高性能IO模型浅析(彩图解释)good
服务器端编程经常需要构造高性能的IO模型,常见的IO模型有四种:
(1)同步阻塞IO(Blocking IO):即传统的IO模型。
(2)同步非阻塞IO(Non-blocking IO):默认创建的socket都是阻塞的,非阻塞IO要求socket被设置为NONBLOCK。注意这里所说的NIO并非Java的NIO(New IO)库。
(3)IO多路复用(IO Multiplexing):即经典的Reactor设计模式,有时也称为异步阻塞IO,Java中的Selector和Linux中的epoll都是这种模型。
(4)异步IO(Asynchronous IO):即经典的Proactor设计模式,也称为异步非阻塞IO。
同步和异步的概念描述的是用户线程与内核的交互方式:同步是指用户线程发起IO请求后需要等待或者轮询内核IO操作完成后才能继续执行;而异步是指用户线程发起IO请求后仍继续执行,当内核IO操作完成后会通知用户线程,或者调用用户线程注册的回调函数。
阻塞和非阻塞的概念描述的是用户线程调用内核IO操作的方式:阻塞是指IO操作需要彻底完成后才返回到用户空间;而非阻塞是指IO操作被调用后立即返回给用户一个状态值,无需等到IO操作彻底完成。
另外,Richard Stevens 在《Unix 网络编程》卷1中提到的基于信号驱动的IO(Signal Driven IO)模型,由于该模型并不常用,本文不作涉及。接下来,我们详细分析四种常见的IO模型的实现原理。为了方便描述,我们统一使用IO的读操作作为示例。
一、同步阻塞IO
同步阻塞IO模型是最简单的IO模型,用户线程在内核进行IO操作时被阻塞。

图1 同步阻塞IO
如图1所示,用户线程通过系统调用read发起IO读操作,由用户空间转到内核空间。内核等到数据包到达后,然后将接收的数据拷贝到用户空间,完成read操作。
用户线程使用同步阻塞IO模型的伪代码描述为:

{
read(socket, buffer);
process(buffer);
}
即用户需要等待read将socket中的数据读取到buffer后,才继续处理接收的数据。整个IO请求的过程中,用户线程是被阻塞的,这导致用户在发起IO请求时,不能做任何事情,对CPU的资源利用率不够。
二、同步非阻塞IO
同步非阻塞IO是在同步阻塞IO的基础上,将socket设置为NONBLOCK。这样做用户线程可以在发起IO请求后可以立即返回。

图2 同步非阻塞IO
如图2所示,由于socket是非阻塞的方式,因此用户线程发起IO请求时立即返回。但并未读取到任何数据,用户线程需要不断地发起IO请求,直到数据到达后,才真正读取到数据,继续执行。
用户线程使用同步非阻塞IO模型的伪代码描述为:
{
while(read(socket, buffer) != SUCCESS)
;
process(buffer);
}
即用户需要不断地调用read,尝试读取socket中的数据,直到读取成功后,才继续处理接收的数据。整个IO请求的过程中,虽然用户线程每次发起IO请求后可以立即返回,但是为了等到数据,仍需要不断地轮询、重复请求,消耗了大量的CPU的资源。一般很少直接使用这种模型,而是在其他IO模型中使用非阻塞IO这一特性。
三、IO多路复用
IO多路复用模型是建立在内核提供的多路分离函数select基础之上的,使用select函数可以避免同步非阻塞IO模型中轮询等待的问题。

图3 多路分离函数select
如图3所示,用户首先将需要进行IO操作的socket添加到select中,然后阻塞等待select系统调用返回。当数据到达时,socket被激活,select函数返回。用户线程正式发起read请求,读取数据并继续执行。
从流程上来看,使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数的额外操作,效率更差。但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注册多个socket,然后不断地调用select读取被激活的socket,即可达到在同一个线程内同时处理多个IO请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
用户线程使用select函数的伪代码描述为:
{
select(socket);
while(1) {
sockets = select();
for(socket in sockets) {
if(can_read(socket)) {
read(socket, buffer);
process(buffer);
}
}
}
}
其中while循环前将socket添加到select监视中,然后在while内一直调用select获取被激活的socket,一旦socket可读,便调用read函数将socket中的数据读取出来。
然而,使用select函数的优点并不仅限于此。虽然上述方式允许单线程内处理多个IO请求,但是每个IO请求的过程还是阻塞的(在select函数上阻塞),平均时间甚至比同步阻塞IO模型还要长。如果用户线程只注册自己感兴趣的socket或者IO请求,然后去做自己的事情,等到数据到来时再进行处理,则可以提高CPU的利用率。
IO多路复用模型使用了Reactor设计模式实现了这一机制。

图4 Reactor设计模式
如图4所示,EventHandler抽象类表示IO事件处理器,它拥有IO文件句柄Handle(通过get_handle获取),以及对Handle的操作handle_event(读/写等)。继承于EventHandler的子类可以对事件处理器的行为进行定制。Reactor类用于管理EventHandler(注册、删除等),并使用handle_events实现事件循环,不断调用同步事件多路分离器(一般是内核)的多路分离函数select,只要某个文件句柄被激活(可读/写等),select就返回(阻塞),handle_events就会调用与文件句柄关联的事件处理器的handle_event进行相关操作。
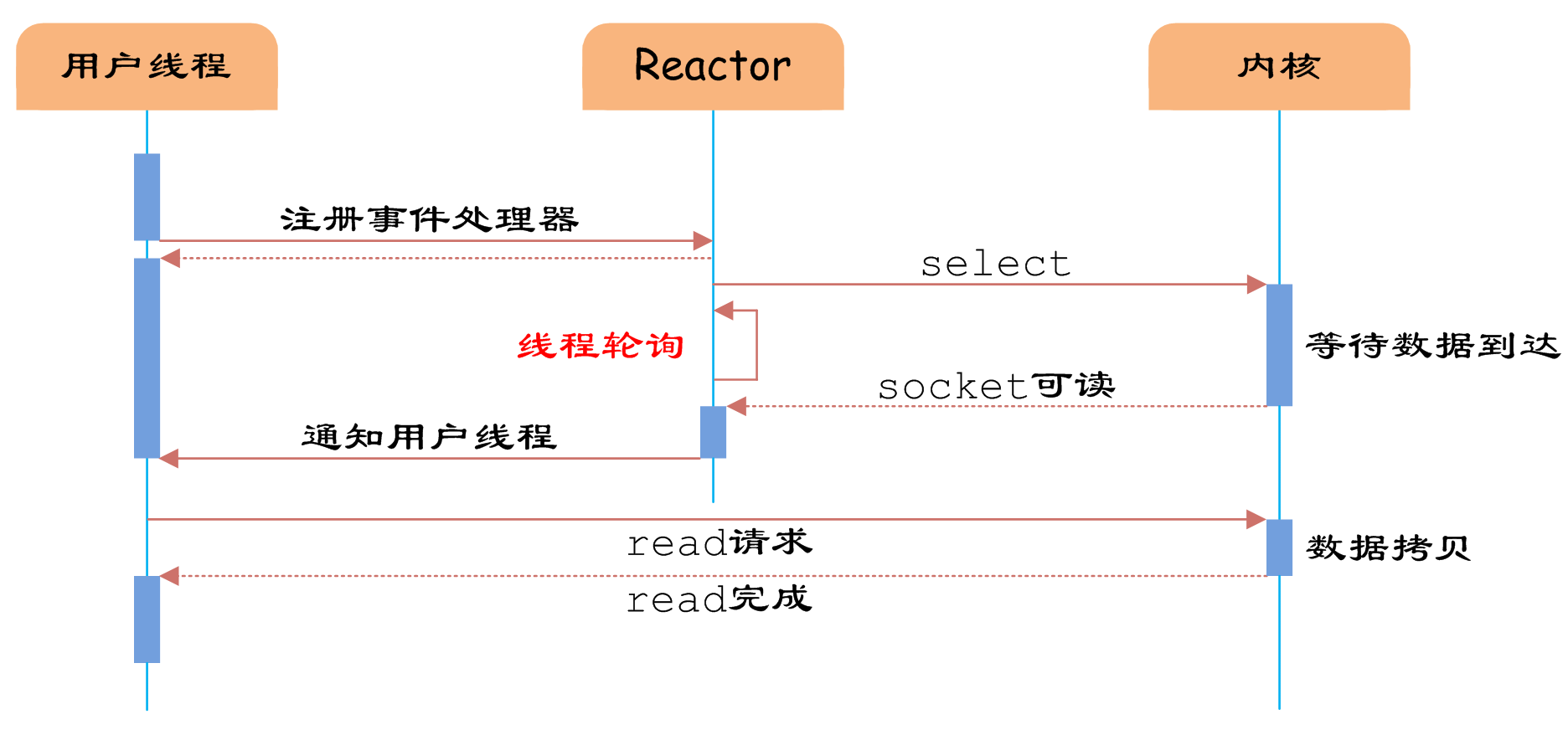
图5 IO多路复用
如图5所示,通过Reactor的方式,可以将用户线程轮询IO操作状态的工作统一交给handle_events事件循环进行处理。用户线程注册事件处理器之后可以继续执行做其他的工作(异步),而Reactor线程负责调用内核的select函数检查socket状态。当有socket被激活时,则通知相应的用户线程(或执行用户线程的回调函数),执行handle_event进行数据读取、处理的工作。由于select函数是阻塞的,因此多路IO复用模型也被称为异步阻塞IO模型。注意,这里的所说的阻塞是指select函数执行时线程被阻塞,而不是指socket。一般在使用IO多路复用模型时,socket都是设置为NONBLOCK的,不过这并不会产生影响,因为用户发起IO请求时,数据已经到达了,用户线程一定不会被阻塞。
用户线程使用IO多路复用模型的伪代码描述为:
void UserEventHandler::handle_event() {
if(can_read(socket)) {
read(socket, buffer);
process(buffer);
}
}
{
Reactor.register(new UserEventHandler(socket));
}
用户需要重写EventHandler的handle_event函数进行读取数据、处理数据的工作,用户线程只需要将自己的EventHandler注册到Reactor即可。Reactor中handle_events事件循环的伪代码大致如下。
Reactor::handle_events() {
while(1) {
sockets = select();
for(socket in sockets) {
get_event_handler(socket).handle_event();
}
}
}
事件循环不断地调用select获取被激活的socket,然后根据获取socket对应的EventHandler,执行器handle_event函数即可。
IO多路复用是最常使用的IO模型,但是其异步程度还不够“彻底”,因为它使用了会阻塞线程的select系统调用。因此IO多路复用只能称为异步阻塞IO,而非真正的异步IO。
四、异步IO
“真正”的异步IO需要操作系统更强的支持。在IO多路复用模型中,事件循环将文件句柄的状态事件通知给用户线程,由用户线程自行读取数据、处理数据。而在异步IO模型中,当用户线程收到通知时,数据已经被内核读取完毕,并放在了用户线程指定的缓冲区内,内核在IO完成后通知用户线程直接使用即可。
异步IO模型使用了Proactor设计模式实现了这一机制。

图6 Proactor设计模式
如图6,Proactor模式和Reactor模式在结构上比较相似,不过在用户(Client)使用方式上差别较大。Reactor模式中,用户线程通过向Reactor对象注册感兴趣的事件监听,然后事件触发时调用事件处理函数。而Proactor模式中,用户线程将AsynchronousOperation(读/写等)、Proactor以及操作完成时的CompletionHandler注册到AsynchronousOperationProcessor。AsynchronousOperationProcessor使用Facade模式提供了一组异步操作API(读/写等)供用户使用,当用户线程调用异步API后,便继续执行自己的任务。AsynchronousOperationProcessor 会开启独立的内核线程执行异步操作,实现真正的异步。当异步IO操作完成时,AsynchronousOperationProcessor将用户线程与AsynchronousOperation一起注册的Proactor和CompletionHandler取出,然后将CompletionHandler与IO操作的结果数据一起转发给Proactor,Proactor负责回调每一个异步操作的事件完成处理函数handle_event。虽然Proactor模式中每个异步操作都可以绑定一个Proactor对象,但是一般在操作系统中,Proactor被实现为Singleton模式,以便于集中化分发操作完成事件。
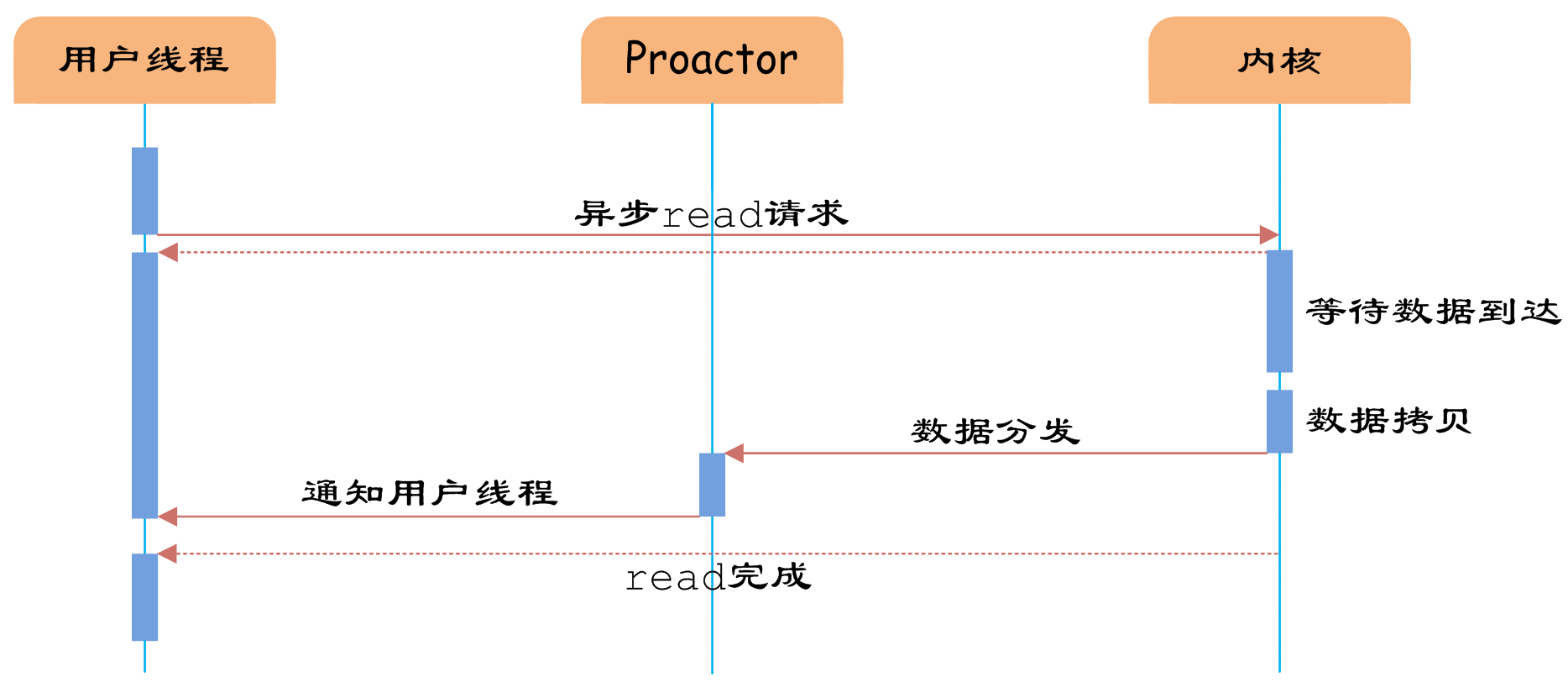
图7 异步IO
如图7所示,异步IO模型中,用户线程直接使用内核提供的异步IO API发起read请求,且发起后立即返回,继续执行用户线程代码。不过此时用户线程已经将调用的AsynchronousOperation和CompletionHandler注册到内核,然后操作系统开启独立的内核线程去处理IO操作。当read请求的数据到达时,由内核负责读取socket中的数据,并写入用户指定的缓冲区中。最后内核将read的数据和用户线程注册的CompletionHandler分发给内部Proactor,Proactor将IO完成的信息通知给用户线程(一般通过调用用户线程注册的完成事件处理函数),完成异步IO。
用户线程使用异步IO模型的伪代码描述为:
void UserCompletionHandler::handle_event(buffer) {
process(buffer);
}
{
aio_read(socket, new UserCompletionHandler);
}
用户需要重写CompletionHandler的handle_event函数进行处理数据的工作,参数buffer表示Proactor已经准备好的数据,用户线程直接调用内核提供的异步IO API,并将重写的CompletionHandler注册即可。
相比于IO多路复用模型,异步IO并不十分常用,不少高性能并发服务程序使用IO多路复用模型+多线程任务处理的架构基本可以满足需求。况且目前操作系统对异步IO的支持并非特别完善,更多的是采用IO多路复用模型模拟异步IO的方式(IO事件触发时不直接通知用户线程,而是将数据读写完毕后放到用户指定的缓冲区中)。Java7之后已经支持了异步IO,感兴趣的读者可以尝试使用。
本文从基本概念、工作流程和代码示例三个层次简要描述了常见的四种高性能IO模型的结构和原理,理清了同步、异步、阻塞、非阻塞这些容易混淆的概念。通过对高性能IO模型的理解,可以在服务端程序的开发中选择更符合实际业务特点的IO模型,提高服务质量。希望本文对你有所帮助。
转载自:http://www.cnblogs.com/fanzhidongyzby/p/4098546.html
http://www.cnblogs.com/xufeiyang/articles/5010717.html
高性能IO模型浅析(彩图解释)good的更多相关文章
- 高性能IO模型浅析
高性能IO模型浅析 服务器端编程经常需要构造高性能的IO模型,常见的IO模型有四种: (1)同步阻塞IO(Blocking IO):即传统的IO模型. (2)同步非阻塞IO(Non-blocking ...
- 转 高性能IO模型浅析
高性能IO模型浅析 转自:http://www.cnblogs.com/fanzhidongyzby/p/4098546.html 服务器端编程经常需要构造高性能的IO模型,常见的IO模型有四种: ( ...
- 高性能IO模型浅析(转)
转自:http://www.cnblogs.com/fanzhidongyzby/p/4098546.html 是我目前看到的解释IO模型最清晰的文章,当然啦,如果想要详细的进一步了解还是继续啃蓝宝书 ...
- 【珍藏】高性能IO模型浅析
服务器端编程经常需要构造高性能的IO模型,常见的IO模型有四种: (1)同步阻塞IO(Blocking IO):即传统的IO模型. (2)同步非阻塞IO(Non-blocking IO):默认创建的s ...
- [转载] 高性能IO模型浅析
转载自http://www.cnblogs.com/fanzhidongyzby/p/4098546.html 服务器端编程经常需要构造高性能的IO模型,常见的IO模型有四种: (1)同步阻塞IO(B ...
- 【转载】高性能IO模型浅析
服务器端编程经常需要构造高性能的IO模型,常见的IO模型有四种: (1)同步阻塞IO(Blocking IO):即传统的IO模型. (2)同步非阻塞IO(Non-blocking IO):默认创建的s ...
- Redis基础篇(二)高性能IO模型
我们经常听到说Redis是单线程的,也会有疑问:为什么单线程的Redis能那么快? 这里要明白一点:Redis是单线程,主要是指Redis的网络IO和键值对读写是由一个线程来完成的,这也是Redis对 ...
- 03 高性能IO模型:采用多路复用机制的“单线程”Redis
本篇重点 三个问题: "Redis真的只有单线程吗?""为什么用单线程?""单线程为什么这么快?" "Redis真的只有单线程吗? ...
- unix io 模型浅析
POSIX中对同步IO和异步IO的规定: 同步IO操作:引起进程的阻塞直到IO操作完成,异步IO操作:IO操作不会引起进程阻塞 在UNIX下,有5中操作模型: 阻塞IO,非阻塞IO,IO复用,信号驱动 ...
随机推荐
- iPhone 真机调试应用程序
原文:http://blog.sina.com.cn/s/blog_68e753f70100r3w5.html 真机调试iphone应用程序 1.真机调试流程概述 1) 真机调试应用程序, ...
- [译]MDX 介绍
关于MDX MDX (Multi Dimensional eXpression language) 是非常强大的工具,可以将你的多维数据库/cube 发挥到极致. 本文会覆盖MDX基础,并且希望能使你 ...
- linux下操作gpio寄存器的方法
一. 在驱动中: 1. 用的时候映射端口:ioremap; #define GPIO_OFT(x) ((x) - 0x56000000) #define GPFCON (*(volatile unsi ...
- PHP自练项目之发送短信内容
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- net core 静态文件
asp.net core 之静态文件目录的操作 文章前言 之前写了一篇关于模拟登录的文章,自我感觉内容不太丰富,今天的这篇文章,希望在内容上能丰富些.本人缺少写文章的经验,技术上也是新手,但我会努 ...
- Hdu 3371 Connect the Cities(最小生成树)
地址:http://acm.hdu.edu.cn/showproblem.php?pid=3371 其实就是最小生成树,但是这其中有值得注意的地方:就是重边.题目没有告诉你两个城市之间只有一条路可走, ...
- JS判断只能是数字和小数点
JS判断只能是数字和小数点 1.文本框只能输入数字代码(小数点也不能输入) <input onkeyup="this.value=this.value.replace(/\D/g,'' ...
- AlertDialog具体解释
对话框介绍与演示样例 对话框在程序中不是必备的,可是用好对话框能对我们编写的应用增色不少.採用对话框能够大大添加应用的友好性.比較经常使用的背景是:用户登陆.网络正在下载.下载成功或者 ...
- linq中的临时变量
有一个字符串数组: string[]arrStr={"123","234","345","456"}; 现在想得到该数组 ...
- python字符串方法以及注释
转自fishC论坛:http://bbs.fishc.com/forum.php?mod=viewthread&tid=38992&extra=page%3D1%26filter%3D ...