Hadoop原生对象存储Ozone
Hadoop 社区推出了新一代分布式Key-value对象存储系统 Ozone,同时提供对象和文件访问的接口,从构架上解决了长久以来困扰HDFS的小文件问题。本文作为Ozone系列文章的第一篇,抛个砖,介绍Ozone的产生背景,主要架构和功能。
背景
HDFS是业界默认的大数据存储系统,在业界的大数据集群中有非常广泛的使用。HDFS集群有着很高的稳定性,得益于它较简单的构架,集群也很容易扩展。业界包含几千个数据节点,保存上百PB数据的集群也不鲜见。
HDFS通过把文件系统元数据全部加载到Namenode内存中,给客户端提供了低延迟的元数据访问。由于元数据需要全部加载到内存,所以一个HDFS集群能支持的最大文件数,受JAVA堆内存的限制,上限大概是4亿左右个文件。所以HDFS适合大量大文件(几百兆以上)的集群,如果集群中有非常多的小文件,HDFS的元数据访问性能会受到影响。虽然可以通过各种Federation技术来扩展集群的节点规模, 但单个HDFS集群仍然没法很好的解决小文件的限制。
基于这些背景,Hadoop 社区推出了新的分布式存储系统 Ozone,从构架上解决这个问题。

目前,Ozone已经脱离成为Hadoop子项目,逐渐升级为Apache的顶级项目,详见:https://ozone.apache.org。
设计原则
Ozone 由一群对大规模Hadoop集群有着丰富运维和管理经验的工程师和构架师设计和实现。他们对大数据有深刻的洞察力,清楚地了解HDFS的优缺点,这些洞察力自始自终影响了Ozone的设计和实现。Ozone的设计遵循以下原则:
- 弱一致性
- 架构简洁性,当系统出现问题时,一个简单的架构更容易定位,也容易调试。Ozone尽可能的保持架构的简单,即使因此需要可扩展性上做一些妥协。但是在Ozone在扩展性上绝不逊色,目标是支持单集群1000亿个对象。
- 架构分层,Ozone采用分层的文件系统。Namespace 元数据的管理,数据块和节点的管理分开。用户可以对二者独立扩展。
- 容易恢复,HDFS一个关键优点是,它能经历大的灾难事件,比如集群级别的电力故障,而不丢失数据, 并且能高效的从灾难中恢复。对于一些小的故障,比如机架和节点级别的故障,更是不在话下。Ozone将继承HDFS的这些优点。
- Apache开源,Apache社区开源对于Ozone的成功非常重要。所有Ozone的设计和实现都在社区中进行,接受社区所有人的Review。
- 与Hadoop生态的互操作性,Ozone可以被Hadoop生态中的应用,如 Apache Hive、Apache Spark 和 Mapreduce 无缝对接。Ozone支持Hadoop Compatible FileSystem API (aka OzoneFS)。通过OzoneFS, Hive,Spark等应用不需要做任何修改,就可以运行在Ozone上。Ozone同时支持Data Locality,使得计算能够尽可能的靠近数据。
语义
Ozone是一个分布式Key-value对象存储系统。Ozone提供给用户的语义包含Volume, Bucket 和Key。
- Volume,概念与账户类似,类似于用户的Home目录,建议每个用户单独创建自己的Volume。Volume只有系统管理员才可以创建和删除,是存储管理的单位,比如配额管理。Volume用来存储Bucket,一个Volume下面可以包含任意多个Bucket。
- Bucket,桶的概念类似于目录,用户可以在自己所在的卷下创建任意多的桶,Bucket 下存储任意多的Key 和 Value,但是不包括其他Bucket。Bucket 的概念类似于 S3 的 Bucket,或者 Azure 中的 Container。Bucket 由 ACL 来控制访问。
- Key,概念和文件类似,每个 Key 在 Bucket 中必须唯一,可以是任意字符串。用户的数据以 Key-value 的形式存储在 Bucket 下,用户通过key来读写数据。
- Ozone URL,Ozone URL 采用的格式:
[schema][server:port]/volume/bucket/key。其中schema可选,有两种协议支持。第一,O3 -通过 RPC 协议访问 Ozone Manager 和 Datanodes;第二,HTTP/HTTPS-通过 HTTP 协议访问REST API。Scheme可以省略,这种情况下默认使用RPC协议。Server:Port 是 Ozone Manager 的地址。如果没有指定,则用定义在 ozone-site.xml 中 "ozone.om.address" 默认值。
架构
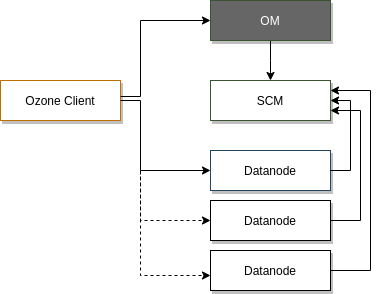
Ozone 从结构上分为四个部分:Ozone Manager, 元数据管理;Storage Container Manager, 数据块和节点管理;Datanodes, 数据最终的存放处;Recon Server 管理和监视控制台。类比 HDFS 的构架, 可以看到原来 Namenode 的功能,现在由 Ozone Manager 和 Storage Container Manage 分别进行管理了。接下来,我们仔细看一下 Ozone 主要模块和概念。


Ozone Manager
管理 Ozone 的 Namespace,提供所有的 Volume, Bucket 和 Key 的新建,更新和删除操作。存储了 Ozone 的元数据信息,这些元数据信息包括 Volumes、Buckets 和 Keys,底层通过 Ratis(实现了Raft协议) 扩展元数据的副本数来实现 元数据的 HA。Ozone Manager 只和 Ozone Client 和 Storage Container Manager 通信,并不直接和 Datanode 通信。
Storage Container Manager(SCM)
类似HDFS中的Block Manager,管理 Container, Pipelines 和 Datanode,为 Ozone Manager 提供Block 和 Container 的操作和信息。SCM也监听 Datanode 发来的心跳信息,作为Datanode manager的角色, 保证和维护集群所需的数据冗余级别。SCM 和 Ozone Client 之间没有通信。

Block、Container 和 Pipeline
Block 是数据块对象,真实存储用户的数据。Container是一个逻辑概念,是由一些相互之间没有关系的 Block 组成的集合。在 Ozone 中, 数据是以 Container 的粒度进行副本复制的。Pipeline 来保证 Container 实现想要的副本数。SCM 中目前支持2种 Pipeline 方式实现多副本,单副本的 Standalone 模式和三副本的 Ratis 方式。Container 有2种状态,OPEN 和 CLOSED。当一个Container 是 OPEN 状态时,可以往里边写入新的 BLOCK。当一个Container 达到它预定的大小时(默认5GB),它从 OPEN 状态转换成 CLOSED 状态。一个 Closed Container 是不可修改的。

Datanodes
Datanode 是 Ozone 的数据节点,以 Container 为基本存储单元,维护每个 Container 内部的数据映射关系,定时向 SCM 发送心跳节点,汇报节点的信息,管理的 Container 的信息,Pipeline 的信息。当一个 Container Size 超过预定的大小 90% 时 或者写操作失败时,Datanode 会发送 Container Close 命令给 SCM,把 Container 的状态从 Open 转变成 Closed。或者当Pipeline 出错时,发送 Pipeline Close 命令给SCM,把Pipeline 从 Open 状态转为 Closed 状态。

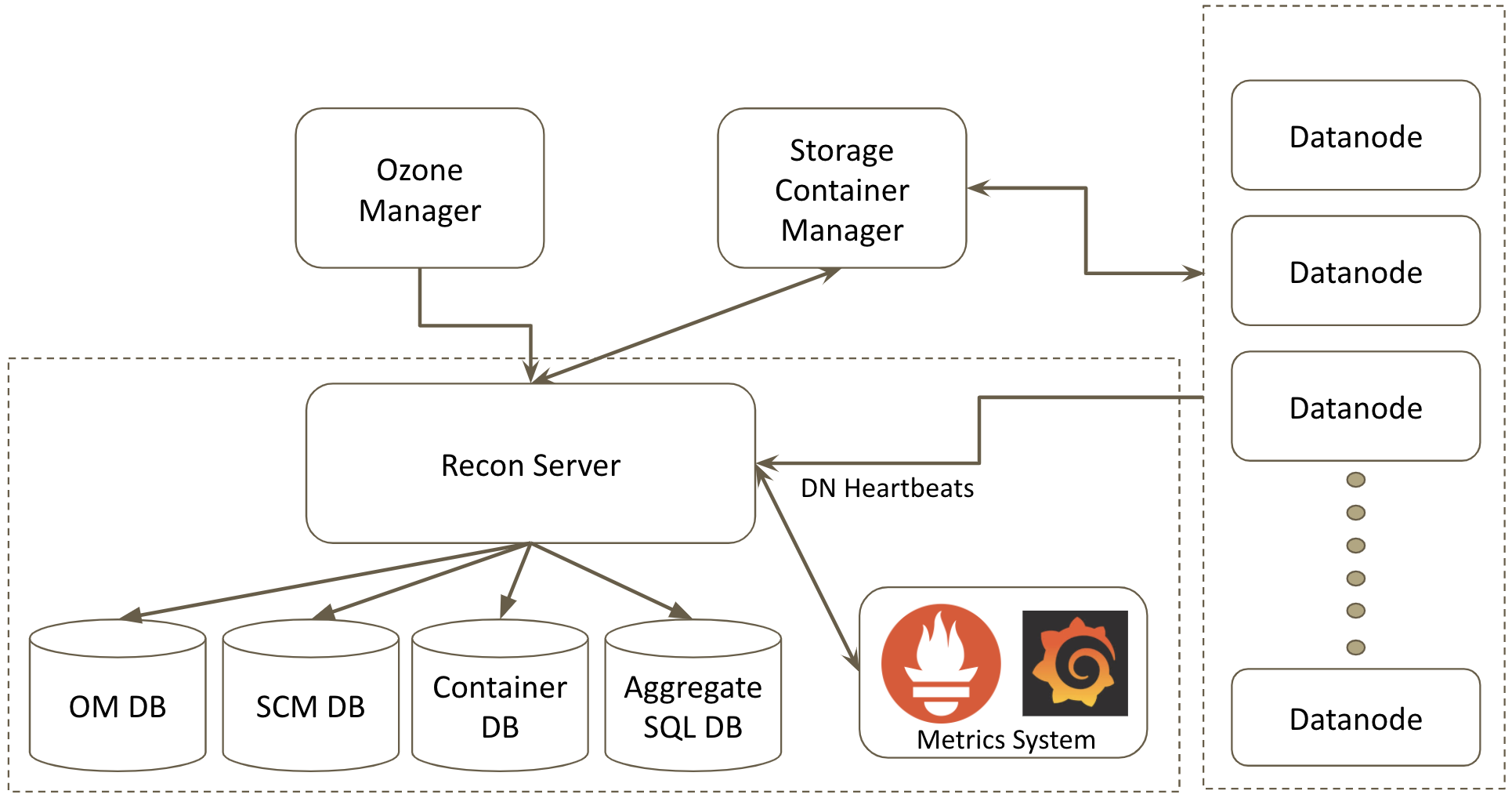
Recon Server
Recon 充当 Ozone 的管理和监视控制台。它提供了 Ozone 的鸟瞰图,并通过基于 REST 的 API 和丰富的网页用户界面(Web UI)展示了集群的当前状态,从而帮助用户解决任何问题。
在较高的层次上,Recon 收集和汇总来自 Ozone Manager(OM)、Storage Container Manager(SCM)和数据节点(DN)的元数据,并充当中央管理和监视控制台。Ozone 管理员可以使用 Recon 查询系统的当前状态,而不会使 OM 或 SCM 过载。
Recon 维护多个数据库,以支持批处理,更快的查询和持久化聚合信息。它维护 OM DB 和 SCM DB 的本地副本,以及用于持久存储聚合信息的 SQL 数据库。
Recon 还与 Prometheus 集成,提供一个 HTTP 端点来查询 Prometheus 的 Ozone 指标,并在网页用户界面(Web UI)中显示一些关键时间点的指标。
读写过程
写过程
Ozone 客户端 先和 Ozone Manager 通信,提供需要创建的Key 的信息,包括 /volume/bucket/key,数据的大小,备份数,和其他用户自定义Key的属性。Ozone Manager 收到 Ozone 客户端的请求后,调用SCM 的服务,寻找足够容纳数据的Open Container,将Container 对应的Pipeline 的Datanode 列表信息返回给Ozone Manager。Ozone Manager 返回对应的信息给客户端。
客户端拿到Datanode列表信息之后,和第一个Datanode(Raft Leader)建立通信,将数据写入Datanode 的Container 中,更新Container 的元数据,记录新增加的这个数据块。
最后,客户端再和Ozone Manager 通信,告知数据已经成功的在 Datanode写入了。Ozone 修改 Namspace 元数据,记录一个新生成的Key。之后,其他的客户端就可以访问这个Key了。

读过程
读的过程相对简单,类似于HDFS的文件读。Ozone 客户端 先和 Ozone Manager 通信,告知需要读取的Key 的信息(/volume/bucket/key)。Ozone Manager 在元数据库中查找对应的Key,返回 Key 数据所在的 Datanode 列表给Ozone 客户端。Ozone 支持Data locality。如果Ozone 客户端运行在集群中的某个节点上,Ozone Manager 会返回按照网络拓扑距离排序的Datanode列表。当 Ozone 客户端拿到 Key 的信息之后,可以选择第一个Datanode 节点(一本地节点),也是离客户端最近的节点来读取数据,节省数据读取的时间。

与Hadoop生态的结合
Ozone 同时支持 Hadoop 2.x 和 Hadoop 3.x 集群,能够和运行其上的Hive,Spark 等应用无缝集成。
结束
Apache Ozone 是一个开发迭代非常活跃的社区,在 2018 年发布了版本 0.2.1 和 0.3.0,支持 OzoneFS, YARN, HIVE and Spark on OzoneFS, S3 协议接口。2019年发布了版本0.4.0,0.4.1 和0.4.2,支持基于Kerbero的认证,透明数据加密/解密,支持Ranger,实现CNCF CSI 插件支持Kubernetes布署。2020年0.5.0 的发布正在进行中。Ozone 社区提供Docker-Compose脚本,帮助初次使用者很方便的布署单集群,尝试Ozone的各种功能。目前最新版已到1.2.1,更多文档的信息,请参考Apache Ozone官网和对应的Github开源项目。
Hadoop原生对象存储Ozone的更多相关文章
- HDFS对象存储--Ozone架构设计
前言 如今做云存储的公司非常多,举2个比較典型的AWS的S3和阿里云.他们都提供了一个叫做对象存储的服务,就是目标数据是从Object中进行读写的,然后能够通过key来获取相应的Object,就是所谓 ...
- 使用 HDFS 协议访问对象存储服务
背景介绍 原生对象存储服务的索引是扁平化的组织形式,在传统文件语义下的 List 和 Rename 操作性能表现上存在短板.腾讯云对象存储服务 COS 通过元数据加速功能,为上层计算业务提供了等效于 ...
- 听说你想把对象存储当 HDFS 用,我们这里有个方案...
传统的大数据集群往往采用本地中心化的计算和存储集群.比如在谷歌早期的[三驾马车]中,使用 GFS 进行海量网页数据存储,用 BigTable 作为数据库并为上层提供各种数据发现的能力,同时用 MapR ...
- 使用MinIO搭建对象存储服务
1.MinIO是什么? MinIO 是一款高性能.分布式的对象存储系统. 它是一款软件产品, 可以100%的运行在标准硬件.即X86等低成本机器也能够很好的运行MinIO. MinIO与传统的存储和其 ...
- 【巨杉数据库Sequoiadb】巨杉⼯具系列之一 | ⼤对象存储⼯具sdblobtool
近期,巨杉数据库正式推出了完整的SequoiaDB 工具包,作为辅助工具,更好地帮助大家使用和运维管理分布式数据库.为此,巨杉技术社区还将持续推出工具系列文章,帮助大家了解巨杉数据库丰富的工具矩阵. ...
- Github 29K Star的开源对象存储方案——Minio入门宝典
对象存储不是什么新技术了,但是从来都没有被替代掉.为什么?在这个大数据发展迅速地时代,数据已经不单单是简单的文本数据了,每天有大量的图片,视频数据产生,在短视频火爆的今天,这个数量还在增加.有数据表明 ...
- Hadoop小文件存储方案
原文地址:https://www.cnblogs.com/ballwql/p/8944025.html HDFS总体架构 在介绍文件存储方案之前,我觉得有必要先介绍下关于HDFS存储架构方面的一些知识 ...
- js es6 map 与 原生对象区别
区别 object和Map存储的都是键值对组合.但是: object的键的类型是 字符串: map的键的类型是 可以是任意类型: 另外注意,object获取键值使用Object.keys(返回数组): ...
- 网易对象存储NOS图床神器
本文来自网易云社区 注:使用过程中有什么问题或建议欢迎到如下链接提交:http://note.youdao.com/noteshare?id=6321086fa4d7a6c003656354c1aa6 ...
随机推荐
- 计算机网络再次整理————tcp的关闭[七]
前言 tcp的关闭不是简单粗暴的,相对而言是友好优雅的,好聚好散吧. 那么友好的关闭方式是这样的: 假设这里是客户端请求关闭的,服务端倒过来. 客户端:我要请求关闭 服务端:我接收到你的请求了,等我把 ...
- js源码-自定义数组的pop和shift方法
本文将自定义_pop和_shift来模拟数组的pop和shift方法 _pop: /* *js中数组的pop方法:删除数组的最后一个元素,把数组的长度减1,并且返回删除的这个元素:如果数组为空,则po ...
- Python安装pip时, 报错:zipimport.ZipImportError: can't decompress data; zlib not available
解决办法: 1.安装依赖zlib.zlib-devel 2.重新编译安装Python 具体步骤: 1 到python安装目录下,运行./configure 2 编辑Modules/Setup文件 vi ...
- Ubuntu16.04的PHP开发环境配置
\3c a { text-decoration: none } 自从换了php开发之后发现还是开源语言才是长久之道,开发环境搭建方便,支持的平台也多,性能也好,考虑到这些,其他一些不如意也就不足为虑了 ...
- VC 创建快捷方式
转载请注明来源:https://www.cnblogs.com/hookjc/ VC6下测试时使用的是绝对地址BOOL CFGDlg::CreateLink ( LPSTR szPath ...
- 基于Apache的Tomcat负载均衡和集群(2)
反向代理负载均衡 (Apache+JK+Tomcat) 使用代理服务器可以将请求转发给内部的Web服务器,让代理服务器将请求均匀地转发给多台内部Web服务器之一上,从而达到负载均衡的目的.这种代理方式 ...
- rsync 远程同步部署——上下行同步
rsync 远程同步部署--上下行同步 1.rsync (Remote Sync,远程同步) : 是一个开源的快速备份工具,可以在不同主机之间镜像同步整个目录树,支持增量备份,并保持链接和权限,且采用 ...
- Linux之shell变量
一.变量名的规范 定义形如:class_name='xiaohemiao' 使用形如:echo $class_name 1.变量名后面的等号左右不能有空格 2.命名只能使用英文字母,数字和下划线,首个 ...
- 一劳永逸Java环境配置,以及编写我的第一个Java程序
Java环境配置,以及编写我的第一个Java程序 配置步骤 1.下载jdk 2.安装步骤 3.配置环境 4.我的第一个Java程序 配置步骤 网上的教程有很多,方法也都不尽相同.今天我就分享一下我的配 ...
- 2018 PHP面试题
2018 PHP面试题 题目来自<PHP程序员面试笔试宝典>,里面涵盖了近三年了各大型企业常考的PHP面试题,针对面试题提取出来各种面试知识也涵盖在了本书. 1.PHP常考基础 1.PHP ...