None, 10]) # add output layer
l1 = add_layer(xs, 64, 50, 'l1', active_function=tf.nn.tanh)
prediction = add_layer(l1, 50, 10, 'l2', active_function=tf.nn.softmax) # the loss between prediction and really
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction), reduction_indices=[1]))
tf.summary.scalar('loss', cross_entropy) # 字符串类型的标量张量,包含一个Summaryprotobuf 1.1记录标量(展示到直方图中 1.2 )
# training
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy) sess = tf.Session()
merged = tf.summary.merge_all() # 2.把所有summary节点整合在一起,只需run一次,这儿只有cross_entropy
sess.run(tf.initialize_all_variables()) train_writer = tf.summary.FileWriter('log/train', sess.graph) # 3.写入
test_writer = tf.summary.FileWriter('log/test', sess.graph) # cmd cd到log目录下,启动 tensorboard --logdir=log\ # start training
for i in range(500):
sess.run(train_step, feed_dict={xs: X_train, ys: y_train, keep_prob: 0.5}) # keep_prob训练时保留50%, 当这儿为1时,代表不drop任何数据,(没处理过拟合问题)
if i % 50 == 0:
# 4. record loss
train_result = sess.run(merged, feed_dict={xs: X_train, ys: y_train, keep_prob: 1}) # tensorboard记录保留100%的数据
test_result = sess.run(merged, feed_dict={xs: X_test, ys: y_test, keep_prob: 1})
train_writer.add_summary(train_result, i)
test_writer.add_summary(test_result, i) print("Record Finished !!!")
drop解决过拟合的情况的更多相关文章
- 过拟合是什么?如何解决过拟合?l1、l2怎么解决过拟合
1. 过拟合是什么? https://www.zhihu.com/question/264909622 那个英文回答就是说h1.h2属于同一个集合,实际情况是h2比h1错误率低,你用h1来训练, ...
- tensorflow学习之路---解决过拟合
''' 思路:1.调用数据集 2.定义用来实现神经元功能的函数(包括解决过拟合) 3.定义输入和输出的数据4.定义隐藏层(函数)和输出层(函数) 5.分析误差和优化数据(改变权重)6.执行神经网络 ' ...
- L1与L2正则化的对比及多角度阐述为什么正则化可以解决过拟合问题
正则化是一种回归的形式,它将系数估计(coefficient estimate)朝零的方向进行约束.调整或缩小.也就是说,正则化可以在学习过程中降低模型复杂度和不稳定程度,从而避免过拟合的危险. 一. ...
- 解决谷歌浏览器在F12情况下自动断点问题(Paused in debugger)
解决谷歌浏览器在F12情况下自动断点问题(Paused in debugger) 最近在使用谷歌浏览器在调试js脚本的时候,每次按F12,再刷新页面,都会跳出如上图所示的图标,自动进入断点调试.如果不 ...
- 把cookie以json形式返回,用js来set cookie.(解决手机浏览器未知情况下获取不到cookie)
.继上一篇随笔,链接点我,解决手机端cookie的问题. .上次用cookie+redis实现了session,并且手机浏览器可能回传cookies有问题,所以最后用js取出cookie跟在请求的ur ...
- (五)用正则化(Regularization)来解决过拟合
1 过拟合 过拟合就是训练模型的过程中,模型过度拟合训练数据,而不能很好的泛化到测试数据集上.出现over-fitting的原因是多方面的: 1) 训练数据过少,数据量与数据噪声是成反比的,少量数据导 ...
- RabbitMQ 使用QOS(服务质量)+Ack机制解决内存崩溃的情况
当消息有几万条或者几十万条的时候,如果消费的方式不对,会造成内存崩溃的情况 一:consumer 1. 短链接:basicget 独自去获取message... request 的方式去获取,断开式. ...
- 深度学习中 --- 解决过拟合问题(dropout, batchnormalization)
过拟合,在Tom M.Mitchell的<Machine Learning>中是如何定义的:给定一个假设空间H,一个假设h属于H,如果存在其他的假设h’属于H,使得在训练样例上h的错误率比 ...
- CS229 5.用正则化(Regularization)来解决过拟合
1 过拟合 过拟合就是训练模型的过程中,模型过度拟合训练数据,而不能很好的泛化到测试数据集上.出现over-fitting的原因是多方面的: 1) 训练数据过少,数据量与数据噪声是成反比的,少量数据导 ...
随机推荐
- caffe安装编译问题-ImportError: No module named google.protobuf.internal
问题描述 ~/Downloads/caffe$ python Python (default, Dec , ::) [GCC ] on linux2 Type "help", &q ...
- 把默认功能关闭,当做普通IO口使用。
GPIO_PinRemapConfig(GPIO_Remap_SWJ_JTAGDisable,ENABLE); //禁止 JTAG选择SW模式,从而 PA15 可以做普通 IO 使用,否则 PA15 ...
- [LeetCode&Python] Problem 806. Number of Lines To Write String
We are to write the letters of a given string S, from left to right into lines. Each line has maximu ...
- 使用pip install XX 命令时报错
在使用pip命令安装的时候,我遇到这样的报错: C:\Users\86962>pip install Appium-Python-Client Collecting Appium-Python- ...
- Django Rest FrameWork 全部API
Django Rest FrameWork .Requests 请求 客服端发送给服务器的请求 .Responses 响应 rest框架支持响应不同格式的内容 .Views 视图 base基础类视图 ...
- 2018-2019-2 网络对抗技术 20165212 Exp4 恶意代码分析
2018-2019-2 网络对抗技术 20165212 Exp4 恶意代码分析 原理与实践说明 1.实践目标 监控你自己系统的运行状态,看有没有可疑的程序在运行. 分析一个恶意软件,就分析Exp2或E ...
- ballerina 学习二十九 数据库操作
ballerina 数据操作也是比较方便的,官方也我们提供了数据操作的抽象,但是我们还是依赖数据库驱动的. 数据库驱动还是jdbc模式的 项目准备 项目结构 ├── mysql_demo │ ├── ...
- streamsets 集成 rabbitmq 以及benthos stream 处理框架
benthos 是一个stream 处理框架,streamsets 也是,但是两者可以通过不同的工具进行集成起来 一般我们可以使用http 服务,消息中间件(kafka.rabbitmq ...) 使 ...
- Git中特别的命令
Rebase 假设我们的分支结构如下: rebase 会把从 Merge Base 以来的所有提交,以补丁的形式一个一个重新达到目标分支上.这使得目标分支合并该分支的时候会直接 Fast Forwar ...
- k最邻近算法——加权kNN
加权kNN 上篇文章中提到为每个点的距离增加一个权重,使得距离近的点可以得到更大的权重,在此描述如何加权. 反函数 该方法最简单的形式是返回距离的倒数,比如距离d,权重1/d.有时候,完全一样或非常接 ...