scrapy保存csv文件有空行的解决方案
比如现在我有一个名为test的爬虫,运行爬虫后将结果保存到test.csv文件
默认情况下,我执行scrapy crawl test -o test.csv ,得到的结果可能就是下面这种情况,每两行中间都会有一个空行
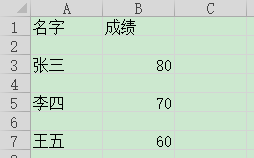
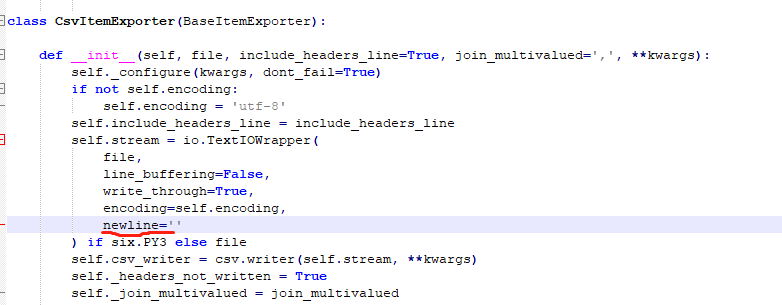
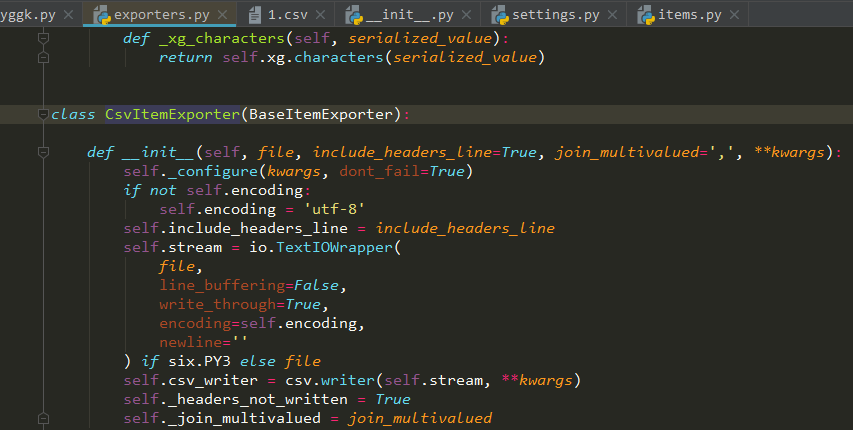
解决方法是修改scrapy的源码,具体就是 io.TextIOWrapper 里面添加一行newline=‘’
找到这个源码具体方法:
方法一:找到python安装路径里面scrapy文件夹,exporters.py文件,使用notepad++等文本编辑器打开
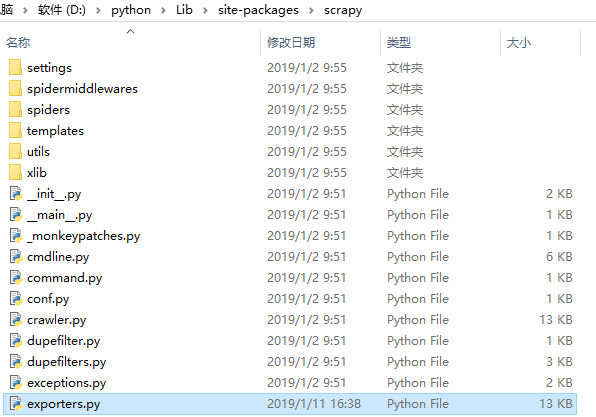
然后修改如下,保存即可。
方法二:使用pycharm来修改源码
随便找个文件,然后导入CsvItemExporter
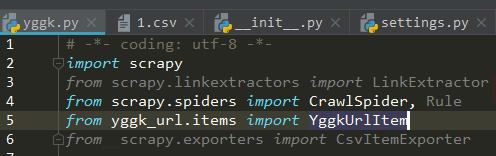
按住ctrl,同时点击CsvItemExporter字样,跳转到源码。按照之前的方法修改就可以了。
scrapy保存csv文件有空行的解决方案的更多相关文章
- scrapy生成csv文件空行、csv文件打开乱码(解决方案)
一.scrapy生成csv文件会有多余的空行 当使用scrapy crawl testspider -o test.csv后,生成的默认csv文件每一行之间是有空行的,解决的方法是修改scrapy的源 ...
- Python3使用csv模块csv.writer().writerow()保存csv文件,产生空行的问题
问题:csv.writer().writerow()保存的csv文件,打开时每行后都多一行空行 解决方法:在open()内增加一个参数newline='' 即可 问题现象: 1.代码 with ...
- 通过TStringList保存csv文件,只要循环.Add表格里面的每行记录进去,保存即可
dlgSave := TSaveDialog.Create(nil); dlgSave.filter := 'CSV文件|*.CSV'; dlgSave.DefaultExt := '*.CSV'; ...
- python 保存csv文件
利用pandas库, 将numpy的array数据保存成csv格式的文件: import pandas as pd import numpy as np data = pd.read_csv('C:\ ...
- C#导出csv文件 支持中文的解决方案
#region 导出CSV下载 string exportFileName = "Export" + DateTime.Now.ToString("yyyyMMddHHm ...
- [解决问题] pandas读取csv文件报错OSError解决方案
python用padans.csv_read函数出现OSError: Initializing from file failed 问题:文件路径中存在中文 解决办法:修改文件路径名为全英文包括文件名
- Jmeter接口自动化实例(使用Beanshell保存csv文件、csv参数化、setUp线程组)
很久没更新博客了,荒废了很久了,今天更新一下博客,主要记录一下子最近遇到的问题和解决方法:blonde_woman: 这篇文章主要记录的是jmeter批量跑接口中遇到的各种疑难,主要涉及到的问题如下 ...
- 爬虫系列:存储 CSV 文件
上一期:爬虫系列:存储媒体文件,讲解了如果通过爬虫下载媒体文件,以及下载媒体文件相关代码讲解. 本期将讲解如果将数据保存到 CSV 文件. 逗号分隔值(Comma-Separated Values,C ...
- 利用a标签导出csv文件
原文 简书原文:https://www.jianshu.com/p/a8687610cda3 大纲 1.需求分析 2.通过a标签实现文件导出 3.实现方式 1.需求分析 导出文件,使用最多的方式还是服 ...
随机推荐
- checkbox选择根据后台List数据进行回显
需求:记住用户已经选择的 checkbox 选项,当用户再次对该 checkbox 进行选择操作时,应对该用户已经选择的 checkbox 选项进行选中操作. 示例代码: checkbox,js遍历后 ...
- SSM框架使用-wrong
mybatis手册 1. mybatis 绑定错误 如果出现: org.apache.ibatis.binding.BindingException: Invalid bound statement ...
- gcd的性质+分块 Bzoj 4028
4028: [HEOI2015]公约数数列 Time Limit: 10 Sec Memory Limit: 256 MBSubmit: 865 Solved: 311[Submit][Statu ...
- JVM学习三:JVM之类加载器之连接分析
学习完类加载之加载篇后,让我们继续来看加载之连接,连接分为三个步骤:验证.准备和解析三步,我们将一一分析之. 连接就是将已经读入到内存的类的二进制数据合并到虚拟机的运行时环境中去. 类加载完毕之后进入 ...
- 使用FormData提交表单及上传文件
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN"> <html> <head ...
- Shiro实战教程(二)
http://www.jianshu.com/p/6786ddf54582/ https://www.cnblogs.com/ealenxie/p/10610741.html
- Java 里快如闪电的线程间通讯
这个故事源自一个很简单的想法:创建一个对开发人员友好的.简单轻量的线程间通讯框架,完全不用锁.同步器.信号量.等待和通知,在Java里开发一个轻量.无锁的线程内通讯框架:并且也没有队列.消息.事件或任 ...
- 怎样用javascript关闭本窗口
大家都知道window.close()是用来关闭窗口的,而且ie和firefox都是支持的. 为了实现用户对浏览器的绝对控制,ie中用close关闭非open打开的窗口时回弹出一个对话框询问用户,怎么 ...
- linux平台 PHP 实现 word转pdf的艰难历程...
1.网上搜索资料 无非是 openoffice + PHP的com组件 然而试了很多次 都不可靠 2.后来找到 openoffice + jodconverter(需java环境) 一.安装openo ...
- npm install ERR! code E400/E404
在安装webpack的过程中,出现了一个报错npm install ERR! code E400/E404 解决方法: 1.查看npm配置文件 是否有错误: 执行 npm config edit 查看 ...