Flink资料(3)-- Flink一般架构和处理模型
Flink一般架构和处理模型
本文翻译自General Architecture and Process Model
---------------------------------------------------------------------
一、处理过程
当Flink系统启动时,首先启动JobManager和一至多个TaskManager。JobManager负责协调Flink系统,TaskManager则是执行并行程序的worker。当系统以本地形式启动时,一个JobManager和一个TaskManager会启动在同一个JVM中。
当一个程序被提交后,系统会创建一个Client来进行预处理,将程序转变成一个并行数据流的(parallel data flow)形式,交给JobManager和TaskManager执行。图1展示了在系统交互中各个组件的角色。

图1Flink运行时各组件关系
二、组件栈(Component Stack)
Flink以层级式系统形式组件其软件栈,不同层的栈建立在其下层基础上,并且各层接受程序不同层的抽象形式:
o 运行时层以JobGraph形式接收程序。JobGraph即为一个一般化的并行数据流图(data flow),它拥有任意数量的Task来接收和产生data stream
o DataStream API和DataSet API都会使用单独编译的处理方式(Separate compilation process)生成JobGraph。DataSet API使用Optimizer来决定针对程序的优化方法,而DataStream API则使用stream builder来完成该任务。
o 在执行JobGraph时,Flink提供了多种候选部署方案(如local,remote,YARN等)
o Flink附随了一些产生DataSet或DataStream API程序的的类库和API:处理逻辑表查询的Table,机器学习的FlinkML,图像处理的Gelly,事件处理的CEP

图2Flink组件栈
三、工程和依赖
Flink系统核心可分为多个子项目。分割项目旨在减少开发Flink程序需要的依赖数量,并对测试和开发小组件提供便捷。
独立的工程和依赖关系如图3所示
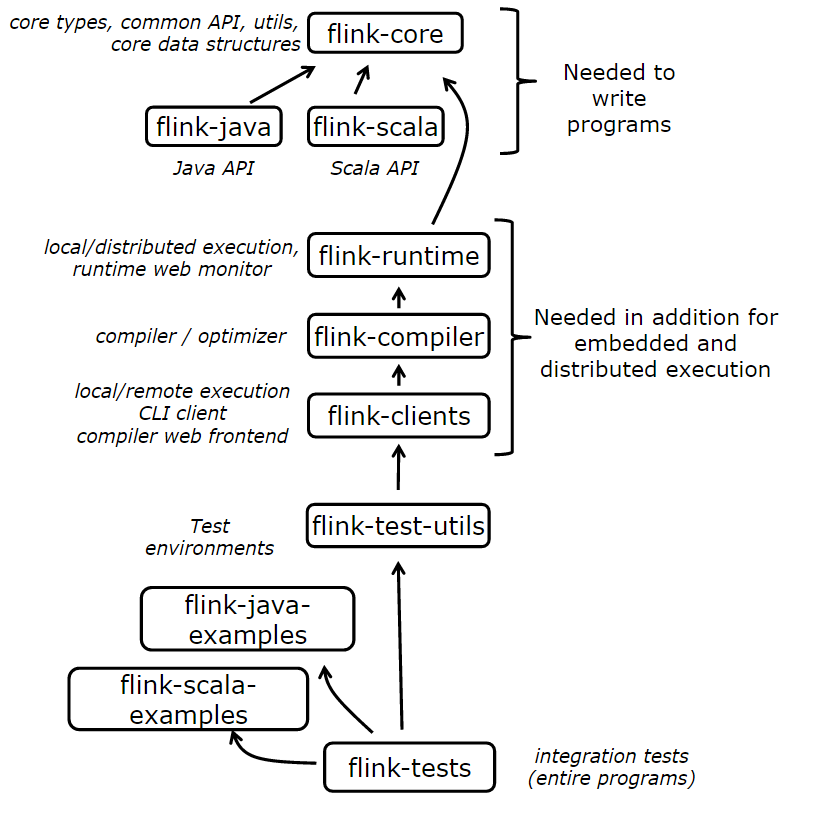
图3Flink子项目和依赖关系
此外,除了图3列出的项目,Flink当前还包括以下子项目:
o Flink-dist:distribution项目。它定义了如何将编译后的代码、脚本和其他资源整合到最终可用的目录结构中。
o Flink-quick-start:有关quickstart和教程的脚本、maven原型和示例程序
o flink-contrib:一系列有用户开发的早起版本和有用的工具的项目。后期的代码主要由外部贡献者继续维护,被flink-contirb接受的代码的要求低于其他项目的要求。
Flink资料(3)-- Flink一般架构和处理模型的更多相关文章
- 第01讲:Flink 的应用场景和架构模型
你好,欢迎来到第 01 课时,本课时我们主要介绍 Flink 的应用场景和架构模型. 实时计算最好的时代 在过去的十年里,面向数据时代的实时计算技术接踵而至.从我们最初认识的 Storm,再到 Spa ...
- Flink的应用场景和架构
Flink的应用场景 Flink项目的理念就是:Flink是为分布式,高性能,随时可用以及准确的流处理应用程序打造的开源流处理框架.自2019年开源以来,迅速成为大数据实时计算领域炙手可热的技术框架. ...
- 《从0到1学习Flink》—— Apache Flink 介绍
前言 Flink 是一种流式计算框架,为什么我会接触到 Flink 呢?因为我目前在负责的是监控平台的告警部分,负责采集到的监控数据会直接往 kafka 里塞,然后告警这边需要从 kafka topi ...
- 《从0到1学习Flink》—— 介绍Flink中的Stream Windows
前言 目前有许多数据分析的场景从批处理到流处理的演变, 虽然可以将批处理作为流处理的特殊情况来处理,但是分析无穷集的流数据通常需要思维方式的转变并且具有其自己的术语(例如,"windowin ...
- Flink初探-为什么选择Flink
本文主要记录一些关于Flink与storm,spark的区别, 优势, 劣势, 以及为什么这么多公司都转向Flink. What Is Flink 一个通俗易懂的概念: Apache Flink 是近 ...
- 8、Flink Table API & Flink Sql API
一.概述 上图是flink的分层模型,Table API 和 SQL 处于最顶端,是 Flink 提供的高级 API 操作.Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时 ...
- hadoop之Spark强有力竞争者Flink,Spark与Flink:对比与分析
hadoop之Spark强有力竞争者Flink,Spark与Flink:对比与分析 Spark是一种快速.通用的计算集群系统,Spark提出的最主要抽象概念是弹性分布式数据集(RDD),它是一个元素集 ...
- flink部署操作-flink standalone集群安装部署
flink集群安装部署 standalone集群模式 必须依赖 必须的软件 JAVA_HOME配置 flink安装 配置flink 启动flink 添加Jobmanager/taskmanager 实 ...
- Flink学习笔记:Flink开发环境搭建
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
随机推荐
- HTML——表格与表单
1.表格 <table></table> background:背景图片. 属性 值 描述 align left center right 不赞成使用.请使用样式代替. 规定表 ...
- Linux自制离线源,利用百度网盘等下载离线资源
CentOS安装Axel: 目前yum源上没有Axel,我们可以到http://pkgs.repoforge.org/axel/下载rpm包安装. 32位CentOS执行下面命令: wget -c h ...
- TCP/IP详解之:UDP协议
第11章 UDP协议 UDP首部 UDP的检验和是可选的,而TCP的检验和是必须的: UDP的检验和是端到端的检验和.由发送端计算,由接收端验证: 尽管UDP的检验和是可选的,但总是推荐被使用 IP ...
- nginx 学习笔记【持续更新...】
1.如果在安装过程中出现以下错误 需要安装pcre库 解决方案:yum install pcre 2.如果nginx启动提示端口被占用,则停止该端口的服务再启动nginx,一般为httpd服务 解决方 ...
- Android ListView滑动底部自动加载更多
直接上代码: // lv = (ListView) findViewById(R.id.lv); // // for(int i = 0;i < 50;i++){ // ls.add(" ...
- js获取时间和日期,字符串和时间戳之间的转换
//获取当前时间: var myDate = new Date();//当前时间 var year = myDate.getFullYear();//当前年份 var month = myDate.g ...
- hdu 5126 stars cdq分治套cdq分治+树状数组
题目链接 给n个操作, 第一种是在x, y, z这个点+1. 第二种询问(x1, y1, z1). (x2, y2, z2)之间的总值. 用一次cdq分治可以将三维变两维, 两次的话就变成一维了, 然 ...
- MySQL----alter table modify | change的不同
1.modify.change都可以修改列的属性:一同的是modify只能修改表的数据类型.change比它要牛逼一点它可以在修改数据类型的同时也修改列名. 2.modify 的语法:alter ta ...
- tracker-store and tracker-miner-fs eating up my CPU on every startup
Tracker is a synergy of technologies that are designed to provide a highly sophisticated, innovative ...
- ajax跨域请求的方案
$.get("@Hosts.Default.Www/api/XXXXX/Getxxx/"+@Model.UserId, function(data) { $("#tota ...