利用python2.7正则表达式进行豆瓣电影Top250的网络数据采集及MySQL数据库操作
转载请注明出处
利用python2.7正则表达式进行豆瓣电影Top250的网络数据采集
1.任务
采集豆瓣电影名称、链接、评分、导演、演员、年份、国家、评论人数、简评等信息
将以上数据存入MySQL数据库
2.任务解析
requests是很好的网络数据采集模块,配合BeautifulSoup可以解析许多HTML。但个人认为BeautifulSoup返回对象不是字符串,而利用其find及findall总觉得力有未逮,与正则表达式的配合总显得有些冗余,甚至需要将BeautifulSoup返回对象转换成字符串形式与正则表达式配合使用,这里我不再利用BeautifulSoup,而是直接利用requests得到的网络文本配合正则表达式完成本次任务。
利用request得到的网络文本,这里截取一段某部电影的完整的网络文本:
<li>
<div class="item">
<div class="pic">
<em class="">2</em>
<a href="https://movie.douban.com/subject/1295644/">
<img alt="这个杀手不太冷" src="https://img3.doubanio.com/view/movie_poster_cover/ipst/public/p511118051.jpg" class="">
</a>
</div>
<div class="info">
<div class="hd">
<a href="https://movie.douban.com/subject/1295644/" class="">
<span class="title">这个杀手不太冷</span>
<span class="title"> / Léon</span>
<span class="other"> / 杀手莱昂 / 终极追杀令(台)</span>
</a> <span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 吕克·贝松 Luc Besson 主演: 让·雷诺 Jean Reno / 娜塔丽·波特曼 ...<br>
1994 / 法国 / 剧情 动作 犯罪
</p> <div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.4</span>
<span property="v:best" content="10.0"></span>
<span>712293人评价</span>
</div> <p class="quote">
<span class="inq">怪蜀黍和小萝莉不得不说的故事。</span>
</p>
</div>
</div>
</div>
</li>
其他部分正则匹配参考代码相关部分
需要说明的是,电影年份中第84部《大闹天空》年份如下:'1961(上集) / 1964(下集) / 1978(全本) / 2004(纪念版)',不能通过数字匹配的方式获取年份,因此需要添加。某些电影没有主演及简评等信息,这里需要查找添加。相关代码见78-90行
3.代码
#!/usr/bin/python
# -*- coding: utf-8 -*- #
# 豆瓣电影top250
import requests,sys,re,MySQLdb,time reload(sys)
sys.setdefaultencoding('utf-8')
print '正在从豆瓣电影Top250抓取数据......'
# --------------------------创建列表用于存放数据-----------------------------#
nameList=[]
linkList=[]
scoreList=[]
directorList=[]
playList=[]
yearList=[]
countryList=[]
commentList=[]
criticList=[]
#---------------------------------爬取模块------------------------------------#
def topMovie():
for page in range(1):
url='https://movie.douban.com/top250?start='+str(page*25)
print '正在爬取第---'+str(page+1)+'---页......'
html=requests.get(url)
html.raise_for_status()
try:
contents=html.text # 返回网页内容,是字符串的形式
# ---------------------------------匹配电影中文名------------------------------------#
name=re.compile(r'<span class="title">(.*)</span>')
names=re.findall(name,contents)
for movieName in names:
if movieName.find('/')==-1:
nameList.append(movieName)
# ---------------------------------匹配电影链接------------------------------------#
link=re.compile(r'a href="(.*)" class=""')
links=re.findall(link,contents)
for movieLink in links:
linkList.append(movieLink)
# ---------------------------------匹配电影评分------------------------------------#
score=re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
scores=re.findall(score,contents)
for movieScore in scores:
scoreList.append(movieScore)
# ---------------------------------匹配导演------------------------------------#
director=re.compile(ur'导演: (.*) ')
directors=re.findall(director,contents)
for movieDirector in directors:
directorList.append(movieDirector)
# ---------------------------------匹配主演------------------------------------#
play=re.compile(u'主(.*?)<br>')
plays=re.findall(play,contents)
for moviePlay in plays:
playList.append(moviePlay.strip(ur'演: '))
# ---------------------------------匹配年份------------------------------------#
year=re.compile(r'(\d\d\d\d) / ')
years=re.findall(year,contents)
for movieyear in years:
yearList.append(movieyear)
# ---------------------------------匹配国家------------------------------------#
country=re.compile(ur' / (.*) / ')
countries=re.findall(country,contents)
for movieCountry in countries:
countryList.append(movieCountry)
# ---------------------------------匹配评价人数------------------------------------#
commentor=re.compile(ur'<span>(.*)人评价</span>')
commentors=re.findall(commentor,contents)
for movieCommentor in commentors:
commentList.append(movieCommentor)
# ---------------------------------匹配简评------------------------------------#
critic=re.compile(r'<span class="inq">(.*)</span>')
critics=re.findall(critic,contents)
for movieCritic in critics:
criticList.append(movieCritic) except Exception as e:
print e
print '爬取完毕!'
# ---------------------------------个别部分修改-----------------------------------#
# 需要在第84部《大闹天空》不能通过上面的方法筛选,需要在83后加入加入数据
yearList.insert(83, '1961(上集) / 1964(下集) / 1978(全本) / 2004(纪念版)')
playList.insert(38,'...') # 某些电影没有主演和评论,这里用...代替
playList.insert(233,'...')
criticList.insert(134,'...')
criticList.insert(156,'...')
criticList.insert(176,'...')
criticList.insert(180,'...')
criticList.insert(196,'...')
criticList.insert(230,'...')
criticList.insert(232,'...')
return nameList,linkList,scoreList,directorList,playList,yearList,countryList,commentList,criticList
# ---------------------------------储存到数据库-----------------------------------#
def save_to_MySQL():
print 'MySQL数据库存储中......'
try:
conn = MySQLdb.connect(host="127.0.0.1", user="root", passwd="******", db="test", charset="utf8")
cursor = conn.cursor()
print "数据库连接成功"
cursor.execute('Drop table if EXISTS MovieTop250') # 如果表存在就删除
time.sleep(3)
cursor.execute('''create table if not EXISTS MovieTop250(
编号 int not NULL auto_increment PRIMARY KEY ,
电影名称 VARCHAR (200),
链接 VARCHAR (200),
导演 VARCHAR (200),
主演 VARCHAR (200),
年份 VARCHAR (200),
国家 VARCHAR (200),
评价人数 VARCHAR (200),
简评 VARCHAR (200),
评分 VARCHAR (20))''')
for i in range(250):
sql='insert into MovieTop250(电影名称,链接,导演,主演,年份,国家,评价人数,简评,评分)' \
' VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s)'
param=(nameList[i],linkList[i],directorList[i],playList[i],yearList[i],
countryList[i],commentList[i],criticList[i],scoreList[i])
cursor.execute(sql,param)
conn.commit()
cursor.close()
conn.close()
except Exception as e:
print e
print 'MySQL数据库存储结束!' # -------------------------------------主模块--------------------------------------#
if __name__=="__main__": # 相当于c语言中的main()函数
try:
topMovie()
save_to_MySQL()
except Exception as e:
print e
4.结果
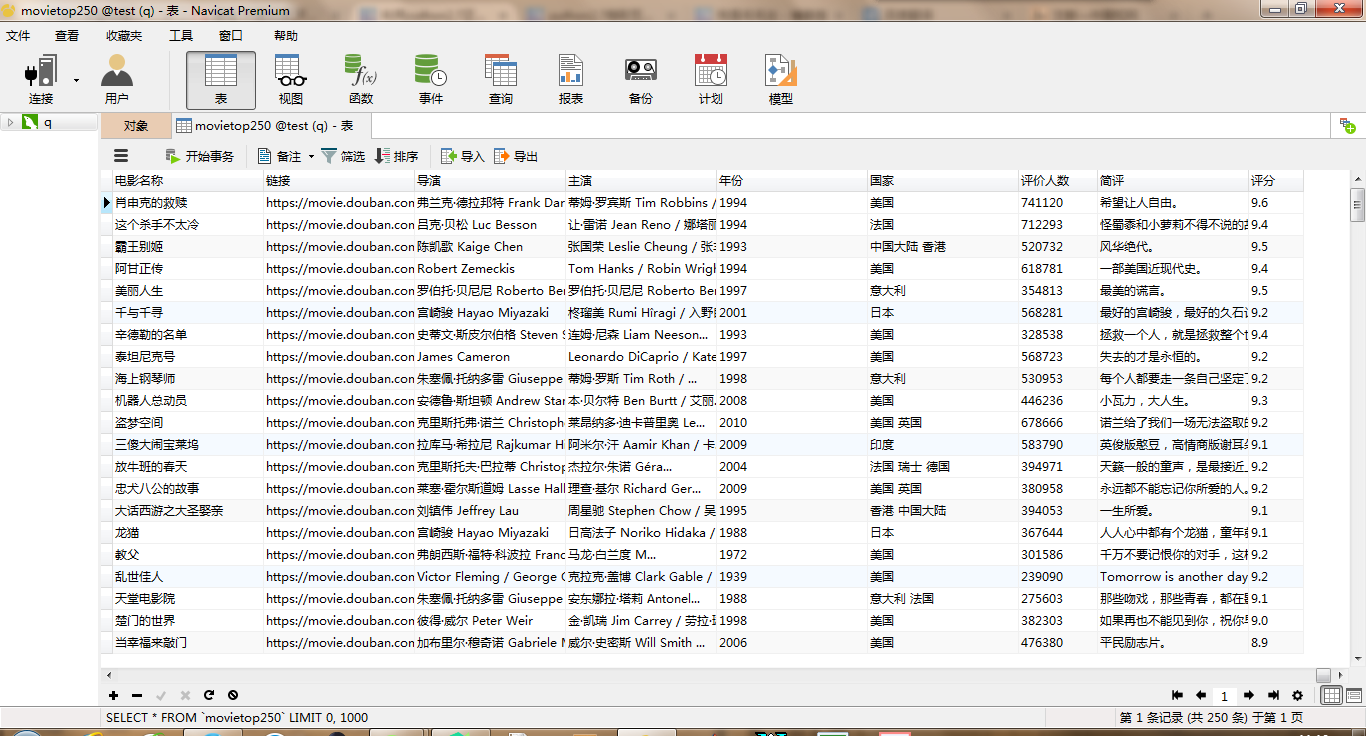
欢迎大家与我交流,一起学习和探讨。
利用python2.7正则表达式进行豆瓣电影Top250的网络数据采集及MySQL数据库操作的更多相关文章
- python2.7抓取豆瓣电影top250
利用python2.7抓取豆瓣电影top250 1.任务说明 抓取top100电影名称 依次打印输出 2.网页解析 要进行网络爬虫,利用工具(如浏览器)查看网页HTML文件的相关内容是很有必要,我使用 ...
- python2.7爬取豆瓣电影top250并写入到TXT,Excel,MySQL数据库
python2.7爬取豆瓣电影top250并分别写入到TXT,Excel,MySQL数据库 1.任务 爬取豆瓣电影top250 以txt文件保存 以Excel文档保存 将数据录入数据库 2.分析 电影 ...
- 利用AJAX JAVA 通过Echarts实现豆瓣电影TOP250的数据可视化
mysql表的结构 数据(数据是通过爬虫得来的,本篇文章不介绍怎么爬取数据,只介绍将数据库中的数据可视化): 下面就是写代码了: 首先看一下项目目录: 数据库层 业务逻辑层 pac ...
- 利用selenium爬取豆瓣电影Top250
这几天在学习selenium,顺便用selenium + python写了一个比较简陋的爬虫,现附上源码,有时间再补充补充: from selenium import webdriver from s ...
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- urllib+BeautifulSoup无登录模式爬取豆瓣电影Top250
对于简单的爬虫任务,尤其对于初学者,urllib+BeautifulSoup足以满足大部分的任务. 1.urllib是Python3自带的库,不需要安装,但是BeautifulSoup却是需要安装的. ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- Scrapy爬虫(4)爬取豆瓣电影Top250图片
在用Python的urllib和BeautifulSoup写过了很多爬虫之后,本人决定尝试著名的Python爬虫框架--Scrapy. 本次分享将详细讲述如何利用Scrapy来下载豆瓣电影To ...
随机推荐
- 【python,threading】python多线程
使用多线程的方式 1. 函数式:使用threading模块threading.Thread(e.g target name parameters) import time,threading def ...
- input输入框,回车激活按钮事件代码
<input type="text" name="输入框ID" id="输入框ID" onkeypress="if(even ...
- Rolls.java (page44)
对象的数组:模拟T次投掷骰子的Counter对象的用例: Rolls.java 如下:所用类列表:Counter, StdOut, StdRandom 见page42 public class Rol ...
- sgu 185 最短路建网络流
题目:给出一个图,从图中找出两条最短路,使得边不重复. 分析:既然是最短路,那么,两条路径上的所有节点的入边(s,x).出边(x,e)必定是最优的,即 dis[x] = dis[s]+edge_dis ...
- 深入浅出ExtJS 第七章 弹出窗口
7.1 Ext.MessageBox 7.1 Ext.MessageBox //Ext.MessageBox为我们提供的alert/confirm/prompt等完全可以代替浏览器原生; 7.1.1 ...
- 物联网 WIFI 一键配置原理(smartconfig) ESP8266/QCA4004
自从物联网 问世以来,如何使得物 能够联网 有了很多的方式,目前运用非常广的WIFI,今天就总结下自这个方面,也对于有需要的盆友 也希望有抛砖引玉之效果. 物联网: 智能硬件+APP+云 APP ...
- 十六、Android 滑动效果汇总
Android 滑动效果入门篇(一)—— ViewFlipper Android 滑动效果入门篇(二)—— Gallery Android 滑动效果基础篇(三)—— Gallery仿图像集浏览 And ...
- 如何使用10个小时搭建出个人域名而又Geek的独立博客?
1.安装准备软件 Node.js.Git.GitHub DeskTop(前两个必须安装,后者可选) 2.本地搭建hexo框架.配置主题.修改参数.实现本地测试预览 3.链接GitHub.实现在线预览 ...
- 各个手机APP客户端内置浏览器useragent
手机QQ Mozilla/5.0 (Linux; Android 4.4.2; GT-I9500 Build/KOT49H) AppleWebKit/537.36 (KHTML, like Gecko ...
- php中sprintf与printf函数用法区别
下面是一个示例:四舍五入保留小数点后两位 代码如下 复制代码 <?php$num1 = 21;echo sprintf("%0.2f",$num1)."<b ...