Hadoop 学习之MapReduce

 MapReduce充分利用了分而治之,主要就是将一个数据量比较大的作业拆分为多个小作业的框架,而用户需要做的就是决定拆成多少份,以及定义作业本身,用户所要做的操作少了又少,真是Very Good!
MapReduce充分利用了分而治之,主要就是将一个数据量比较大的作业拆分为多个小作业的框架,而用户需要做的就是决定拆成多少份,以及定义作业本身,用户所要做的操作少了又少,真是Very Good!
一.MapReduce执行流程
下面的是MapReduce的执行过程:
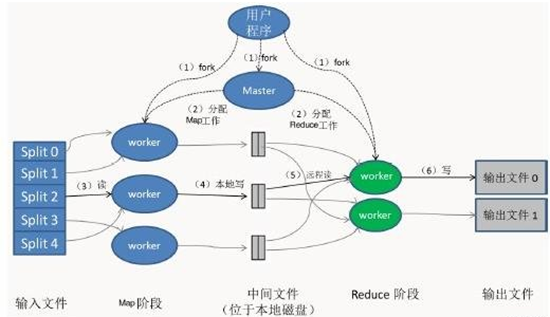
最上方的用户程序链接了底层的MapReduce库,并实现了最基本的Map函数和Reduce函数。
由用户来决定将任务划分为K块(这里设为5),假设为64MB,如图左方所示分成了split0~4(文件块);然后使用fork将用户程序拷贝到集群内其它机器上。
用户程序的副本中有一个称为Master,其余称为worker,Master是负责任务调度的,为空闲worker分配作业(Map作业或Reduce作业),worker数量可由用户指定的。
被分配了Map作业的worker,开始读取对应文件块的输入数据(包含多个map函数),从输入数据中抽取出键值对,每一个键值对都作为参数传递给map函数,map函数产生的中间键值对被缓存在内存中。
缓存的中间键值对会被定期写入本地磁盘。主控进程知道Reduce的个数,比如R个(通常用户指定)。然后主控进程通常选择一个哈希函数(一致性哈希)作用于键并产生0~R-1个桶编号。Map任务输出的每个键都被哈希起作用,根据哈希结果将Map的结果存放到R个本地文件中的一个(后来每个文件都会指派一个Reduce任务)。
master通知分配了Reduce作业的worker它负责的分区在什么位置。当Reduce worker把所有它负责的中间键值对都读过来后,先对它们进行Shuffle和排序,使得相同键的键值对聚集在一起。因为不同的键可能会映射到同一个分区也就是同一个Reduce作业(谁让分区少呢),所以排序是必须的。
reduce worker遍历排序后的中间键值对,对于每个唯一的键,都将键与关联的值传递给reduce函数,reduce函数产生的输出会添加到这个分区的输出文件中。
当所有的Map和Reduce作业都完成了,MapReduce函数调用返回用户程序的代码。
所有执行完毕后,MapReduce输出放在了R个分区的输出文件中(分别对应一个Reduce作业)。用户通常并不需要合并这R个文件,而是将其作为输入交给另一个MapReduce程序处理。整个过程中,输入数据是来自底层分布式文件系统(GFS)的,中间数据是放在本地文件系统的,最终输出数据是写入底层分布式文件系统(GFS)的。而且我们要注意Map/Reduce作业和map/reduce函数的区别:Map作业处理一个输入数据的分片,可能需要调用多次map函数来处理每个输入键值对;Reduce作业处理一个分区的中间键值对,期间要对每个不同的键调用一次reduce函数,Reduce作业最终也对应一个输出文件。
二.map函数和reduce函数
map函数和reduce函数是交给用户实现的,这两个函数定义了任务本身。
- map函数:接受一个键值对(key-value pair>),产生一组中间键值对。MapReduce框架会将map函数产生的中间键值对里键相同的值传递给一个reduce函数。
- reduce函数:接受一个键,以及相关的一组值,将这组值进行合并产生一组规模更小的值(通常只有一个或零个值)。
统计词频的MapReduce函数的核心代码非常简短,主要就是实现这两个函数。
|
1 |
map(String key, String value): reduce(String key, Iterator values): |
在统计词频的例子里,map函数接受的键是文件名,值是文件的内容,map逐个遍历单词,每遇到一个单词w,就产生一个中间键值对<w, "1">,这表示单词w咱又找到了一个。
MapReduce将键相同(都是单词w)的键值对传给reduce函数,这样reduce函数接受的键就是单词w,值是一串"1"(最基本的实现是这样,但可以优化),个数等于键为w的键值对的个数,然后将这些"1"累加就得到单词w的出现次数。最后这些单词的出现次数会被写到用户定义的位置,存储在底层的分布式存储系统(GFS或HDFS)。
三.应用举例
还是以WordCount程序为例,假设有三台DataNode,每台DataNode有不一样的数据,如下表格所示:
|
DataNode1 |
DataNode2 |
|
how do you do |
how old are you |
经过Map函数后,生成以下键值对:
|
DataNode1 |
DataNode2 |
||
|
how do you do |
1 1 1 1 |
how old are you |
1 1 1 |
然后按照key值排序,变成以下键值对:
|
DataNode1 |
DataNode2 |
||
|
do do how you |
1 1 1 1 |
are how old you |
1 1 1 |
如果有Combiner函数的话,则把相同的key进行计算;
|
DataNode1 |
DataNode2 |
||
|
do how you |
2 1 1 |
are how old you |
1 1 1 |
如果有Partition函数的话,则进行分区,分几个区就有几个Reducer同时进行运算,然后就会生成几个不一样的结果文件;默认只有一个Reducer进行工作。
这里先讲一个Reducer的情况,数据先从2个DataNode中Copy过来,然后Merge到Reducer中去:
|
Reducer |
|
|
do how you are how old you |
2 1 1 1 1 1 |
然后对数据按照key进行排序(Sort),Copy,Merge,Sort过程统称为Shuffle过程:
|
Reducer |
|
|
are do how how old you you |
1 2 1 1 1 1 |
然后数据经过Reduce函数后,生成以下输出文件:
|
Reducer |
|
|
are do how old you |
1 2 2 1 |
到这里为止,整个MapReduce过程也就完成了。
如果有多个Reducer的话,不同的是数据会分开Copy到不同的机器中,也就是分开计算,然后Copy到每个Reducer中的数据都会经过Merge,Sort,Reduce过程,最后每个Reducer都会生成一个结果文件。
Hadoop 学习之MapReduce的更多相关文章
- hadoop学习(七)----mapReduce原理以及操作过程
前面我们使用HDFS进行了相关的操作,也了解了HDFS的原理和机制,有了分布式文件系统我们如何去处理文件呢,这就的提到hadoop的第二个组成部分-MapReduce. MapReduce充分借鉴了分 ...
- Hadoop学习笔记—MapReduce的理解
我不喜欢照搬书上的东西,我觉得那样写个blog没多大意义,不如直接把那本书那一页告诉大家,来得省事.我喜欢将我自己的理解.所以我会说说我对于Hadoop对大量数据进行处理的理解.如果有理解不对欢迎批评 ...
- Hadoop学习之Mapreduce执行过程详解
一.MapReduce执行过程 MapReduce运行时,首先通过Map读取HDFS中的数据,然后经过拆分,将每个文件中的每行数据分拆成键值对,最后输出作为Reduce的输入,大体执行流程如下图所示: ...
- 【尚学堂·Hadoop学习】MapReduce案例2--好友推荐
案例描述 根据好友列表,推荐好友的好友 数据集 tom hello hadoop cat world hadoop hello hive cat tom hive mr hive hello hive ...
- 【尚学堂·Hadoop学习】MapReduce案例1--天气
案例描述 找出每个月气温最高的2天 数据集 -- :: 34c -- :: 38c -- :: 36c -- :: 32c -- :: 37c -- :: 23c -- :: 41c -- :: 27 ...
- hadoop学习day3 mapreduce笔记
1.对于要处理的文件集合会根据设定大小将文件分块,每个文件分成多块,不是把所有文件合并再根据大小分块,每个文件的最后一块都可能比设定的大小要小 块大小128m a.txt 120m 1个块 b.txt ...
- Hadoop学习(3)-mapreduce快速入门加yarn的安装
mapreduce是一个运算框架,让多台机器进行并行进行运算, 他把所有的计算都分为两个阶段,一个是map阶段,一个是reduce阶段 map阶段:读取hdfs中的文件,分给多个机器上的maptask ...
- Hadoop学习(4)-mapreduce的一些注意事项
关于mapreduce的一些注意细节 如果把mapreduce程序打包放到了liux下去运行, 命令java –cp xxx.jar 主类名 如果报错了,说明是缺少相关的依赖jar包 用命令had ...
- Hadoop学习之旅三:MapReduce
MapReduce编程模型 在Google的一篇重要的论文MapReduce: Simplified Data Processing on Large Clusters中提到,Google公司有大量的 ...
随机推荐
- 模块导入应用settings的字符串
看django源码,感觉他的settings好高大上然后自己试试 以上是文件目录 email.py中代码 class Email: def send(self): print('发送email') M ...
- 一笔画问题 南阳acm42(貌似没用到什么算法)
一笔画问题 时间限制:3000 ms | 内存限制:65535 KB 难度:4 描述 zyc从小就比较喜欢玩一些小游戏,其中就包括画一笔画,他想请你帮他写一个程序,判断一个图是否能够用一笔画下 ...
- 002---Linux系统目录结构
Linux系统目录结构 一切从根(/)开始,一切皆文件. /bin:存放常用的可执行文件 /sbin:存放常用的可执行文件 家目录:存放用户自己的文件或目录 root用户:/root 普通用户:/ho ...
- 004---基于TCP的套接字
基于TCP的套接字 tcp是基于链接的,必须先启动服务端,然后再启动客户端去连接服务端. 之前实现的简单套接字就是基于TCP的,但是只能实现收发消息一次.服务器与客户端都断开了.不够过瘾. 通信循环版 ...
- javaWeb总结
url传值时:如out.println("<td><a href = 'delete.jsp?user=" + user + "'>删除</ ...
- SQL 公用表表达式(CTE)
1.概念 公用表表达式(Common Table Expression)是SQL SERVER 2005版本之后引入的一个特性.CTE可以看作是一个临时的结果集,可以在接下来的一个SELECT,INS ...
- jsp中的input
Input表示Form表单中的一种输入对象,其又随Type类型的不同而分文本输入框,密码输入框,单选/复选框,提交/重置按钮等,下面一一介绍. 1,type=text 输入类型是text,这是我们见的 ...
- ORB-SLAM (四)tracking单目初始化
单目初始化以及通过三角化恢复出地图点 单目的初始化有专门的初始化器,只有连续的两帧特征点均>100个才能够成功构建初始化器. ); 若成功获取满足特征点匹配条件的连续两帧,并行计算分解基础矩阵和 ...
- [网站公告]18:07-18:20阿里云SLB故障造成网站不能正常访问
(注:由于阿里云SLB管理控制台监控数据不准,实际故障时间是18:07-18:20.) 17:55-18:2018:07-18:20,我们使用的阿里云SLB(负载均衡)中有3台出现突发故障,造成全站无 ...
- Markdown常用的几种语法
在VScode上面写的,现将代码粘贴如下:(在VScode里运行下即可) # Markdown语法 # Ctrl + k v 打开侧边预览 ## 一.加粗斜体删除线 **这是要加粗的文字** *这是要 ...