依图在实时音视频中语音处理的挑战丨RTC Dev Meetup
前言
「语音处理」是实时互动领域中非常重要的一个场景,在声网发起的「RTC Dev Meetup丨语音处理在实时互动领域的技术实践和应用」 活动中,来自百度、寰宇科技和依图的技术专家,围绕该话题进行了相关分享。
本文基于依图 AI SaaS 技术负责人周元剑在活动中分享内容整理。
依图是一家做 AI 基础设施和 AI 解决方案的提供商,拥有的 AI 技术能力相对比较广泛,包括图片、视频、语音、自然语言处理等,除具备 AI 算法能力外,也能提供 AI 算力。
大家了解依图的背景后,我来说下依图在直播场景下遇到的与音频内容审核相关的挑战。
01 直播内容审核的业务流程
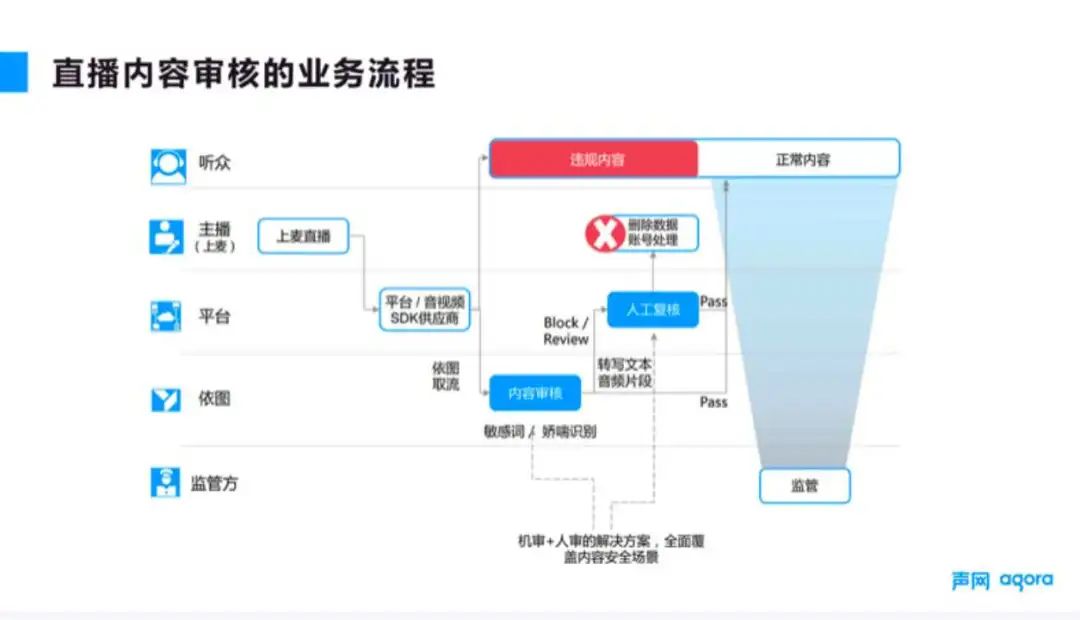
■图 1
图 1 展示了直播场景下内容审核的业务流程。
基本过程是:主播先上麦直播,然后流就会被推送到平台,平台将审核请求发给供应商,审核的供应商(比如依图)通过地址获取流,并对其进行解码,实时分析找出违规的内容,再通过回调形式把数据返回给客户。客户收到数据后,一般需要进行二次的人工复核,如果确认是违规内容,那么就会进行后台处理,比如停止直播或者删除账号等。
02 直播音频审核算法模块
将系统内部的算法模块展开,如图 2 所示可以分为这三类,一类是基础的语音识别( ASR );第二类是文本分类,主要用于根据识别出的文本判断其中包含哪些违规内容。第三类是非语言识别,如果违规内容不是通过文字来表达的,就可以通过这部分进行识别。
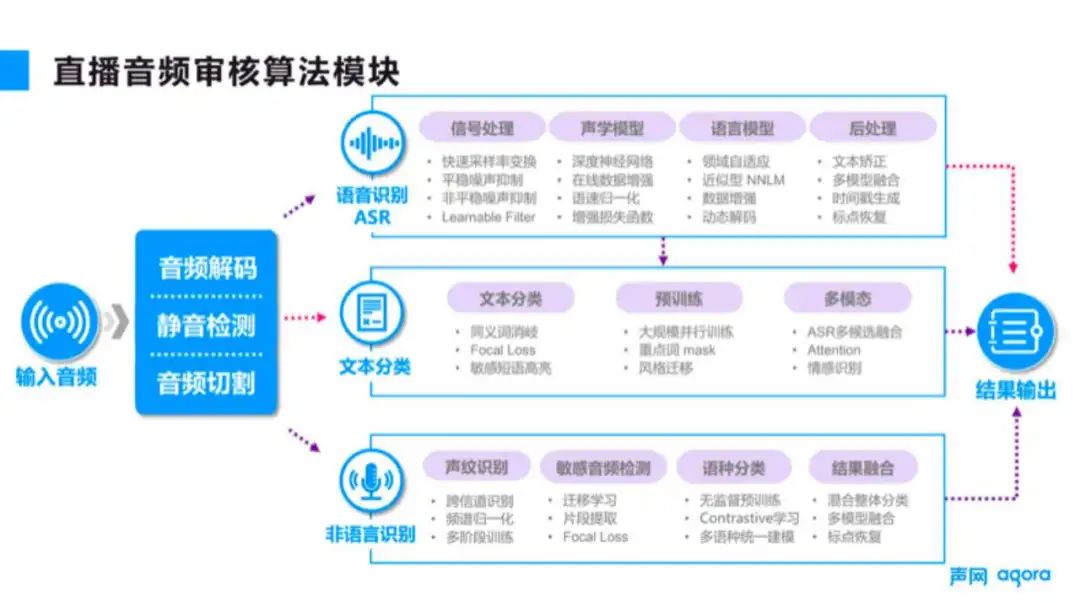
■图 2
2.1 语音识别( ASR )技术难点
首先介绍在 ASR 中遇到过的挑战。
总体来说,主要遇到的挑战有两点:第一点是强背景音的干扰,在互联网的语音场景下,通常伴有背景音乐或者游戏音效,环境一般比较嘈杂,甚至还会存在多人说话的情况,相比普通场景,这些特点叠加起来的语音识别难度会大大增加。
第二点是特定专有词的识别。某些违规词汇在生活中不经常出现,所以在语音识别的时候,如果没有进行专门的优化,会倾向于把音节识别成更常见的词,从而导致违规词的漏报。
2.1.1 强背景音性能优化
那么,如何应对这样的问题呢?针对强背景干扰问题,我们经过各种尝试,总结下来最有效的方法是从数据方面进行解决。
数据方面主要有两个优化:第一个是根据业务场景来创建一个比较精细的环境音模拟器,通过模拟器进行数据增强,这种方法在其他领域已经得到过验证,比如特斯拉的自动驾驶模型在训练过程中也是采用类似的技术来提升性能。
依图从发声模拟、房间模拟、收声模拟、信道模拟等多个维度构建了一个模拟器。在每个维度下可以进行参数调整,比如说话人的数量、语速语调或者背景音、声源的位置方向、失声效果、混响等。总体来说,大概有上百种参数可以进行调整。通过模拟器可以改善原来相对比较简单的训练数据的丰富度,使训练数据更贴近特定的场景,从而取得不错的性能提升效果。
另一个提升手段就是通过难例挖掘来进行训练 。在正常模型的训练过程中有正例数据也有负例数据,在包含大量数据的情况下,总是会存在一些正例数据与负例数据相似的情况,这样的数据通常称为难例,就是比较难的数据。在线难例挖掘就是在模型的训练过程中,反复把难例数据添加到训练中。类似错题本,通过错题本记录不太会的题目可以提升成绩。
这种方式应用到难例训练,可以让模型学到更多不容易区分的细节,进而获得不错的性能提升。通过以上技术,在有强背景音的数据分布下,模型也能取得不错的表现。
2.1.2 特定专有词识别
前面提到另外的一个挑战是专有词的识别。这里举一个例子,如图 3 所示,这里是对一段音频中文字的翻译,可以看到,如果之前没有听过“磕泡泡”这个词的话,则大概率无法识别出来这段话的含义。有可能是会把“磕泡”听成“可怕”。

■图 3
针对这个问题,我们经过尝试,发现有两个方法改进比较有效:第一个方法是在模型训练的时候,对专有词的 loss 强度进行权重的提升,也就是说,专有词如果做错,将给予更高的惩罚。比如上面的这个例子,正常情况下,说错一个字就扣 1 分,如果“磕泡泡”说错,就设置为扣 2 分。通过这种模式,模型就会更加努力地避免专有词识别错误。
第二个方法是在解码的时候调整搜索词库的候选词范围。如图 4 所示,语音识别算法工作的时候,首先是通过语音频谱的信号识别每个音素,然后把音素转换转成可能的文本。
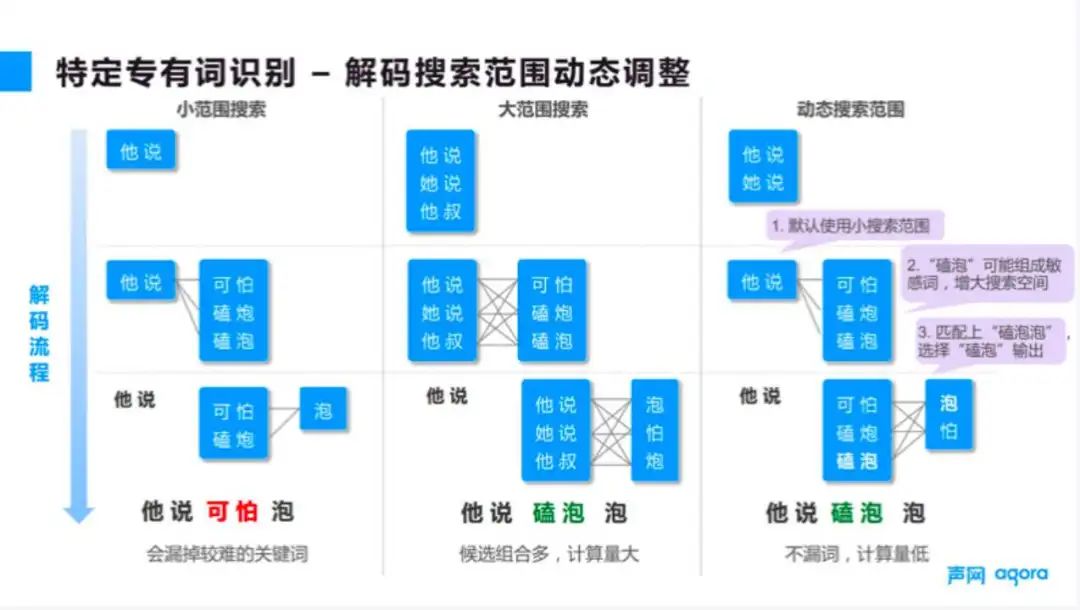
■图 4
针对专有词的优化,在把一连串的音素翻译成文本的时候,可以选择更多的候选词。比如在之前的例子当中,如果“磕泡”这两个字不在候选词的列表当中。那么无论如何都不可能正确识别出“磕泡炮”这个词。
这样的想法相对来说比较直观,但是实现之后会引入一个新的问题,那就是计算量会大幅度增加,基本上计算量的增加是呈平方级的复杂度。如果是在非实时的业务场景下,计算量的增加影响可能不是特别大。但是如果是在直播场景下,计算量的增加就有可能导致延迟变长。
这在直播对延迟比较敏感的情况下影响较大,所以要解决速度速度问题,一般来说比较好的直播是按照秒级进行审核,最差的要求也是分钟级。依图的加速方案是动态决定候选词的搜索范围,回到业务场景来看。内容审核并不是要求所有语句都必须识别得非常准确,最关键的问题是准确识别违规词,那么可以利用这一点来进行优化。
具体来说,当发现前面一个音素中可能存在违规词的时候,就对后续候选词的解码搜索范围进行扩充。这样既不会漏掉低频的违规词,同时也是可以避免对最终业务结果没有影响的计算,从而整体上大大减少计算量,保证业务的实时性。
2.2 非语言识别
在直播场景中,非语言识别的需求主要集中在重要人物的声纹识别、敏感音频检测、语种分类和结果融合等。
2.2.1 敏感音频检测
首先介绍敏感音频检测,敏感音频检测就是识别一段音频是否包含 ASMR 等违规语音。在敏感音检测方面遇到的技术难点主要有两个:第一个是敏感内容很短且长度不定,在直播当中,发布者为了规避审查,可能会将敏感音混杂在正常的说话中,这就导致敏感音时长一般比较短,从而具有隐蔽性。第二个是数据的违规浓度低,违规浓度低意味着是必须要有较低的误报才能减少人工审核的成本。在低误报的情况下,同时还要保持高召回,这对算法的鲁棒性有较高的要求。
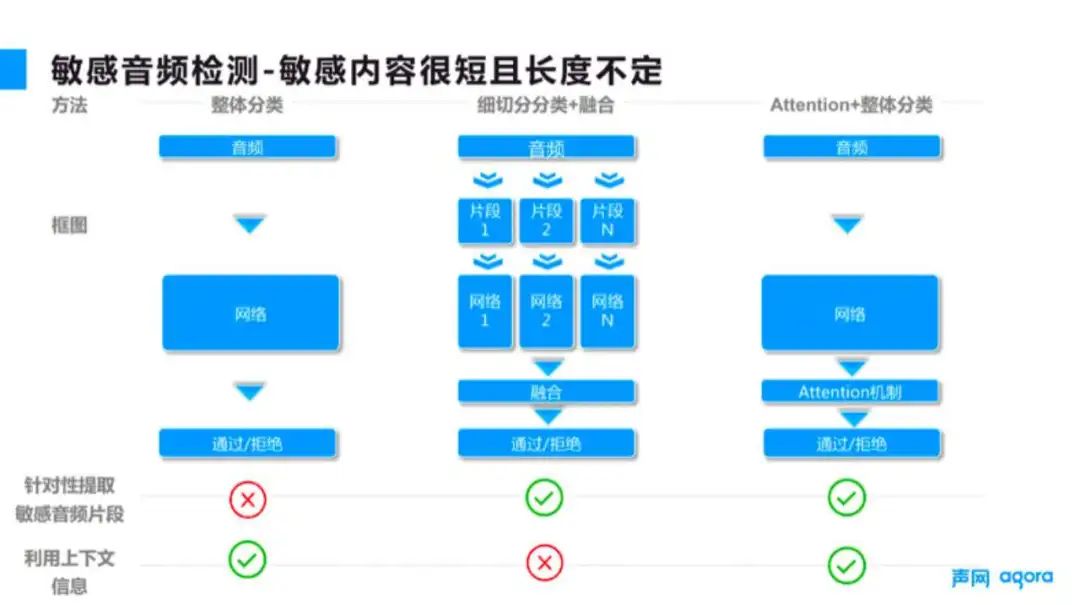
针对敏感音频检测敏感内容比较短的问题,如图 5 所示,主要是从算法网络层面进行优化。
■图 5
通常算法在进行检测的时候,会把一条数据作为一个整体来处理。当违规内容比较短的时候,则其他正常内容的声音信号就会将异常违规的信号掩盖住,recall 就会降低。
避免这种情况的方法,一般是把整条数据切分成更小的片段,这的确可以避免正常声音的干扰,但同时也失去了音频原本具有的上下文信息,从而导致误报。依图通过多次尝试和调研,使用了 Attention 机制来解决这样的问题。
Attention 在这几年的发展当中,不仅是在机器翻译,在文本、图像、语音等各个方面都取得了不错的效果。简单来说,就是给定一条序列数据,先算出这个序列当中哪些位置的数据是比较重要的,然后针对这些比较重要的位置的数据投入更多的关注度。
对应到场景来说,在接收到一条音频数据的时候,通过 Attention 机制既可以保留完整的信息,同时又能够判断出哪些地方更有可能是敏感音,从而分配更多的识别关注度,在整体上提升算法性能。
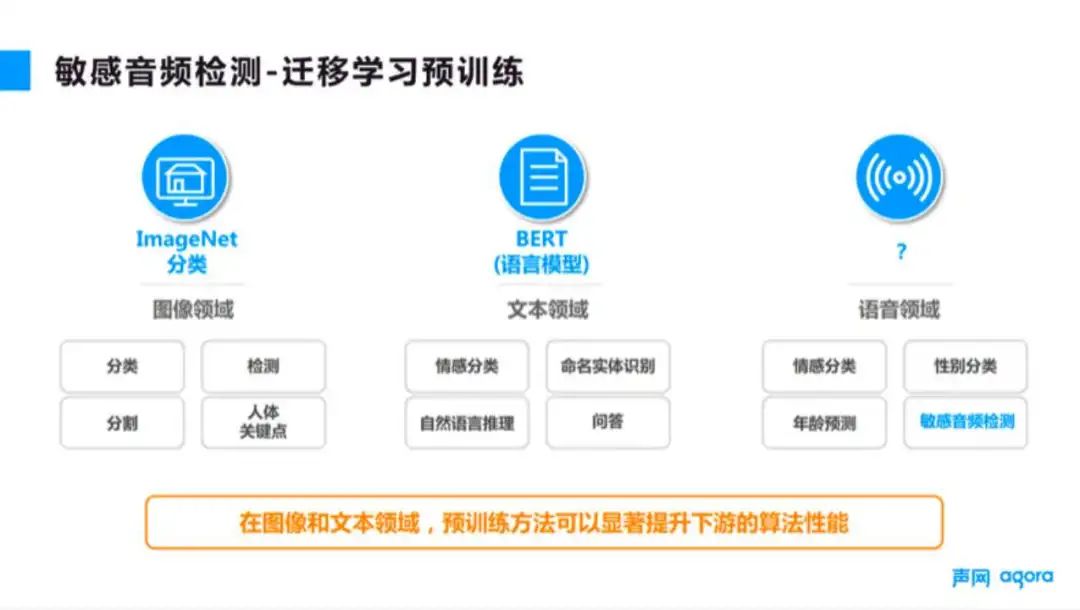
另一个挑战是针对低浓度下要求低误报高召回的挑战。我们采取的方案是用迁移学习预训练的方法来进行性能提升,如图 6 所示。迁移学习在各个领域也得到了大量的应用。我们是在其他已经训练得比较好的模型的基础上,对自己想要的模型进行额外的训练,最后得到一个比较好的模型,相当于我们是站在巨人的肩膀上做了后续的工作。
■图 6
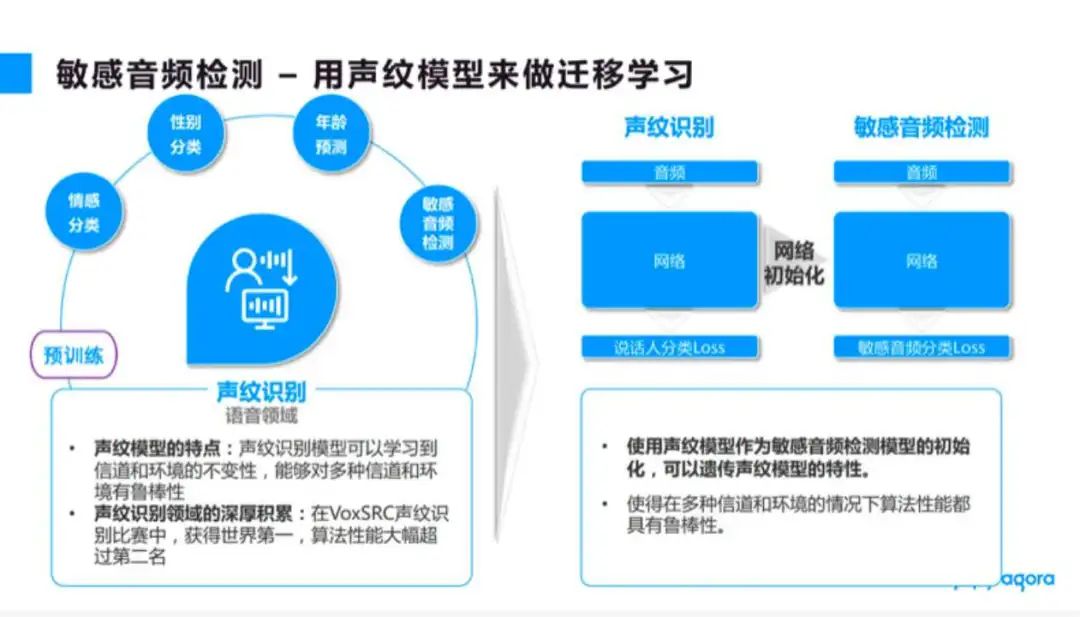
此前,依图在国内外的声纹比赛中取得过不错的成绩,因为敏感音频其实与声纹相关,而声纹本身也是同样类型的一个算法任务,所以我们很自然地考虑把这个优势迁移到敏感音频检测这个任务上。
如图 7 所示,依图声纹模型的特点是可以学习信道、环境等的不变性,从而对多种信道环境具有算法的阻断性。我们选择用自己的声纹模型作为敏感音检测模型的初始化模型,这样敏感音检测模型就继承了声纹模型的特性,使其在多种信道环境下的算法性能具有很好的鲁棒性。
■图 7
2.2.2 语种分类
语种分类的任务是判断输入音频中包含的语言种类。一般来说,在直播场景当中,主播说非中文语言的内容对平台来说是比较危险的事情。比如抖音上专门进行英语教学的主播是不敢一直使用英文进行教学,如果一直使用,比如持续一到两分钟,则很快就会收到平台发出的违规提醒。
如果有了语种分类的功能,对平台来说这种风险就会大幅度降低。平台就可以快速地找出有风险的直播间。如果平台的审核团队可以听懂主播的语言就能够细致地观察是否有违规的内容;如果审核团队听不懂。那么最简单的方法就是关掉直播间,平台就能避免这种风险。
在语种分类中主要遇到三个挑战:
第一个是信噪比低的数据容易出现误报或漏报。原因可能是环境噪音、混响回声、远场收音失真、信道失真等,如果再加上背景音乐或者直播特效的干扰,更是增加了语种分类的难度。
第二个挑战是语种数量较多导致难以训练。世界上可能涵盖了数千种语种,导致数据的收集或标注的难度都非常高,我们很难获取到大量的高质量能力的训练数据。
第三个挑战是传统算法思路一般具有局限性。如果一个人会说多种语言,则仅通过声纹信息可能无法判断;而在进行唱歌等场景下的分类时,模型容易过拟合到背景音乐上,导致泛化性较差;当语言的片段比较短的时候,可能难以抽取到比较准确的发音特征。
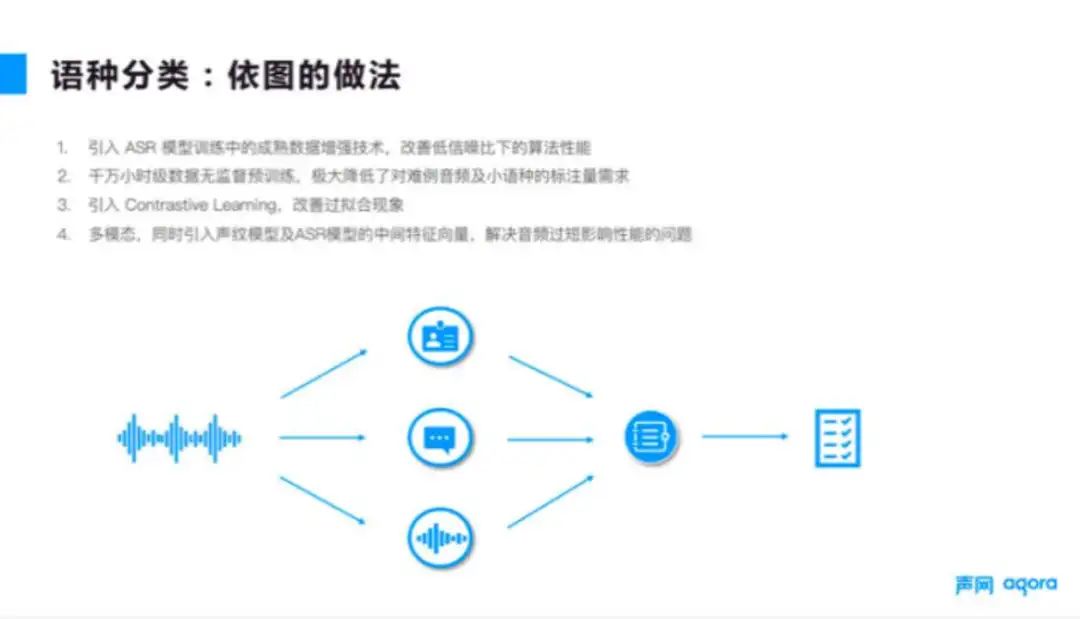
这些问题与之前介绍的挑战比较类似,这里不展开分析,如图 8 所示,通过数据增强,以及算法网络改进,预训练等多种手段就可以解决。目前依图线上的客户也一直在使用语种分类功能,从实战场景中观测,整体的准召还是不错的。
■图 8
关于声网云市场
声网云市场是声网推出的实时互动一站式解决方案,通过集成技术合作伙伴的能力,为开发者提供一站式开发体验,解决实时互动模块的选型、比价、集成、账号打通和购买,帮助开发者快速添加各类 RTE 功能,快速将应用推向市场,节约 95% 集成 RTE 功能时间。
依图实时语音转写(中文)目前已经上架声网云市场。依图实时语音转写提供流式语音识别能力,支持中文普通话,并且兼容多种口音。一边接收音频数据,一边提供转写结果,让您能够实时获取和利用文字信息。
依图在实时音视频中语音处理的挑战丨RTC Dev Meetup的更多相关文章
- 从零到一,使用实时音视频 SDK 一起开发一款 Zoom 吧
zoom(zoom.us) 是一款受到广泛使用的在线会议软件.相信各位一定在办公.会议.聊天等各种场景下体验或者使用过,作为一款成熟的商业软件,zoom 提供了稳定的实时音视频通话质量,以及白板.聊天 ...
- BBR在实时音视频领域的应用
小议BBR算法 BBR全称Bottleneck Bandwidth and RTT,它是谷歌在2016年推出的全新的网络拥塞控制算法.要说明BBR算法,就不能不提TCP拥塞算法. 传统的TCP拥塞控制 ...
- 微信小程序+腾讯云直播的实时音视频实战笔记
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- 实时音视频互动系列(下):基于 WebRTC 技术的实战解析
在 WebRTC 项目中,又拍云团队做到了覆盖系统全局,保证项目进程流畅.这牵涉到主要三大块技术点: 网络端.服务端的开发和传输算法 WebRTC 协议中牵扯到服务端的应用协议和信令服务 客户端iOS ...
- 融云携新版实时音视频亮相 LiveVideoStack 2019
4 月 19 日,LiveVideoStack 2019 音视频大会在上海隆重开幕,全球多媒体创新专家.音视频技术工程师.产品负责人.高端行业用户等共襄盛会,聚焦音频.视频.图像.AI 等技术的最新探 ...
- 了不起的WebRTC:生态日趋完善,或将实时音视频技术白菜化
本文原文由声网WebRTC技术专家毛玉杰分享. 1.前言 有人说 2017 年是 WebRTC 的转折之年,2018 年将是 WebRTC 的爆发之年,这并非没有根据.就在去年(2017年),WebR ...
- 腾讯互动白板+即时通讯+实时音视频,Android学生端接入
腾讯互动白板+即时通讯+实时音视频,Android学生端接入 一.简介 线上教学方案:腾讯云互动白板(Tencent Interactive Whiteboard,TIW)+即时通信(Instant ...
- 实时音视频互动系列(上):又拍云UTUN网络详解
如何定义实时音视频互动, 延迟 400ms 内才能无异步感 实时音视频互动如果存在1秒左右的延时会给交流者带来异步感,必须将视频播放延迟限制在400ms以内,才能给用户较好的交互体验. 当延迟控制在4 ...
- 小程序升级实时音视频录制及播放能力,开放 Wi-Fi、NFC(HCE) 等硬件连接功能
“ 小程序升级实时音视频录制及播放能力,开放 Wi-Fi.NFC(HCE) 等硬件连接功能.同时提供按需加载.自定义组件和更多访问层级等新特性,增强了第三方平台的能力,以满足日趋丰富的业务需求.” 0 ...
- 云-腾讯云-实时音视频:实时音视频(TRTC)
ylbtech-云-腾讯云-实时音视频:实时音视频(TRTC) 支持跨终端.全平台之间互通,从零开始快速搭建实时音视频通信平台 1.返回顶部 1. 腾讯实时音视频(Tencent Real-Time ...
随机推荐
- How to use lspci, lsscsi, lsusb, and lsblk to get Linux system devices information
There are many utilities available to check Linux system hardware information. Some commands report ...
- Leetcode习题集-链表
这里记录一些我刷题的思路方便之后进行复习重温,同时也方便进行添加 P141-环形链表 class Solution { public: bool hasCycle(ListNode *head) { ...
- node中get和post接口
接口传参 使用ajax请求向服务器接口传参,按http协议的约定,每个请求都有三个部分: 请求行: 保存了请求方式,地址,可以以查询字符串的格式附加一部分数据. 请求头:它可以附加很多信息,其中con ...
- ansiable学习
ansiable是用来做什么的? Ansible是一个配置管理和配置工具,是运维开发人员的批操作利器. ansiable是怎样实现高效的? 在一台机器上配置好模板,通过ssh在其他机器上按照模板执行. ...
- 使用LitJson输出格式化json文件到本地
百度上搜了半天,竟然没有C#使用LitJson格式化输出的例子,全都是Newtonsoft.Json的,最后在litjson的官网找到了方法. 给大家分享一下: https://litjson.net ...
- 【LeetCode】 907 子数组的最小值之和
Decrisption Given an array of integers arr, find the sum of min(b), where b ranges over every (conti ...
- IP协议数据包
Header Length:头部长度固定20字节,永远为5(4bit为单位) Total Length:头部+包, 抓包结果 Identification.Fragment Flags.Fragmen ...
- vscode 自用插件
Auto Rename Tag 自动配对标签,一同更改: 这个还是比较推荐吧,需要修改的时候只用改第一个,闭合的那一头自动跟着修改了. Quokka ...
- PVE联网及更换国内源
一.PVE联网 第一次安装PVE,正常情况下PVE的IP是在我们上网的网段的.没有网络有可能是没有配置DNS服务器地址或DNS地址是软路由网关地址.解决方法有3种: 1:设置DHCP自动获取网络地址和 ...
- 基于CMMI的软件工程及实训指导 第一章
第一章 软件工程基础 1. 软件工程概述 1.1 软件工程概念 软件工程是从管理和技术两方面来研究如何采用工程的概念.原理和技术方面并加以综合,指导开发人员更好地开发和维护计算机软件的一门新学科. 1 ...