编写高质量代码:改善Java程序的151个建议(第4章:字符串___建议56~59)
建议56:自由选择字符串拼接方法
对一个字符串拼接有三种方法:加号、concat方法及StringBuilder(或StringBuffer ,由于StringBuffer的方法与StringBuilder相同,不在赘述)的append方法,其中加号是最常用的,其它两种方式偶尔会出现在一些开源项目中,那这三者之间有什么区别吗?我们看看下面的例子:
public class Client56 {
public static void main(String[] args) {
// 加号拼接
String str = "";
long start1 = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
str += "c";
}
long end1 = System.currentTimeMillis();
System.out.println("加号拼接耗时:" + (end1 - start1) + "ms");
// concat拼接
str = "";
long start2 = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
str = str.concat("c");
}
long end2 = System.currentTimeMillis();
System.out.println("concat拼接耗时:" + (end2 - start2) + "ms");
// StringBuilder拼接
str = "";
StringBuilder buffer = new StringBuilder("");
long start3 = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
buffer.append("c");
}
long end3 = System.currentTimeMillis();
System.out.println("StringBuilder拼接耗时:" + (end3 - start3) + "ms");
// StringBuffer拼接
str = "";
StringBuffer sb = new StringBuffer("");
long start4 = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
sb.append("c");
}
long end4 = System.currentTimeMillis();
System.out.println("StringBuffer拼接耗时:" + (end4 - start4) + "ms");
}
}
上面是4种不同方式的字符串拼接方式,循环10万次后检查其执行时间,执行结果如下:
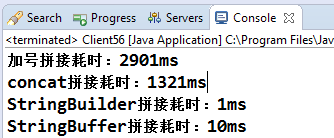
从上面的执行结果来看,在字符串拼接方式中,StringBuilder的append方法最快,StringBuffer的append方法次之(因为StringBuffer的append方法是线程安全的,同步方法自然慢一点),其次是concat方法,加号最慢,这是为何呢?
(1)、"+" 方法拼接字符串:虽然编辑器对字符串的加号做了优化,它会使用StringBuilder的append方法进行追加,按道理来说,其执行时间也应该是1ms,不过最终是通过toString方法转换为String字符串的,例子中的"+" 拼接的代码如下代码相同
str= new StringBuilder(str).append("c").toString();
注意看,它与纯粹使用StringBuilder的append方法是不同的:一是每次循环都会创建一个StringBuilder对象,二是每次执行完毕都要调用toString方法将其转换为字符串——它的执行时间就耗费在这里了!
(2)、concat方法拼接字符串:我们从源码上看一下concat方法的实现,代码如下:
public String concat(String str) {
int otherLen = str.length();
//如果追加字符长度为0,则返回字符串本身
if (otherLen == 0) {
return this;
}
int len = value.length;
char buf[] = Arrays.copyOf(value, len + otherLen);
str.getChars(buf, len);
//产生一个新的字符串
return new String(buf, true);
}
其整体看上去就是一个数组拷贝,虽然在内存中处理都是原子性操作,速度非常快,不过,注意看最后的return语句,每次concat操作都会创建一个String对象,这就是concat速度慢下来的真正原因,它创建了10万个String对象呀。
(3)、append方法拼接字符串:StringBuilder的append方法直接由父类AbstractStringBuilder实现,其代码如下:
public StringBuilder append(String str) {
super.append(str);
return this;
}
public AbstractStringBuilder append(String str) {
//如果是null值,则把null作为字符串处理
if (str == null) str = "null";
int len = str.length();
ensureCapacityInternal(count + len);
//字符串复制到目标数组
str.getChars(0, len, value, count);
count += len;
return this;
}
看到没,整个append方法都在做字符数组处理,加长,然后拷贝数组,这些都是基本的数据处理,没有创建任何对象,所以速度也就最快了!注意:例子中是在随后通过StringBuilder的toString方法返回了一个字符串,也就是说在10万次循环结束后才生成了一个String对象。StringBuffer的处理和此类似,只是方法是同步的而已。
四者的实现方法不同,性能也就不同,但并不表示我们一定要使用StringBuilder,这是因为"+"非常符合我们的编码习惯,适合阅读,两个字符串拼接,就用加号连一下,这很正常,也很友好,在大多数情况下我们都可以使用加号操作,只有在系统性能临界(如在性能 " 增长一分则太长" 的情况下)的时候才可以考虑使用concat或append方法。而且,很多时候系统80% 的性能是消耗在20%的代码上的,我们的精力应该更多的投入到算法和结构上。
注意:适当的场景使用适当的字符串拼接方式。
建议57:推荐在复杂字符串操作中使用正则表达式
字符串的操作,诸如追加、合并、替换、倒叙、分割等,都是在编码过程中经常用到的,而且Java也提供了append、replace、reverse、spit等方法来完成这些操作,它们使用起来确实方便,但是更多时候,需要使用正则表达式来完成复杂的处理,我们来看一个例子:统计一篇文章中英文单词的数量,很简单吧,代码如下:
public class Client57 {
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
while (input.hasNext()) {
String str = input.nextLine();
// 使用split方法分割后统计
int wordsCount = str.split(" ").length;
System.out.println(str + "单词数:" + wordsCount);
}
}
}
使用spit方法根据空格来分割单词,然后计算分割后的数组长度,这种方法可靠吗?我们看看输出结果:
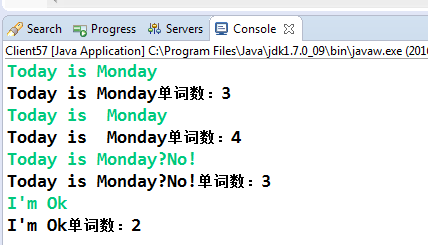
注意看输出,除了第一个输入"Today is Monday"正确外,其它的都是错误的!第二条输入中的单词"Monday"前有2个连续的空格,第三条输入中"No"单词前后都没有空格,最后一个输入则没有把连写符号" ' "考虑进去,这样统计出来的单词数量肯定是错误一堆,那怎么做才合理呢?
如果考虑使用一个循环来处理这样的"异常"情况,会使程序的稳定性变差,而且要考虑太多太多的因素,这让程序的复杂性也大大提高了。那如何处理呢?可以考虑使用正则表达式,代码如下:
public class Client57 {
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
while (input.hasNext()) {
String str = input.nextLine();
//正则表达式对象
Pattern p = Pattern.compile("\\b\\w+\\b");
//生成匹配器
Matcher matcher =p.matcher(str);
int wordsCount = 0;
while(matcher.find()){
wordsCount++;
}
System.out.println(str + "单词数:" + wordsCount);
}
}
}
准不准确,我们看看相同的输入,输出结果如下:
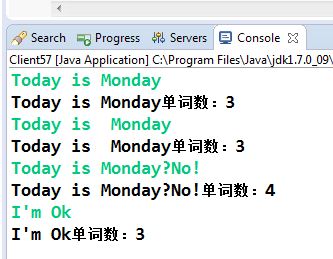
每项的输出都是准确的,而且程序也不复杂,先生成一个正则表达式对象,然后使用匹配器进行匹配,之后通过一个while循环统计匹配的数量。需要说明的是,在Java的正则表达式中"\b" 表示的是一个单词的边界,它是一个位置界定符,一边为字符或数字,另外一边为非字符或数字,例如"A"这样一个输入就有两个边界,即单词"A"的左右位置,这也就说明了为什么要加上"\w"(它表示的是字符或数字)。
正则表达式在字符串的查找,替换,剪切,复制,删除等方面有着非凡的作用,特别是面对大量的文本字符需要处理(如需要读取大量的LOG日志)时,使用正则表达式可以大幅地提高开发效率和系统性能,但是正则表达式是一个恶魔,它会使程序难以读懂,想想看,写一个包含^、$、\A、\s、\Q、+、?、()、{}、[]等符号的正则表达式,然后再告诉你这是一个" 这样,这样......"字符串查找,你是不是要崩溃了?这个代码确实不好阅读,你就要在正则上多下点功夫了。
注意:正则表达式是恶魔,威力巨大,但难以控制。
建议58:强烈建议使用UTF编码
Java的乱码问题由来已久,有经验的开发人员肯定遇到过乱码,有时从Web接收的乱码,有时从数据库中读取的乱码,有时是在外部接口中接收的乱码文件,这些都让我们困惑不已,甚至是痛苦不堪,看如下代码:
public class Client58 {
public static void main(String[] args) throws UnsupportedEncodingException {
String str = "汉字";
// 读取字节
byte b[] = str.getBytes("UTF-8");
// 重新生成一个新的字符串
System.out.println(new String(b));
}
}
Java文件是通过IDE工具默认创建的,编码格式是GBK,大家想想看上面的输出结果会是什么?可能是乱码吧?两个编码格式不同。我们暂时不说结果,先解释一下Java中的编码规则。Java程序涉及的编码包括两部分:
(1)、Java文件编码:如果我们使用记事本创建一个.java后缀的文件,则文件的编码格式就是操作系统默认的格式。如果是使用IDE工具创建的,如Eclipse,则依赖于IDE的设置,Eclipse默认是操作系统编码(Windows一般为GBK);
(2)、Class文件编码:通过javac命令生成的后缀名为.class的文件是UTF-8编码的UNICODE文件,这在任何操作系统上都是一样的,只要是.class文件就会使UNICODE格式。需要说明的是,UTF是UNICODE的存储和传输格式,它是为了解决UNICODE的高位占用冗余空间而产生的,使用UTF编码就意味着字符集使用的是UNICODE.
再回到我们的例子上,getBytes方法会根据指定的字符集取出字节数组(这里按照UNICODE格式来提取),然后程序又通过new String(byte [] bytes)重新生成一个字符串,来看看String的这个构造函数:通过操作系统默认的字符集解码指定的byte数组,构造一个新的String,结果已经很清楚了,如果操作系统是UTF-8的话,输出就是正确的,如果不是,则会是乱码。由于这里使用的是默认编码GBK,那么输出的结果也就是乱码了。我们再详细分解一下运行步骤:
步骤1:创建Client58.java文件:该文件的默认编码格式GBK(如果是Eclipse,则可以在属性中查看到)。
步骤2:编写代码(如上);
步骤3:保存,使用javac编译,注意我们没有使用"javac -encoding GBK Client58.java" 显示声明Java的编码方式,javac会自动按照操作系统的编码(GBK)读取Client58.java文件,然后将其编译成.class文件。
步骤4:生成.class文件。编译结束,生成.class文件,并保存到硬盘上,此时 .class文件使用的UTF-8格式编码的UNICODE字符集,可以通过javap 命令阅读class文件,其中" 汉字"变量也已经由GBK转变成UNICODE格式了。
步骤5:运行main方法,提取"汉字"的字节数组。"汉字" 原本是按照UTF-8格式保存的,要再提取出来当然没有任何问题了。
步骤6:重组字符串,读取操作系统默认的编码GBK,然后重新编码变量b的所有字节。问题就在这里产生了:因为UNICODE的存储格式是两个字节表示一个字符(注意:这里是指UCS-2标准),虽然GBK也是两个字节表示一个字符,但两者之间没有映射关系,只要做转换只能读取映射表,不能实现自动转换----于是JVM就按照默认的编码方式(GBK)读取了UNICODE的两个字节。
步骤7:输出乱码,程序运行结束,问题清楚了,解决方案也随之产生,方案有两个。
步骤8:修改代码,明确指定编码即可,代码如下:
System.out.println(new String(b,"UTF-8"));
步骤9:修改操作系统的编码方式,各个操作系统的修改方式不同,不再赘述。
我们可以把字符串读取字节的过程看做是数据传输的需要(比如网络、存储),而重组字符串则是业务逻辑的需求,这样就可以是乱码重现:通过JDBC读取的字节数组是GBK的,而业务逻辑编码时采用的是UTF-8,于是乱码就产生了。对于此类问题,最好的解决办法就是使用统一的编码格式,要么都用GBK,要么都用UTF-8,各个组件、接口、逻辑层、都用UTF-8,拒绝独树一帜的情况。
问题清楚了,我么看看以下代码:
public class Client58 {
public static void main(String[] args) throws UnsupportedEncodingException {
String str = "汉字";
// 读取字节
byte b[] = str.getBytes("GB2312");
// 重新生成一个新的字符串
System.out.println(new String(b));
}
}
仅仅修改了读取字节的编码方式(修改成了GB2312),结果会怎样呢?又或者将其修改成GB18030,结果又是怎样的呢?结果都是"汉字",不是乱码。这是因为GB2312是中文字符集的V1.0版本,GBK是V2.0版本,GB18030是V3.0版本,版本是向下兼容的,只是它们包含的汉字数量不同而已,注意UNICODE可不在这个序列之内。
注意:一个系统使用统一的编码。
建议59:对字符串持有一种宽容的心态
在Java 中一涉及中文处理就会冒出很多问题来,其中排序也是一个让人头疼的课题,我们看如下代码:
public class Client59 {
public static void main(String[] args) {
String[] strs = { "张三(Z)", "李四(L)", "王五(W)" };
Arrays.sort(strs);
int i = 0;
for (String str : strs) {
System.out.println((++i) + "、" + str);
}
}
}
上面的代码定义了一个数组,然后进行升序排序,我们期望的结果是按照拼音升序排列,即为李四、王五、张三,但是结果却不是这样的:
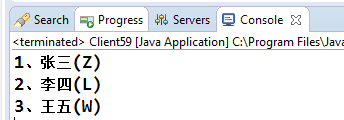
这是按照什么排的序呀,非常混乱!我们知道Arrays工具类的默认排序是通过数组元素的compareTo方法进行比较的,那我们来看String类的compareTo的主要实现:
public int compareTo(String anotherString) {
int len1 = value.length;
int len2 = anotherString.value.length;
int lim = Math.min(len1, len2);
char v1[] = value;
char v2[] = anotherString.value;
int k = 0;
while (k < lim) {
char c1 = v1[k];
char c2 = v2[k];
if (c1 != c2) {
return c1 - c2;
}
k++;
}
return len1 - len2;
}
上面的代码先取得字符串的字符数组,然后一个一个地比较大小,注意这里是字符比较(减号操作符),也就是UNICODE码值比较,查一下UNICODE代码表,"张" 的码值是5F20,"李"是674E,这样一看,"张" 排在 "李" 前面也就很正确了---但这明显与我们的意图冲突了。这一点在JDK的文档中也有说明:对于非英文的String排序可能会出现不准确的情况,那该如何解决这个问题呢?Java推荐使用collator类进行排序,那好,我们把代码修改一下:
public class Client59 {
public static void main(String[] args) {
String[] strs = { "张三(Z)", "李四(L)", "王五(W)" };
//定义一个中文排序器
Comparator c = Collator.getInstance(Locale.CHINA);
Arrays.sort(strs,c);
int i = 0;
for (String str : strs) {
System.out.println((++i) + "、" + str);
}
}
}
输出结果:
1、李四(L)
2、王五(W)
3、张三(Z)
这确实是我们期望的结果,应该不会错了吧!但是且慢,中国的汉字博大精深,Java是否都能精确的排序呢?最主要的一点是汉字中有象形文字,音形分离,是不是每个汉字都能按照拼音的顺序排好呢?我们写一个复杂的汉字来看看:
public class Client59 {
public static void main(String[] args) {
String[] strs = { "犇(B)", "鑫(X)", "淼(M)" };
//定义一个中文排序器
Comparator c = Collator.getInstance(Locale.CHINA);
Arrays.sort(strs,c);
int i = 0;
for (String str : strs) {
System.out.println((++i) + "、" + str);
}
}
}
输出结果如下:
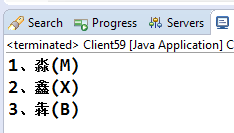
输出结果又乱了,不要责怪Java,它们已尽量为我们考虑了,只是因为我们的汉字文化太博大精深了,要做好这个排序确实有点为难它,更深层次的原因是Java使用的是UNICODE编码,而中文UNICODE字符集来源于GB18030的,GB18030又是从GB2312发展起来,GB2312是一个包含了7000多个字符的字符集,它是按照拼音排序,并且是连续的,之后的GBK、GB18030都是在其基础上扩充而来的,所以要让它们完整的排序也就难上加难了。
如果排序对象是经常使用的汉字,使用Collator类排序完全可以满足我们的要求,毕竟GB2312已经包含了大部分的汉字,如果需要严格排序,则要使用一些开源项目来自己实现了,比如pinyin4j可以把汉字转换为拼音,然后我们自己来实现排序算法,不过此时你会发现要考虑的诸如算法、同音字、多音字等众多问题。
注意:如果排序不是一个关键算法,使用Collator类即可。
编写高质量代码:改善Java程序的151个建议(第4章:字符串___建议56~59)的更多相关文章
- 博友的 编写高质量代码 改善java程序的151个建议
编写高质量代码 改善java程序的151个建议 http://www.cnblogs.com/selene/category/876189.html
- 编写高质量代码改善java程序的151个建议——导航开篇
2014-05-16 09:08 by Jeff Li 前言 系列文章:[传送门] 下个星期度过这几天的奋战,会抓紧java的进阶学习.听过一句话,大哥说过,你一个月前的代码去看下,慘不忍睹是吧.确实 ...
- 编写高质量代码改善java程序的151个建议——[1-3]基础?亦是基础
原创地址: http://www.cnblogs.com/Alandre/ (泥沙砖瓦浆木匠),需要转载的,保留下! Thanks The reasonable man adapts himse ...
- 编写高质量代码:改善Java程序的151个建议 --[117~128]
编写高质量代码:改善Java程序的151个建议 --[117~128] Thread 不推荐覆写start方法 先看下Thread源码: public synchronized void start( ...
- 编写高质量代码:改善Java程序的151个建议 --[106~117]
编写高质量代码:改善Java程序的151个建议 --[106~117] 动态代理可以使代理模式更加灵活 interface Subject { // 定义一个方法 public void reques ...
- 编写高质量代码:改善Java程序的151个建议 --[78~92]
编写高质量代码:改善Java程序的151个建议 --[78~92] HashMap中的hashCode应避免冲突 多线程使用Vector或HashTable Vector是ArrayList的多线程版 ...
- 编写高质量代码:改善Java程序的151个建议 --[65~78]
编写高质量代码:改善Java程序的151个建议 --[65~78] 原始类型数组不能作为asList的输入参数,否则会引起程序逻辑混乱. public class Client65 { public ...
- 编写高质量代码:改善Java程序的151个建议 --[52~64]
编写高质量代码:改善Java程序的151个建议 --[52~64] 推荐使用String直接量赋值 Java为了避免在一个系统中大量产生String对象(为什么会大量产生,因为String字符串是程序 ...
- 编写高质量代码:改善Java程序的151个建议 --[36~51]
编写高质量代码:改善Java程序的151个建议 --[36~51] 工具类不可实例化 工具类的方法和属性都是静态的,不需要生成实例即可访 问,而且JDK也做了很好的处理,由于不希望被初始化,于是就设置 ...
- Github即将破百万的PDF:编写高质量代码改善JAVA程序的151个建议
在通往"Java技术殿堂"的路上,本书将为你指点迷津!内容全部由Java编码的最佳 实践组成,从语法.程序设计和架构.工具和框架.编码风格和编程思想等五大方面,对 Java程序员遇 ...
随机推荐
- C语言 · 4-3水仙花数
问题描述 打印所有100至999之间的水仙花数.所谓水仙花数是指满足其各位数字立方和为该数字本身的整数,例如 153=1^3+5^3+3^3. 样例输入 一个满足题目要求的输入范例.例:无 样例输出 ...
- 【翻译】MongoDB指南/CRUD操作(一)
[原文地址]https://docs.mongodb.com/manual/ MongoDB CRUD操作(一) 主要内容:CRUD操作简介,插入文档,查询文档. CRUD操作包括创建.读取.更新和删 ...
- HTML BOM Browser对象
BOM:Browser Object Model,即浏览器对象模型,提供了独立于内容的.可以与浏览器窗口进行互动的对象结构. Browser对象:指BOM提供的多个对象,包括:Window.Navig ...
- 微信小程序IDE(微信web开发者工具)安装、破解手册
1.IDE下载 微信web开发者工具,本人是用的windows 10 x64系统,用到以下两个版本的IDE安装工具与一个破解工具包: wechat_web_devtools_0.7.0_x64.exe ...
- Node.js入门
开始之前,安利一本正在看的书<站在两个世界的边缘>,作者程浩,上帝丢给他太多理想,却忘了给他完成理想的时间.OK,有兴趣的可以看一看. node.js如标题一样,我也是刚开始接触,大家一起 ...
- Html 制作相册
本文主要讲述采用Html5+jQuery+CSS 制作相册的小小记录. 主要功能点: Html5进行布局 调用jQuery(借用官网的一句话:The Write Less, Do More)极大的简化 ...
- SharePoint 2013: A feature with ID has already been installed in this farm
使用Visual Studio 2013创建一个可视web 部件,当右击项目选择"部署"时报错: "Error occurred in deployment step ' ...
- Maven(一)linux下安装
1.检查是否安装JDK,并且设置了环境变量(JAVA_HOME): echo $JAVA_HOME java -version 运行结果: 显示jdk的安装路径,和java的版本,如: #jdk路径 ...
- MSSQL 事务,视图,索引,存储过程,触发器
事务 事务是一种机制.是一种操作序列,它包含了一组数据库操作命令,这组命令要么全部执行,要么全部不执行. 在数据库系统上执行并发操作时事务是作为最小的控制单元来使用的.这特别适用于多用户同时操作的数据 ...
- 用C++实现Linux中shell的ls功能
实现输出当前目录下的文件名 ls功能: 方法一: #include <iostream> #include <algorithm> #include <stdio.h&g ...