Python数据分析--Numpy常用函数介绍(3)
摘要:先汇总相关股票价格,然后有选择地对其分类,再计算移动均线、布林线等。
一、汇总数据
汇总整个交易周中从周一到周五的所有数据(包括日期、开盘价、最高价、最低价、收盘价,成交量等),由于我们的数据是从2020年8月24日开始导出,数据多达420条,先截取部分时间段的数据,不妨先读取开始20个交易日的价格。代码如下:
import numpy as np
from datetime import datetime def datestr2num(s): #定义一个函数
return datetime.strptime(s.decode('ascii'),"%Y-%m-%d").date().weekday()
#decode('ascii') 将字符串s转化为ascii码 #读取csv文件 ,将日期、开盘价、最低价、最高价、收盘价、成交量等全部读取
dates, opens, high, low, close,vol=np.loadtxt('data.csv',delimiter=',', usecols=(1,2,3,4,5,6),converters={1:datestr2num},unpack=True) #按顺序对应好data.csv与usecols=(1,2,3,4,5,6)中的列
#获取20个交易日的数据
closes = close[0:20] #实际存取下标是0-19
dateslist = dates[0:20]
print(closes) #打印出closes数列
print(dateslist)
这样就把data.csv中对应的日期、开盘价、最高价、最低价、收盘价,成交量等分别存入到dates, opens, high, low, close,vol中。由于后面示例只统计20个交易日数据,所以closes = close[0:20] ,即截取close中前20个数据。
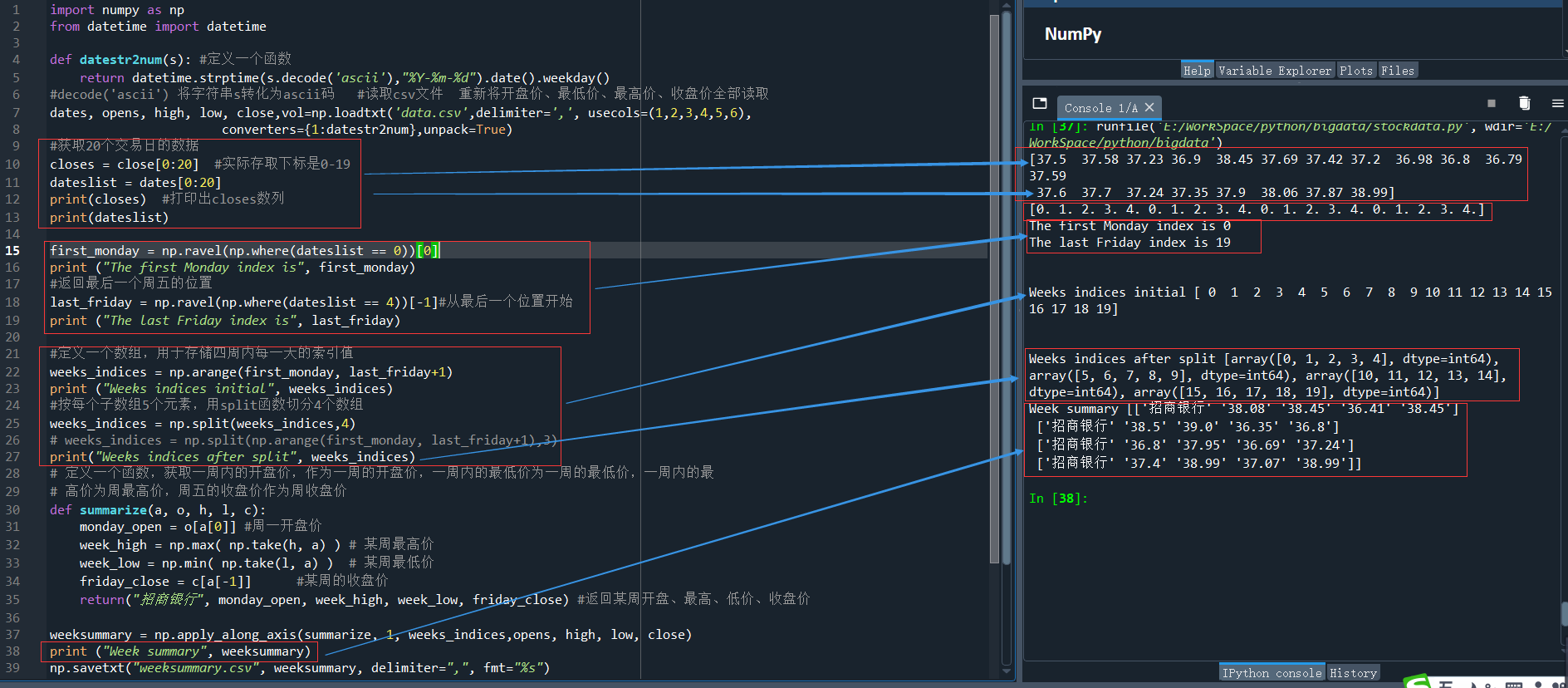
运行结果:
[37.5 37.58 37.23 36.9 38.45 37.69 37.42 37.2 36.98 36.8 36.79 37.59 37.6 37.7 37.24 37.35 37.9 38.06 37.87 38.99]
[0. 1. 2. 3. 4. 0. 1. 2. 3. 4. 0. 1. 2. 3. 4. 0. 1. 2. 3. 4.]
即20个交易日的收盘价和所属的星期(0表示周一、4表示周五)。
分别看一下最开始周一的下标和最后一个周五的下标
first_monday = np.ravel(np.where(dateslist == 0))[0]
print ("The first Monday index is", first_monday)
#返回最后一个周五的位置
last_friday = np.ravel(np.where(dateslist == 4))[-1]
print ("The last Friday index is", last_friday)
print('\n')
运行结果:
The first Monday index is 0
The last Friday index is 19
定义一个数组,用于存储20个交易日的索引值
weeks_indices = np.arange(first_monday, last_friday+1)
print ("Weeks indices initial", weeks_indices)
按5个交易日,分成4周,对20个交易日分成4周:
weeks_indices = np.split(weeks_indices,4)
print("Weeks indices after split", weeks_indices)
Weeks indices initial [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19]
Weeks indices after split [array([0, 1, 2, 3, 4], dtype=int64), array([5, 6, 7, 8, 9], dtype=int64), array([10, 11, 12, 13, 14], dtype=int64), array([15, 16, 17, 18, 19], dtype=int64)]
NumPy中,数组的维度也被称作轴。apply_along_axis 函数会调用另外一个由我们给出的函数,作用于每一个数组元素上,数组中有4个元素,分别对应于示例数据中的4个星期,元素中的索引值对应于示例数据中的1天。在调用apply_along_axis 时提供我们自定义的函数名summarize,并指定要作用的轴或维度的编号(如取1)、目标数组以及可变数量的summarize函数的参数,同时进行保存。
# 定义一个函数,该函数将为每一周的数据返回一个元组,包含这一周的开盘价、最高价、最低价和收盘价,类似于每天的盘后数据
def summarize(a, o, h, l, c):
monday_open = o[a[0]] #周一开盘价
week_high = np.max( np.take(h, a) ) # 某周最高价
week_low = np.min( np.take(l, a) ) # 某周最低价
friday_close = c[a[-1]] #某周的收盘价 return("招商银行", monday_open, week_high, week_low, friday_close) #返回某周开盘、最高、低价、收盘价 weeksummary = np.apply_along_axis(summarize, 1, weeks_indices,opens, high, low, close)
print ("Week summary", weeksummary) np.savetxt("weeksummary.csv", weeksummary, delimiter=",", fmt="%s")
实际运行如下:
二、均线
1、波动幅度均值(ATR)
ATR(Average True Range,真实波动幅度均值)是一个用来衡量股价波动性的技术指标。ATR是基于N个交易日的最高价和最低价进行计算的,通常取最近20个交易日。
(1) 前一个交易日的收盘价。 previousclose = c[-N -1: -1]
对于每一个交易日,计算以下各项。
h – l 当日最高价和最低价之差。 h – previousclose 当日最高价和前一个交易日收盘价之差。 previousclose – l 前一个交易日收盘价和当日最低价之差。
(2) 用NumPy中的 maximum 函数返回上述三个中的最大值。 truerange = np.maximum(h - l, h - previousclose, previousclose - l)
(3) 创建一个长度为 N 的数组 atr ,并初始化数组元素为0。atr = np.zeros(N)
(4) 这个数组的首个元素就是 truerange 数组元素的平均值。atr[0] = np.mean(truerange)
5)计算出每个交易日的波动幅度:
for i in range(1, N):
atr[i] = (N - 1) * atr[i - 1] + truerange[i]
atr[i] /= N
示例代码如下:
import numpy as np
from datetime import datetime def datestr2num(s): #定义一个函数
return datetime.strptime(s.decode('ascii'),"%Y-%m-%d").date().weekday() dates, opens, high, low, close,vol=np.loadtxt('data.csv',delimiter=',', usecols=(1,2,3,4,5,6),
converters={1:datestr2num},unpack=True)
closes = close[0:20] #实际存取下标是0-19
dateslist = dates[0:20]
first_monday = np.ravel(np.where(dateslist == 0))[0]
last_friday = np.ravel(np.where(dateslist == 4))[-1]#从最后一个位置开始
weeks_indices = np.split(np.arange(first_monday, last_friday+1),4) #波动幅度均值(ATR)
N = 20
h = high[-N:]
l = low[-N:] print ("len(high)", len(h), "len(low)", len(l))
#print ("Close", close)
#前一日的收盘价数列
previousclose = close[-N-1: -1]
print ("len(previousclose)", len(previousclose))
print ("Previous close", previousclose) #用NumPy中的maximum函数,在 最高-最低,最高-昨日收盘,昨日收盘 三个数据选择最大
truerange = np.maximum(h-l,h-previousclose,previousclose)
print ("True range", truerange) atr = np.zeros(N) # 创建一个长度为 N 的数组 atr ,并初始化数组元素为0
atr[0] = np.mean(truerange) # 数组的首个元素设定为truerange数组元素的平均值
for i in range(1, N): #循环,计算每个交易日的波幅,并保存
atr[i] = (N - 1) * atr[i - 1] + truerange[i]
atr[i] /= N
print ("ATR", atr)
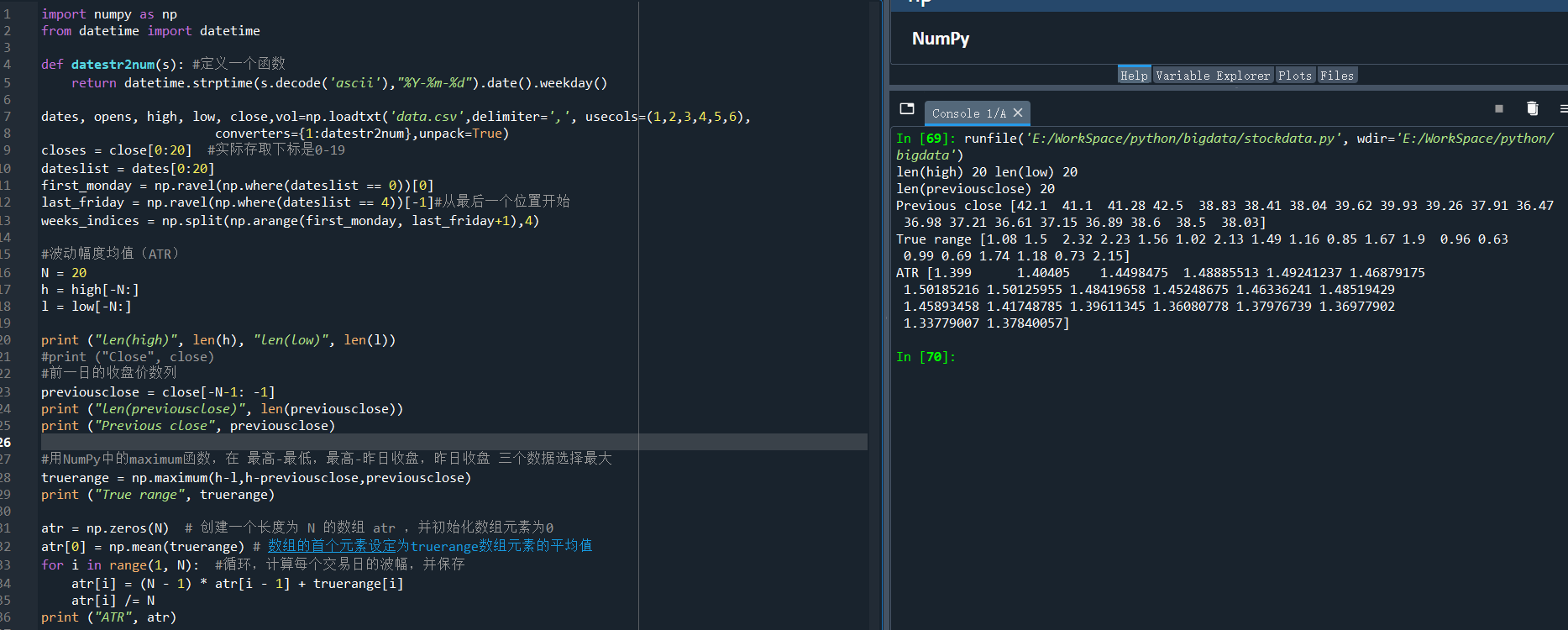
运行结果:
len(high) 20 len(low) 20
len(previousclose) 20
Previous close [42.1 41.1 41.28 42.5 38.83 38.41 38.04 39.62 39.93 39.26 37.91 36.47 36.98 37.21 36.61 37.15 36.89 38.6 38.5 38.03]
True range [1.08 1.5 2.32 2.23 1.56 1.02 2.13 1.49 1.16 0.85 1.67 1.9 0.96 0.63 0.99 0.69 1.74 1.18 0.73 2.15]
ATR [1.399 1.40405 1.4498475 1.48885513 1.49241237 1.46879175 1.50185216 1.50125955 1.48419658 1.45248675 1.46336241
1.48519429 1.45893458 1.41748785 1.39611345 1.36080778 1.37976739 1.36977902 1.33779007 1.37840057]
2、移动均线:股市中最常见的是指标,移动平均线只需要少量的循环和均值函数即可计算得出。简单移动平均线是计算与等权重的指示函数的卷积。
简单移动平均线(simple moving average)通常用于分析时间序列上的数据。我们按照时间序列,并N个周期数据的均值。
(1) 使用 ones 函数创建一个长度为 N 的元素均初始化为1的数组,然后对整个数组除以 N ,即可得到权重,比如 5日均线,即N=5,则平均每天的权重都为0.2.
N = 5
weights = np.ones(N) / N
print ("Weights", weights)
(2)使用 convolve 函数调用上述的权重值
sma = np.convolve(weights, c)[N-1:-N+1]
从 convolve 函数返回的数组中,取出中间的长度为N的部分,下面的代码将创建 一个存储时间值的数组
N = 5
weights = np.ones(N) / N
print ("Weights", weights) sma = np.convolve(weights, close)[N-1:-N+1]
print(sma)
print(len(sma))
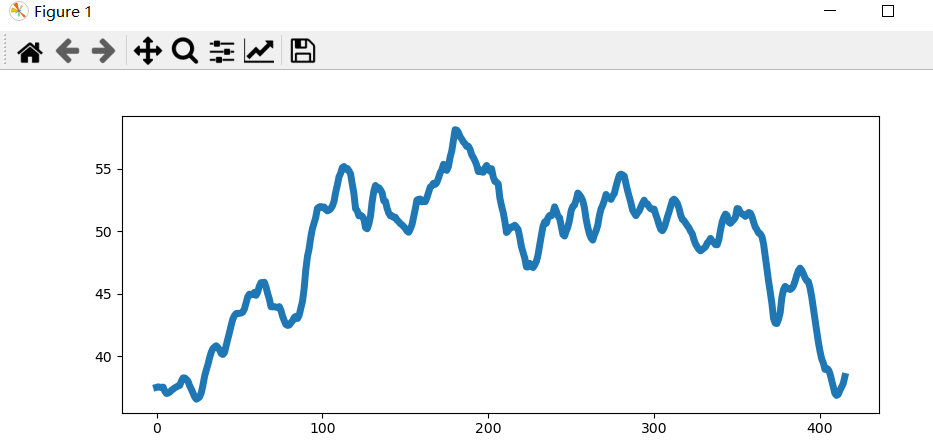
运行结果如下,可以看到,导出的420个数据,通过计算,得到的均线数组有416个。

很明显sma是一个数列,用前期matplotlib中的函数,可以绘制画面,增加如下代码:
import matplotlib.pyplot as plt
#省略上述代码 plt.plot(sma, linewidth=5)
运行结果如下:
3、指数移动平均线
指数移动平均线(exponential moving average)是另一种技术指标。指数移动平均线使用的权重是指数衰减的。对历史数据点赋予的权重以指数速度减小,但不会到达0。在计算权重的过程中使用 exp 和 linspace 函数。
1)先了解numpy中的exp 和 linspace 函数
x = np.arange(5)
y = np.arange(10)
print ("Exp", np.exp(x)) # exp 函数可以计算出每个数组元素的指数
print ("Exp", np.exp(y))
运行结果:
ExpX [ 1. 2.71828183 7.3890561 20.08553692 54.59815003]
ExpY [1.00000000e+00 2.71828183e+00 7.38905610e+00 2.00855369e+01 5.45981500e+01 1.48413159e+02 4.03428793e+02 1.09663316e+03 2.98095799e+03 8.10308393e+03]
可以看出,exp()函数接受一个数列,计算出每个数组元素的指数。
print( "Linspace", np.linspace(-1, 0, 5))
运行结果:
Linspace [-1. -0.75 -0.5 -0.25 0. ]
linspace中有三个参数,其中前2个是一个范围:一个起始值和一个终止值参数,后一个是生成的数组元素的个数。
2)计算指数移动平均线
利用上述两个函数对权重进行计算:weights = np.exp(np.linspace(-1. , 0. , N))
全部代码如下:
import numpy as np
from datetime import datetime
import matplotlib.pyplot as plt
from matplotlib.pyplot import show def datestr2num(s): #定义一个函数
return datetime.strptime(s.decode('ascii'),"%Y-%m-%d").date().weekday() dates, opens, high, low, close,vol=np.loadtxt('data.csv',delimiter=',', usecols=(1,2,3,4,5,6),
converters={1:datestr2num},unpack=True) N = 5
"""
weights = np.ones(N) / N
print ("Weights", weights)
sma = np.convolve(weights, close)[N-1:-N+1]
print(sma)
print(len(sma))
plt.plot(sma, linewidth=5)
"""
weights = np.exp(np.linspace(-1., 0., N)) #
weights /= weights.sum() #对权重值做归一化处理
print( "Weights", weights)
ema = np.convolve(weights, close)[N-1:-N+1]
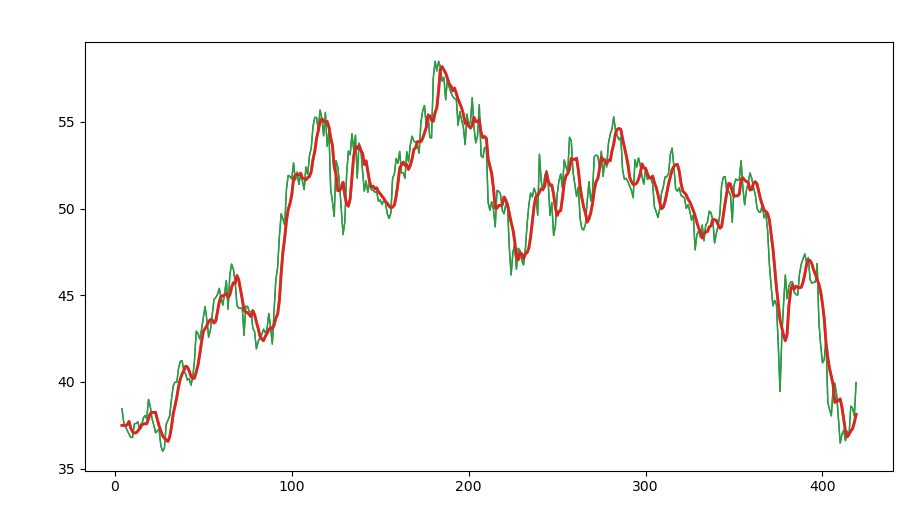
#print(ema) t = np.arange(N - 1, len(close))
plt.plot (t, close[N-1:], lw=1.0) #收盘价绘制曲线图
plt.plot (t, ema, lw=2.0) #按权重计算均线曲线图
show()
运行结果:
Python数据分析--Numpy常用函数介绍(3)的更多相关文章
- Python数据分析--Numpy常用函数介绍(2)
摘要:本篇我们将以分析历史股价为例,介绍怎样从文件中载入数据,以及怎样使用NumPy的基本数学和统计分析函数.学习读写文件的方法,并尝试函数式编程和NumPy线性代数运算,来学习NumPy的常用函数. ...
- Python数据分析--Numpy常用函数介绍(4)--Numpy中的线性关系和数据修剪压缩
摘要:总结股票均线计算原理--线性关系,也是以后大数据处理的基础之一,NumPy的 linalg 包是专门用于线性代数计算的.作一个假设,就是一个价格可以根据N个之前的价格利用线性模型计算得出. 前一 ...
- Python数据分析--Numpy常用函数介绍(5)--Numpy中的相关性函数
摘要:NumPy中包含大量的函数,这些函数的设计初衷是能更方便地使用,掌握解这些函数,可以提升自己的工作效率.这些函数包括数组元素的选取和多项式运算等.下面通过实例进行详细了解. 前述通过对某公司股票 ...
- Python数据分析--Numpy常用函数介绍(6)--Numpy中矩阵和通用函数
在NumPy中,矩阵是 ndarray 的子类,与数学概念中的矩阵一样,NumPy中的矩阵也是二维的,可以使用 mat . matrix 以及 bmat 函数来创建矩阵. 一.创建矩阵 mat 函数创 ...
- Python数据分析--Numpy常用函数介绍(9)-- 与线性代数有关的模块linalg
numpy.linalg 模块包含线性代数的函数.使用这个模块,可以计算逆矩阵.求特征值.解线性方程组以及求解行列式等.一.计算逆矩阵 线性代数中,矩阵A与其逆矩阵A ^(-1)相乘后会得到一个单位矩 ...
- Python数据分析--Numpy常用函数介绍(6)--Numpy中与股票成交量有关的计算
成交量(volume)是投资中一个非常重要的变量,它是指在某一时段内具体的交易数,可以在分时图中绘制,包括日线图.周线图.月线图甚至是5分钟.30分钟.60分钟图中绘制. 股票市场成交量的变化反映了资 ...
- Python数据分析--Numpy常用函数介绍(9)--Numpy中几中常见的图形
在NumPy中,所有的标准三角函数如sin.cos.tan等均有对应的通用函数. 一.利萨茹曲线 (Lissajous curve)利萨茹曲线是一种很有趣的使用三角函数的方式(示波器上显示出利萨茹曲线 ...
- Python数据分析-Numpy数值计算
Numpy介绍: NumPy是高性能科学计算和数据分析的基础包.它是pandas等其他各种工具的基础. NumPy的主要功能: 1)ndarray,一个多维数组结构,高效且节省空间 2)无需循环对整组 ...
- Python数据分析——numpy基础简介
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:基因学苑 NumPy(Numerical Python的简称)是高性 ...
随机推荐
- 一个动态波浪纹Android界面
IndexActivity.java package com.example.rubikrobot; import androidx.appcompat.app.AppCompatActivity; ...
- PAT B1002写出这个数
读入一个正整数 n,计算其各位数字之和,用汉语拼音写出和的每一位数字. 输入格式: 每个测试输入包含 1 个测试用例,即给出自然数 n 的值.这里保证 n 小于 1. 输出格式: 在一行内输出 n 的 ...
- Java List转为Object组
代码: private Object[] ListToObject(List<String> list){ Object [] tem = new Object[]{}; int size ...
- java基础-多线程-线程组
线程组 * Java中使用ThreadGroup来表示线程组,它可以对一批线程进行分类管理,Java允许程序直接对线程组进行控制. * 默认情况下,所有的线程都属于主线程组. * public fi ...
- Static in C++
Static in C++ static根据上下文会有两种含义,他们的区别如下 **在类class或者是在结构体struct 外 **使用static 类外的static修饰的符号在link阶段是局部 ...
- 在 Mac 上开发 .NET MAUI
.NET 多平台应用程序 UI (.NET MAUI) 是一个跨平台框架,用于使用 C# 和 XAML 创建本机移动和桌面应用程序,这些应用程序可以从单个共享代码库在 Android.iOS.macO ...
- docker中mysql导入sql文件
1.先将文件导入到容器 docker cp **.sql [容器名]:/root/ 2.进入容器 docker exec -ti [容器名/ID]/bin/bash 3.将文件导入数据库 mysql ...
- 如何基于 ZEGO SDK 实现 Windows 一对一音视频聊天应用
互联网发展至今,实时视频和语音通话越来越被大众所依赖. 今天,我们将会继续介绍如何基于ZEGO SDK实现音视频通话功能,前两篇文章分别介绍了Android,Flutter平台的实现方式,感兴趣的小伙 ...
- QT的MYSQL驱动库编译
QT的MYSQL驱动库编译 需要准备QT的源码Src,此次编译64位 在QTCreator中打开mysql.pro 修改两个pro 文件,下图为改好 1.mysql.pro TARGET = qsql ...
- 将mysql主从复制由ABB模式修改为ABC模式
最近遇到一个奇葩的需求,需要将mysql的主从复制模式由ABB修改为ABC,恰好这个mysql集群没有开启GTID,当时是在B上做了一次全量备份,然后使用该全量备份恢复C的方式进行的.做完之后在想有没 ...