KingbaseES R3 集群删除test库导致主备无法切换问题
案例说明:
在KingbaseES R3集群中,kingbasecluster进程会通过test库访问,连接后台数据库服务测试;如果删除test数据库,导致后台数据库服务访问失败,在集群主备切换时,无法访问后台数据库服务,导致切换失败。修改集群HAmodule.conf配置文件相关参数后,可以解决集群test库被删除导致主备切换失败问题。
测试数据库版本:
prod=# select version();
version
-------------------------------------------------------------------------------------------------------------------------
Kingbase V008R003C002B0270 on x86_64-unknown-linux-gnu, compiled by gcc (GCC) 4.1.2 20080704 (Red Hat 4.1.2-46), 64-bit
(1 row)
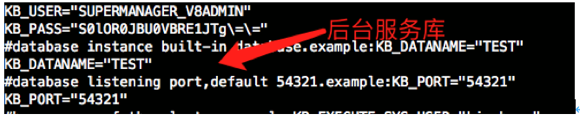
一、查看集群访问test库配置
[kingbase@node1 etc]$ cat HAmodule.conf |grep -i test
#database instance built-in database.example:KB_DATANAME="TEST"
KB_DATANAME="TEST"
二、查看kingbase_monitor.sh访问test库信息
=可以从kingbase_monitor.sh start的启动过程,看到对test库的访问=
[kingbase@node1 bin]$ sh -x kingbase_monitor.sh restart > ~/kmon.txt
[kingbase@node1 ~]$ cat kmon.txt |grep -i test
+ param='KB_DATANAME="TEST"'
+ paramValue='"TEST"'
+ '[' -z '"TEST"' ']'
+ eval 'KB_DATANAME="TEST"'
++ KB_DATANAME=TEST
++ /home/kingbase/cluster/kha/db/bin/ksql 'host=192.168.7.248 port=54321 user=SUPERMANAGER_V8ADMIN password=KINGBASEADMIN dbname=TEST connect_timeout=10' -Aqtc 'select count(*)=1 from sys_stat_replication;'
++ /home/kingbase/cluster/kha/db/bin/ksql 'host=192.168.7.248 port=54321 user=SUPERMANAGER_V8ADMIN password=KINGBASEADMIN dbname=TEST connect_timeout=10' -Aqtc 'select sys_xlog_location_diff(sys_current_xlog_flush_location(), write_location)<=16777216 from sys_stat_replication;'

二、集群删除test库测试(主库)
# 查看database cluster
[kingbase@node3 bin]$ ./ksql -U system -W 123456 prod
ksql (V008R003C002B0270)
Type "help" for help.
prod=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+--------+----------+-------------+-------------+--------------------
prod | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
SAMPLES | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
SECURITY | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
TEMPLATE0 | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/system +
| | | | | system=CTcb/system
TEMPLATE1 | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/system +
| | | | | system=CTcb/system
TEMPLATE2 | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =Tc/system +
| | | | | system=CTcb/system
TEST | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
(7 rows)
# 主库判断
prod=# select sys_is_in_recovery();
sys_is_in_recovery
--------------------
f
(1 row)
# 查看流复制状态
prod=# select * from sys_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin |
state | sent_location | write_location | flush_location | replay_location | sync_priority | sync_state
-------+----------+---------+------------------+---------------+-----------------+-------------+-------------------------------+--------------+--
25795 | 10 | system | node243 | 192.168.7.243 | | 45418 | 2021-03-01 12:49:12.263710+08 | | s
treaming | 0/E0001B0 | 0/E0001B0 | 0/E0001B0 | 0/E000178 | 0 | async
(1 row)
# 主库删除test库:
prod=# drop database test;
DROP DATABASE
prod=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+--------+----------+-------------+-------------+--------------------
prod | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
SAMPLES | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
SECURITY | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
TEMPLATE0 | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/system +
| | | | | system=CTcb/system
TEMPLATE1 | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/system +
| | | | | system=CTcb/system
TEMPLATE2 | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =Tc/system +
| | | | | system=CTcb/system
(6 rows)
# 备库查看:
[kingbase@node3 bin]$ ./ksql -U system -W 123456 prod
ksql (V008R003C002B0270)
Type "help" for help.
prod=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+--------+----------+-------------+-------------+--------------------
prod | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
SAMPLES | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
SECURITY | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
TEMPLATE0 | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/system +
| | | | | system=CTcb/system
TEMPLATE1 | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/system +
| | | | | system=CTcb/system
TEMPLATE2 | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =Tc/system +
| | | | | system=CTcb/system
(6 rows)
三、主备failover切换测试
1)关闭主库数据库服务
[kingbase@node1 bin]$ ./sys_ctl stop -D ../data
waiting for server to shut down....... done
server stopped
2)查看日志
备库cluster.log:(从日志可以获知,备库访问主库后台数据库服务失败,已经发起了failover的切换)
......
2021-03-01 12:41:16: pid 14431: LOG: health checking retry count 1
2021-03-01 12:41:16: pid 14431: LOG: failed to connect to kingbase server on "192.168.7.248:54321", getsockopt() detected error "Connection refused"
2021-03-01 12:41:16: pid 14431: ERROR: failed to make persistent db connection
2021-03-01 12:41:16: pid 14431: DETAIL: connection to host:"192.168.7.248:54321" failed
2021-03-01 12:41:18: pid 14644: LOG: watchdog checking if kingbasecluster is alive using heartbeat
2021-03-01 12:41:18: pid 14644: DETAIL: the last heartbeat from "192.168.7.248:9999" received 0 seconds ago
......
2021-03-01 12:41:22: pid 14473: LOG: received the failover command lock request from local kingbasecluster on IPC interface
2021-03-01 12:41:22: pid 14473: LOG: local kingbasecluster node "192.168.7.243:9999 Linux node3" is requesting to become a lock holder for failover ID: 69
2021-03-01 12:41:22: pid 14473: LOG: local kingbasecluster node "192.168.7.243:9999 Linux node3" is the lock holder
2021-03-01 12:41:22: pid 14431: LOG: starting degeneration. shutdown host 192.168.7.248(54321)
2021-03-01 12:41:22: pid 14431: LOG: Restart all children
2021-03-01 12:41:22: pid 14431: LOG: execute command: /home/kingbase/cluster/kha/kingbasecluster/bin/failover_stream.sh 192.168.7.243 1 1 192.168.7.248 192.168.7.248 0 0 /home/kingbase/cluster/kha/db/data
......
3)查看备库数据库服务(切换失败)
=备库数据库服务仍然启动recovery,还是在备库状态=
[kingbase@node3 log]$ ps -ef |grep kingbase
kingbase 13764 1 0 12:31 ? 00:00:01 /home/kingbase/cluster/kha/db/bin/kingbase -D /home/kingbase/cluster/kha/db/data
kingbase 13781 13764 0 12:31 ? 00:00:00 kingbase: logger process
kingbase 13782 13764 0 12:31 ? 00:00:00 kingbase: startup process recovering 00000001000000000000000F
kingbase 13786 13764 0 12:31 ? 00:00:00 kingbase: checkpointer process
kingbase 13787 13764 0 12:31 ? 00:00:00 kingbase: writer process
kingbase 13788 13764 0 12:31 ? 00:00:00 kingbase: stats collector process
.......
查看备库failover.log:
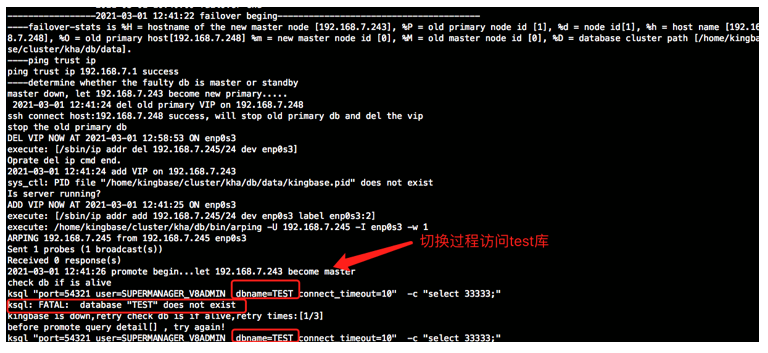
=== 有以下日志信息获知,在切换过程中需要访问test库,而test库被删除,导致访问失败,主备切换不成功===
-----------------2021-03-01 12:41:22 failover beging---------------------------------------
----failover-stats is %H = hostname of the new master node [192.168.7.243], %P = old primary node id [1], %d = node id[1], %h = host name [192.168.7.248], %O = old primary host[192.168.7.248] %m = new master node id [0], %M = old master node id [0], %D = database cluster path [/home/kingbase/cluster/kha/db/data].
----ping trust ip
ping trust ip 192.168.7.1 success
----determine whether the faulty db is master or standby
master down, let 192.168.7.243 become new primary.....
2021-03-01 12:41:24 del old primary VIP on 192.168.7.248
ssh connect host:192.168.7.248 success, will stop old primary db and del the vip
stop the old primary db
DEL VIP NOW AT 2021-03-01 12:58:53 ON enp0s3
execute: [/sbin/ip addr del 192.168.7.245/24 dev enp0s3]
Oprate del ip cmd end.
2021-03-01 12:41:24 add VIP on 192.168.7.243
sys_ctl: PID file "/home/kingbase/cluster/kha/db/data/kingbase.pid" does not exist
Is server running?
ADD VIP NOW AT 2021-03-01 12:41:25 ON enp0s3
execute: [/sbin/ip addr add 192.168.7.245/24 dev enp0s3 label enp0s3:2]
execute: /home/kingbase/cluster/kha/db/bin/arping -U 192.168.7.245 -I enp0s3 -w 1
ARPING 192.168.7.245 from 192.168.7.245 enp0s3
Sent 1 probes (1 broadcast(s))
Received 0 response(s)
2021-03-01 12:41:26 promote begin...let 192.168.7.243 become master
check db if is alive
ksql "port=54321 user=SUPERMANAGER_V8ADMIN dbname=TEST connect_timeout=10" -c "select 33333;"
ksql: FATAL: database "TEST" does not exist
kingbase is down,retry check db is if alive,retry times:[1/3]
before promote query detail[] , try again!
ksql "port=54321 user=SUPERMANAGER_V8ADMIN dbname=TEST connect_timeout=10" -c "select 33333;"
ksql: FATAL: database "TEST" does not exist
kingbase is down,retry check db is if alive,retry times:[2/3]
before promote query detail[] , try again!
ksql "port=54321 user=SUPERMANAGER_V8ADMIN dbname=TEST connect_timeout=10" -c "select 33333;"
ksql: FATAL: database "TEST" does not exist
kingbase is down,retry check db is if alive,retry times:[3/3]
before promote query detail[] , try again!
kingbase is down,after retry 3 times ,cannot do promote, will exit
execute kingbase_promote.sh failed ,will exit script with error
"ssh -o StrictHostKeyChecking=no -l kingbase -T 192.168.7.243 "/home/kingbase/cluster/kha/db/bin/kingbase_promote.sh /home/kingbase/cluster/kha/db/bin SUPERMANAGER_V8ADMIN TEST 54321 /home/kingbase/cluster/kha/db/data 3 3 2>&1"" execute failed, error num=[66]
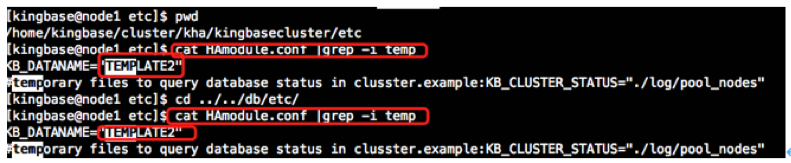
四、修改HAmodule.conf配置文件参数(所有节点)
=将访问test库更改为template2库=
[kingbase@node1 etc]$ pwd
/home/kingbase/cluster/kha/kingbasecluster/etc
[kingbase@node1 etc]$ cat HAmodule.conf |grep -i temp
KB_DATANAME="TEMPLATE2"
[kingbase@node1 etc]$ cd ../../db/etc/
[kingbase@node1 etc]$ cat HAmodule.conf |grep -i temp
KB_DATANAME="TEMPLATE2"
五、重新启动集群
** 1)重启集群**
[kingbase@node1 bin]$ ./kingbase_monitor.sh restart
-----------------------------------------------------------------------
2021-03-01 13:18:35 KingbaseES automation beging...
2021-03-01 13:18:35 stop kingbasecluster [192.168.7.243] ...
remove status file /home/kingbase/cluster/kha/run/kingbasecluster/kingbasecluster_status
DEL VIP NOW AT 2021-03-01 13:01:11 ON enp0s3
No VIP on my dev, nothing to do.
2021-03-01 13:18:41 Done...
2021-03-01 13:18:41 stop kingbasecluster [192.168.7.248] ...
remove status file /home/kingbase/cluster/kha/run/kingbasecluster/kingbasecluster_status
DEL VIP NOW AT 2021-03-01 13:18:46 ON enp0s3
No VIP on my dev, nothing to do.
2021-03-01 13:18:47 Done...
2021-03-01 13:18:47 stop kingbase [192.168.7.243] ...
set /home/kingbase/cluster/kha/db/data down now...
2021-03-01 13:18:50 Done...
2021-03-01 13:18:51 Del kingbase VIP [192.168.7.245/24] ...
DEL VIP NOW AT 2021-03-01 13:01:22 ON enp0s3
execute: [/sbin/ip addr del 192.168.7.245/24 dev enp0s3]
Oprate del ip cmd end.
2021-03-01 13:18:51 Done...
2021-03-01 13:18:51 stop kingbase [192.168.7.248] ...
set /home/kingbase/cluster/kha/db/data down now...
2021-03-01 13:18:56 Done...
2021-03-01 13:18:57 Del kingbase VIP [192.168.7.245/24] ...
DEL VIP NOW AT 2021-03-01 13:18:57 ON enp0s3
No VIP on my dev, nothing to do.
2021-03-01 13:18:57 Done...
......................
all stop..
ping trust ip 192.168.7.1 success ping times :[3], success times:[2]
ping trust ip 192.168.7.1 success ping times :[3], success times:[2]
start crontab kingbase position : [3]
Redirecting to /bin/systemctl restart crond.service
start crontab kingbase position : [2]
Redirecting to /bin/systemctl restart crond.service
ADD VIP NOW AT 2021-03-01 13:19:10 ON enp0s3
execute: [/sbin/ip addr add 192.168.7.245/24 dev enp0s3 label enp0s3:2]
execute: /home/kingbase/cluster/kha/db/bin/arping -U 192.168.7.245 -I enp0s3 -w 1
ARPING 192.168.7.245 from 192.168.7.245 enp0s3
Sent 1 probes (1 broadcast(s))
Received 0 response(s)
ping vip 192.168.7.245 success ping times :[3], success times:[2]
ping vip 192.168.7.245 success ping times :[3], success times:[2]
wait kingbase recovery 5 sec...
start crontab kingbasecluster line number: [6]
Redirecting to /bin/systemctl restart crond.service
start crontab kingbasecluster line number: [3]
Redirecting to /bin/systemctl restart crond.service
......................
all started..
...
now we check again
=======================================================================
| ip | program| [status]
[ 192.168.7.243]| [kingbasecluster]| [active]
[ 192.168.7.248]| [kingbasecluster]| [active]
[ 192.168.7.243]| [kingbase]| [active]
[ 192.168.7.248]| [kingbase]| [active]
=======================================================================
2)查看集群节点状态
[kingbase@node1 bin]$ ./ksql -U SYSTEM -W 123456 prod -p 9999
ksql (V008R003C002B0270)
Type "help" for help.
prod=# show pool_nodes;
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay
---------+---------------+-------+--------+-----------+---------+------------+-------------------+-------------------
0 | 192.168.7.243 | 54321 | up | 0.500000 | standby | 0 | true | 0
1 | 192.168.7.248 | 54321 | up | 0.500000 | primary | 0 | false | 0
(2 rows)
prod=# select * from sys_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin |
state | sent_location | write_location | flush_location | replay_location | sync_priority | sync_state
------+----------+---------+------------------+---------------+-----------------+-------------+-------------------------------+--------------+---
--------+---------------+----------------+----------------+-----------------+---------------+------------
5539 | 10 | system | node243 | 192.168.7.243 | | 47872 | 2021-03-01 13:19:09.653137+08 | | st
reaming | 0/100000D0 | 0/100000D0 | 0/100000D0 | 0/100000D0 | 0 | async
(1 row)
[kingbase@node1 bin]$ ./ksql -U SYSTEM -W 123456 prod
ksql (V008R003C002B0270)
Type "help" for help.
prod=# select * from sys_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin |
state | sent_location | write_location | flush_location | replay_location | sync_priority | sync_state
------+----------+---------+------------------+---------------+-----------------+-------------+-------------------------------+--------------+---
5539 | 10 | system | node243 | 192.168.7.243 | | 47872 | 2021-03-01 13:19:09.653137+08 | | st
reaming | 0/100000D0 | 0/100000D0 | 0/100000D0 | 0/100000D0 | 0 | async
(1 row)
六、再次执行主备切换测试
1)停止主库数据库服务
[kingbase@node1 bin]$ ./sys_ctl stop -D ../data
waiting for server to shut down....... done
server stopped
2、查看备库数据库服务进程(切换成功)
[kingbase@node3 bin]$ ps -ef|grep kingbase
kingbase 22541 1 0 13:01 ? 00:00:00 /home/kingbase/cluster/kha/db/bin/kingbase -D /home/kingbase/cluster/kha/db/data
kingbase 22552 22541 0 13:01 ? 00:00:00 kingbase: logger process
kingbase 22563 22541 0 13:01 ? 00:00:00 kingbase: checkpointer process
kingbase 22564 22541 0 13:01 ? 00:00:00 kingbase: writer process
kingbase 22565 22541 0 13:01 ? 00:00:00 kingbase: stats collector process
root 23208 1 0 13:01 ? 00:00:00 ./kingbasecluster -n
root 23255 23208 0 13:01 ? 00:00:00 kingbasecluster: watchdog
root 23421 23208 0 13:02 ? 00:00:00 kingbasecluster: lifecheck
root 23423 23421 0 13:02 ? 00:00:00 kingbasecluster: heartbeat receiver
root 23424 23421 0 13:02 ? 00:00:00 kingbasecluster: heartbeat sender
kingbase 24571 22541 0 13:05 ? 00:00:00 kingbase: wal writer process
kingbase 24572 22541 0 13:05 ? 00:00:00 kingbase: autovacuum launcher process
kingbase 24573 22541 0 13:05 ? 00:00:00 kingbase: archiver process last was 00000002.history
kingbase 24574 22541 0 13:05 ? 00:00:00 kingbase: bgworker: syslogical supervisor
查看failover.log日志:
[kingbase@node3 log]$ tail -100 failover.log
-----------------2021-03-01 13:05:12 failover beging---------------------------------------
----failover-stats is %H = hostname of the new master node [192.168.7.243], %P = old primary node id [1], %d = node id[1], %h = host name [192.168.7.248], %O = old primary host[192.168.7.248] %m = new master node id [0], %M = old master node id [0], %D = database cluster path [/home/kingbase/cluster/kha/db/data].
----ping trust ip
ping trust ip 192.168.7.1 success
----determine whether the faulty db is master or standby
master down, let 192.168.7.243 become new primary.....
2021-03-01 13:05:14 del old primary VIP on 192.168.7.248
ssh connect host:192.168.7.248 success, will stop old primary db and del the vip
stop the old primary db
sys_ctl: PID file "/home/kingbase/cluster/kha/db/data/kingbase.pid" does not exist
Is server running?
DEL VIP NOW AT 2021-03-01 13:22:43 ON enp0s3
execute: [/sbin/ip addr del 192.168.7.245/24 dev enp0s3]
Oprate del ip cmd end.
2021-03-01 13:05:14 add VIP on 192.168.7.243
ADD VIP NOW AT 2021-03-01 13:05:15 ON enp0s3
execute: [/sbin/ip addr add 192.168.7.245/24 dev enp0s3 label enp0s3:2]
execute: /home/kingbase/cluster/kha/db/bin/arping -U 192.168.7.245 -I enp0s3 -w 1
ARPING 192.168.7.245 from 192.168.7.245 enp0s3
Sent 1 probes (1 broadcast(s))
Received 0 response(s)
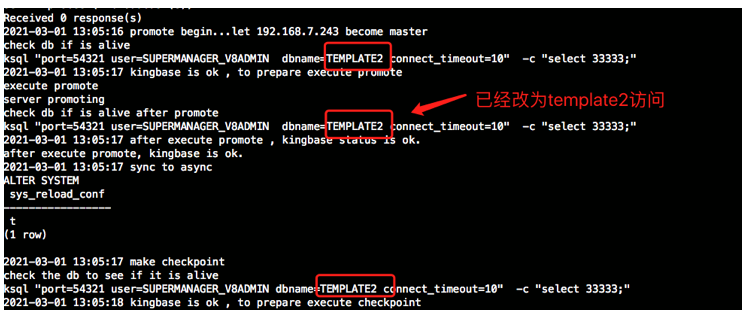
2021-03-01 13:05:16 promote begin...let 192.168.7.243 become master
check db if is alive
ksql "port=54321 user=SUPERMANAGER_V8ADMIN dbname=TEMPLATE2 connect_timeout=10" -c "select 33333;"
2021-03-01 13:05:17 kingbase is ok , to prepare execute promote
execute promote
server promoting
check db if is alive after promote
ksql "port=54321 user=SUPERMANAGER_V8ADMIN dbname=TEMPLATE2 connect_timeout=10" -c "select 33333;"
2021-03-01 13:05:17 after execute promote , kingbase status is ok.
after execute promote, kingbase is ok.
2021-03-01 13:05:17 sync to async
ALTER SYSTEM
sys_reload_conf
-----------------
t
(1 row)
2021-03-01 13:05:17 make checkpoint
check the db to see if it is alive
ksql "port=54321 user=SUPERMANAGER_V8ADMIN dbname=TEMPLATE2 connect_timeout=10" -c "select 33333;"
2021-03-01 13:05:18 kingbase is ok , to prepare execute checkpoint
execute checkpoint
CHECKPOINT
check the db to see if it is alive after execute checkpoint
ksql "port=54321 user=SUPERMANAGER_V8ADMIN dbname=TEMPLATE2 connect_timeout=10" -c "select 33333;"
2021-03-01 13:05:18 after execute checkpoint, kingbase is ok.
after execute checkpoint, kingbase is ok.
七、将原主库恢复为备库
1)在新主库上创建replication slots。
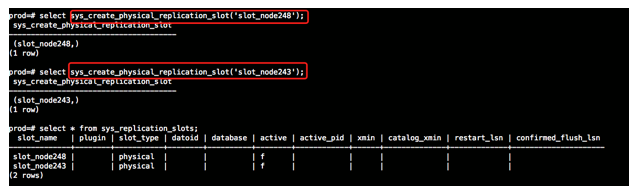
2)在原主库下创建recovery.conf文件后,sys_ctl手工启动数据库服务。

3)检查主备流复制状态。
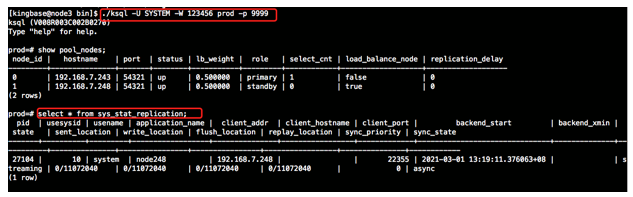
4)重新启动集群测试。
八、总结
对于KingbaseES R3集群的test库,多用于kingbasecluster和后台数据库服务的健康检查访问,请不要轻易删除。
九、附件
案例: 在没有在原主库data目录下创建recovery.conf文件,启动主库数据库服务。后创建了recovery.conf,再启动原主库以备库加入流复制失败,因为timeline与新主库不一致。采用sys_rewind工具重新将原主库加入集群。
1)查看原主库sys_log日志
=如下所示,备库数据库服务启动失败,因为timeline与新主库不一致=
[kingbase@node1 sys_log]$ tail -100f kingbase-2021-03-01_132943.log
LOG: database system was shut down in recovery at 2021-03-01 13:29:42 CST
LOG: entering standby mode
FATAL: requested timeline 2 is not a child of this server's history
DETAIL: Latest checkpoint is at 0/12000028 on timeline 1, but in the history of the requested timeline, the server forked off from that timeline at 0/11000098.
LOG: startup process (PID 10918) exited with exit code 1
LOG: aborting startup due to startup process failure
LOG: database system is shut down
2)在原主库执行sys_rewind加入集群
[kingbase@node1 bin]$ ./sys_rewind -D /home/kingbase/cluster/kha/db/data --source-server='host=192.168.7.243 port=54321 user=system dbname=PROD' -P -n
connected to server
datadir_source = /home/kingbase/cluster/kha/db/data
rewinding from last common checkpoint at 0/10000028 on timeline 1
find last common checkpoint start time from 2021-03-01 13:36:24.675116 CST to 2021-03-01 13:36:24.702727 CST, in "0.027611" seconds.
reading source file list
reading target file list
reading WAL in target
need to copy 298 MB (total source directory size is 363 MB)
Rewind datadir file from source
Get archive xlog list from source
Rewind archive log from source
59462/305222 kB (19%) copied
creating backup label and updating control file
syncing target data directory
rewind start wal location 0/10000028 (file 000000010000000000000010), end wal location 0/11070290 (file 000000020000000000000011). time from 2021-03-01 13:36:25.675116 CST to 2021-03-01 13:36:25.379386 CST, in "0.704270" seconds.
Done!
3)启动备库数据库服务
[kingbase@node1 bin]$ ./sys_ctl start -D ../data
server starting
[kingbase@node1 bin]$ LOG: redirecting log output to logging collector process
HINT: Future log output will appear in directory "/data/kingbase/cluster/r3/data/sys_log".
[kingbase@node1 bin]$ ps -ef|grep kingbase
.......
kingbase 11983 13899 0 13:31 pts/1 00:00:00 tail -100f kingbase-2021-03-01_132943.log
kingbase 13611 1 0 13:36 pts/0 00:00:00 /home/kingbase/cluster/kha/db/bin/kingbase -D ../data
kingbase 13614 13611 0 13:36 ? 00:00:00 kingbase: logger process
kingbase 13615 13611 0 13:36 ? 00:00:00 kingbase: startup process recovering 000000020000000000000011
kingbase 13619 13611 0 13:36 ? 00:00:00 kingbase: checkpointer process
kingbase 13620 13611 0 13:36 ? 00:00:00 kingbase: writer process
kingbase 13621 13611 0 13:36 ? 00:00:00 kingbase: wal receiver process streaming 0/11070EB8
kingbase 13622 13611 0 13:36 ? 00:00:00 kingbase: stats collector process
4)查询集群节点状态
# 主库查询:
prod=# select * from sys_replication_slots;
slot_name | plugin | slot_type | datoid | database | active | active_pid | xmin | catalog_xmin | restart_lsn | confirmed_flush_lsn
--------------+--------+-----------+--------+----------+--------+------------+------+--------------+-------------+---------------------
slot_node248 | | physical | | | t | 27104 | 2110 | | 0/11071688 |
slot_node243 | | physical | | | f | | | | |
(2 rows)
[kingbase@node3 bin]$ ./ksql -U SYSTEM -W 123456 prod -p 9999
ksql (V008R003C002B0270)
Type "help" for help.
prod=# select * from sys_stat_replication ;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin |
state | sent_location | write_location | flush_location | replay_location | sync_priority | sync_state
-------+----------+---------+------------------+---------------+-----------------+-------------+-------------------------------+--------------+--
27104 | 10 | system | node248 | 192.168.7.248 | | 22355 | 2021-03-01 13:19:11.376063+08 | | s
treaming | 0/11070FD0 | 0/11070FD0 | 0/11070FD0 | 0/11070FD0 | 0 | async
(1 row)
prod=# show pool_nodes;
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay
---------+---------------+-------+--------+-----------+---------+------------+-------------------+-------------------
0 | 192.168.7.243 | 54321 | up | 0.500000 | primary | 1 | true | 0
1 | 192.168.7.248 | 54321 | up | 0.500000 | standby | 0 | false | 0
(2 rows)
KingbaseES R3 集群删除test库导致主备无法切换问题的更多相关文章
- KingbaseES R3集群在线删除数据节点案例
案例说明: kingbaseES R3集群一主多从的架构,一般有两个节点是集群的管理节点,所有的节点都可以为数据节点:对于非管理节点的数据节点可以在线删除:但是对于管理节点,无法在线删除,如果删除管理 ...
- KingbaseES R3 集群cluster日志切割和清理案例
案例说明: 对于KingbaseES R3集群的cluster日志默认系统是不做切割和清理的,随着运行时长的增加,日志将增长为一个非常大的文件,占用比较大的磁盘空间,并且在分析问题读取大文件时效率很低 ...
- KingbaseES R3 集群主库归档失败案例
案例说明: 本案例用于KingbaseES R3集群归档进程归档日志失败的处理,对于一线的生产环境具有 一定的参考意义. 数据库版本: TEST=# select version(); VERSION ...
- KingbaseES R3 集群一键修改集群用户密码案例
案例说明: 在KingbaseES R3集群的最新版本中增加了kingbase_monitor.sh一键修改集群用户密码的功能,本案例是对此功能的测试. kingbaseES R3集群一键修改密码说明 ...
- kingbaseES R3 集群修改data路径测试案例
案例说明: 默认KingbaseES R3集群部署后,数据存储目录(data)在/home/kingbase下,部署时不能更改:本案例是在部署完成后,迁移data目录到其他指定的存储位置. 数据库版本 ...
- KingbaseES R3 集群修改system用户密码方案
方案说明: 对于kingbaseES R3集群修改system密码相比单机环境有一定的复杂性,需要修改的位置如下: 1)数据库中system用户密码,可以用alter user命令修改 2)在reco ...
- KingbaseES R3 集群主备切换信号量(semctl)错误故障分析案例
案例说明: 某项目KingbaseES R3 一主一备流复制集群在主备切换测试中出现故障,导致主备无法正常切换:由于bm要求,数据库相关日志无法从主机中获取,只能在现场进行分析:通过对比主备切换时的时 ...
- KingbaseES R6 集群主机锁冲突导致的主备切换案例
案例说明: 主库在业务高峰期间,客户执行建表等DDL操作,主库产生"AccessExclusiveLock "锁,导致大量的事务产生锁冲突,大量的会话堆积,客户端session ...
- KingbaseES V8R3集群维护案例之---在线添加备库管理节点
案例说明: 在KingbaseES V8R3主备流复制的集群中 ,一般有两个节点是集群的管理节点,分为master和standby:如对于一主二备的架构,其中有两个节点是管理节点,三个数据节点:管理节 ...
随机推荐
- MySQL进行 批量插入,批量删除,批量更新,批量查询
1.批量插入 ServiceImpl层 List<Person> addPeople = new ArrayList<>(); //addPeople存放多个Person对象 ...
- NC50965 Largest Rectangle in a Histogram
NC50965 Largest Rectangle in a Histogram 题目 题目描述 A histogram is a polygon composed of a sequence of ...
- NC24017 [USACO 2016 Jan S]Angry Cows
NC24017 [USACO 2016 Jan S]Angry Cows 题目 题目描述 Bessie the cow has designed what she thinks will be the ...
- 异构图神经网络笔记-Heterogeneous Graph Neural Network(KDD19)
自己讲论文做的异构图神经网络的ppt.再转变成博客有点麻烦,所以做成图片笔记. 论文链接:https://arxiv.org/abs/1903.07293
- for循环 --和复合赋值
阶乘 1.n!=1x2x3x4x...xn 2.写出一个程序,让用户输入n,然后计算输出n! *变量: *显然读用户的输入需要一个int的n,然后计算的结果需要用一个变量保存,可以是int的facto ...
- github package的使用教程
一.写在前面 上一次,笔者向大家介绍了把gitlab仓库作为npm私包的使用方法,具体的详见我的博文地址https://www.cnblogs.com/cnroadbridge/p/16406476. ...
- 集合-list常用方法总结
每个方法使用见下方代码详解 点击查看代码 ArrayList list = new ArrayList(); list.add("AA"); list.add(123); list ...
- day07 聊天室-1_集合
聊天室(续) 实现服务端发送消息给客户端 在服务端通过Socket获取输出流,客户端获取输入流,实现服务端将消息发送给客户端. 这里让服务端直接将客户端发送过来的消息再回复给客户端来进行测试. 服务端 ...
- 面试官:你确定 Redis 是单线程的进程吗?
作者:小林coding 计算机八股文网站:https://xiaolincoding.com 大家好,我是小林. 这次主要分享 Redis 线程模型篇的面试题. Redis 是单线程吗? Redis ...
- 浅析golang shellcode加载器
最近也是学习了一下有关shellcode进程注入的操作,简单分享一下通过golang进行实现shellcode加载器的免杀思路. 杀软的查杀方式 静态查杀:查杀的方式是结合特征码,对文件的特征段如Ha ...