R中的数据重塑函数
1.去除重复数据
函数:duplicated(x, incomparables = FALSE, MARGIN = 1,fromLast = FALSE, ...),返回一个布尔值向量,重复数据的第一个为FALSE,其他为TRUE。
x可以是vector或data.frame。为data.frame时,数据的基本单位是行。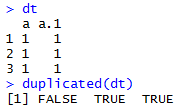
2.*apply系列
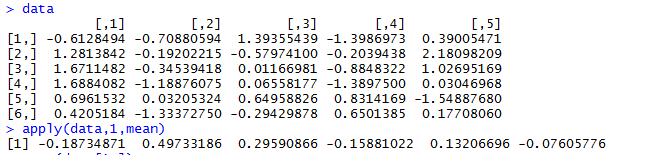
2.1以行或列为单位向函数传递参数:apply(X, MARGIN, FUN, ...),返回一个结果向量。
x是数据,可以是矩阵,数据框。margin是维度,在矩阵或数据框中,1表示行,2表示列。FUN是指定的函数。
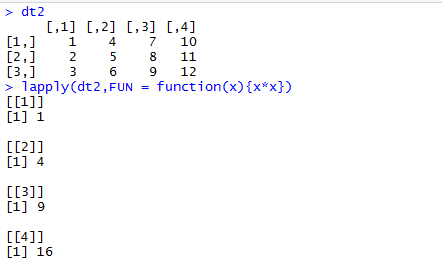
2.2对vector,list的所有元素进行同样操作:lapply(X, FUN, ...,),返回一个等长度的list
x: vector 或list,其他对象会被转换为list(as.list)
fun:对每个元素进行操作的函数
2.3 对vector,matrix,data.frame内的元素进行同样处理,sapply(X, FUN, ..., simplify = TRUE, USE.NAMES = TRUE),返回一个vector或matrix或list。
参数:
x是vector或matrix,返回vector。x是data.frame,返回matrix
simplify:结果是否简化为vector。TRUE,返回一个vector或matrix。FALSE,返回一个list。
USE.NAMES:T/F,输出的list是否需要colnames。

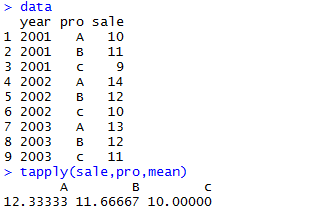
2.4 按列1分组,然后把列2作为参数传递给函数:tapply(x,index,fun,..,simplify)
x:要处理的数据列
index:要分组的数据列,要转换成factor
fun:对每组数据进行处理的函数
simplify:TRUE,返回array。FALSE,返回list
注意:tapply会自动把index的内容进行as.factor()
3.pylr包和dpylr包
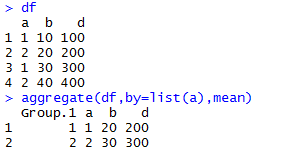
4.把数据分组,然后用指定函数对每组进行统计操作。
函数:aggregate(x,by,fun),返回一个结果数据框。
x是数据框数据。by是按什么分类的list。fun是指定的函数,接受每类的列元素。
5.因子出现的频数
函数:table(...,exclude = if (useNA == "no") c(NA, NaN),useNA = c("no", "ifany", "always"),dnn = list.names(...), deparse.level = 1),返回一个table数据。
...:因子数据
exclude:不纳入统计的因子
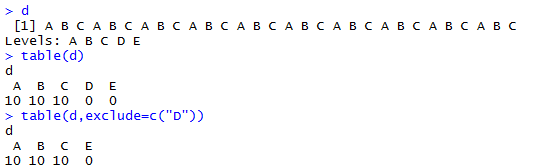
6.reshape2包
函数:melt(data, ..., na.rm = FALSE, value.name = "value")
data,要融合的数据。
by,要保留的数据列。一般说来是指能唯一确定每个测量所需的变量。
重铸melt数据,函数:dcast(data, formula, fun.aggregate = NULL, ..., margins = NULL,subset = NULL, fill = NULL, drop = TRUE,value.var = guess_value(data))
data,融合数据
formula,想要的最后结果。
fun.aggregate,数据整合函数。
其他:一些有用的小函数
| 函数 | t() | replicate() | |||||||
| 用途 | 转置矩阵和数据框 | 重复调用多次函数 | |||||||
| 用法 | t(matrix or df) | replicate((n, expr, simplify = "array") | |||||||
| 返回 | 矩阵 | 向量 |
参考:
http://blog.sina.com.cn/s/blog_6caea8bf0100xkpg.html
R中的数据重塑函数的更多相关文章
- 孤荷凌寒自学python第四十七天通用跨数据库同一数据库中复制数据表函数
孤荷凌寒自学python第四十七天通用跨数据库同一数据库中复制数据表函数 (完整学习过程屏幕记录视频地址在文末) 今天继续建构自感觉用起来顺手些的自定义模块和类的代码. 今天打算完成的是通用的(至少目 ...
- 孤荷凌寒自学python第四十八天通用同一数据库中复制数据表函数最终完成
孤荷凌寒自学python第四十八天通用同一数据库中复制数据表函数最终完成 (完整学习过程屏幕记录视频地址在文末) 今天继续建构自感觉用起来顺手些的自定义模块和类的代码. 今天经过反复折腾,最终基本上算 ...
- 在R中整理数据
原始数据一般分散杂乱,并含有缺失和错误值,因此在进行数据分析前首先要对数据进行整理. 一.首先,了解原始数据的结构. 可使用如下函数(归属baseR)来查看数据结构: class(dataobject ...
- 总结——R中查看属性的函数
本文原创,转载注明出处,本人Q1273314690 R中知道一个变量的主要内容和结构,对我们编写代码是很重要的,也可以帮我们避免很多错误. 但是,R中有好几个关于属性查看的函数,我们往往不知道什么时候 ...
- R中的apply族函数和多线程计算
一.apply族函数 1.apply 应用于矩阵和数组 # apply # 1代表行,2代表列 # create a matrix of 10 rows x 2 columns m <- ma ...
- R中的sub替换函数【转】
R中的grep.grepl.sub.gsub.regexpr.gregexpr等函数都使用正则表达式的规则进行匹配.默认是egrep的规则,也可以选用Perl语言的规则.在这里,我们以R中的sub函数 ...
- R 中的do.call 函数
do.call 函数是一个高阶函数, 其第一个参数为一个函数名,或者匿名函数,第二个参数是一个list 对象, 其实是参数列表 比如读取文件test.txt, 内容为 read.table(input ...
- 在 R 中使用 Python 字符串函数
sprintf( )函数很强大,但并非适用于所有应用场景.例如,如果一些部分在模板中多次出现,那么就需要多次写一样的参数.这通常会使得代码冗长而且难以修改:sprintf("%s, %d y ...
- C语言中的数据类型转换函数
头文件#include<stdlib.h> 1. 函数名: atof 功 能: 把字符串转换成浮点数 用 法: double atof(const char *nptr); 2.函数名: ...
随机推荐
- Win10中配置jdk之后javac无法运行
环境变量(environment variables)一般是指在操作系统中用来指定操作系统运行环境的一些参数,如:临时文件夹位置和系统文件夹位置等. 环境变量是在操作系统中一个具有特定名字的对象,它包 ...
- kmalloc、vmalloc、malloc的区别
简单的说: kmalloc和vmalloc是分配的是内核的内存,malloc分配的是用户的内存 kmalloc保证分配的内存在物理上是连续的,vmalloc保证的是在虚拟地址空间上的连续,malloc ...
- 学习php必须要了解的一些知识
前言:每个人的成功都是用辛勤的劳动换来的 一.网络的基础知识 IP地址:Internet protocol address 指的是互联网协议地址,由二进制构成,(IPV4是32位的二进制),我们人为的 ...
- python数据分析之numpy
知乎:https://zhuanlan.zhihu.com/p/26514493 numoy安装:http://blog.csdn.net/wyc12306/article/details/53705 ...
- jquery 插件 起步代码
/** * Created by W.J.Chang on 2014/6/25. */ ;(function($) { var methods= { check: function() { retur ...
- coreData笔记
1. CDVehicle *vehicle = (CDVehicle *)[[NSManagedObject alloc] initWithEntity:entity insertIntoMan ...
- VMware下安装centos6.7的步骤
一.虚拟机的创建 1.点击创建新的虚拟机(图片红框的位置) 2.选择自定义安装.下一步(根据自己的需要有选择的进行选择) 3.新装的虚拟机的版本和虚拟机兼容的产品以及这个版本的虚拟机的限制(这个窗口没 ...
- Android UI开发第二十七篇——实现左右划出菜单
年前就想写左右滑动菜单,苦于没有时间,一直拖到现在,这篇代码实现参考了网上流行的SlidingMenu,使用的FrameLayout布局,不是扩展的HorizontalScrollView. 程序中自 ...
- Coursera课程《Machine Learning》学习笔记(week1)
这是Coursera上比较火的一门机器学习课程,主讲教师为Andrew Ng.在自己看神经网络的过程中也的确发现自己有基础不牢.一些基本概念没搞清楚的问题,因此想借这门课程来个查漏补缺.目前的计划是先 ...
- solr删除数据(全删除)
背景:数据索引错了,不想要了.也不想一条条删! 方法: 1.在solr客户端,访问你的索引库(我认为最方便的方法) 1)documents type 选择 XML 2)documents 输入下面语句 ...