有向图的拓扑排序——DFS
在有向图的拓扑排序——BFS这篇文章中,介绍了有向图的拓扑排序的定义以及使用广度优先搜索(BFS)对有向图进行拓扑排序的方法,这里再介绍另一种方法:深度优先搜索(DFS)。
算法
考虑下面这张图:
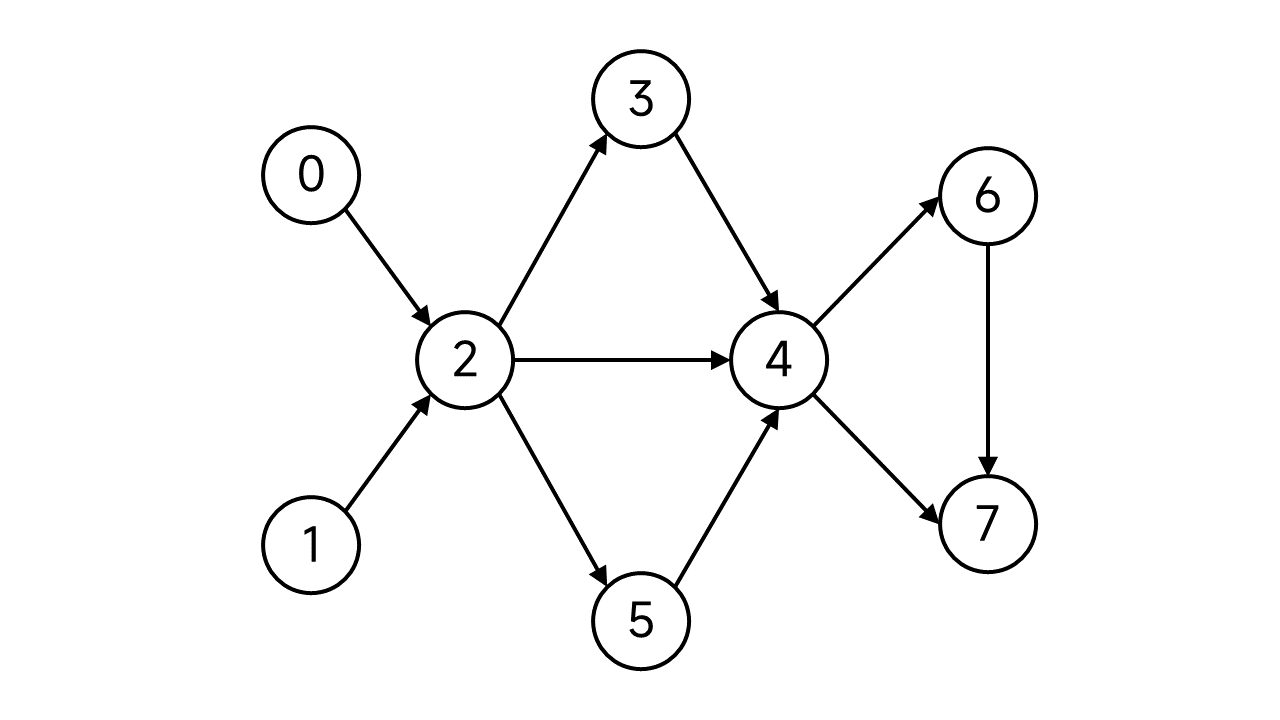
首先,我们需要维护一个栈,用来存放DFS到的节点。另外规定每个节点有两个状态:未访问(这里用蓝绿色表示)、已访问(这里用黑色表示)。
任选一个节点开始DFS,比如这里就从0开始吧。
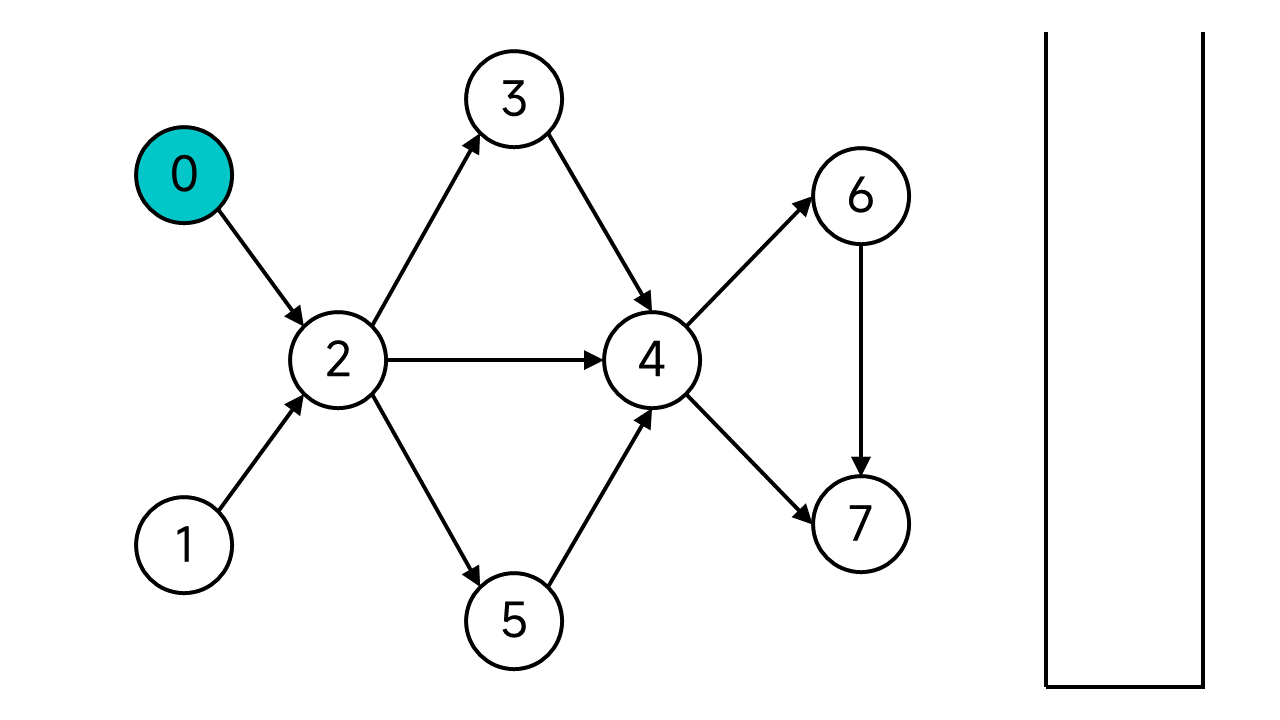
首先将节点0的状态设为已访问,然后节点0的邻居(节点0的出边指向的节点)共有1个:节点2,它是未访问状态,于是顺下去访问节点2。
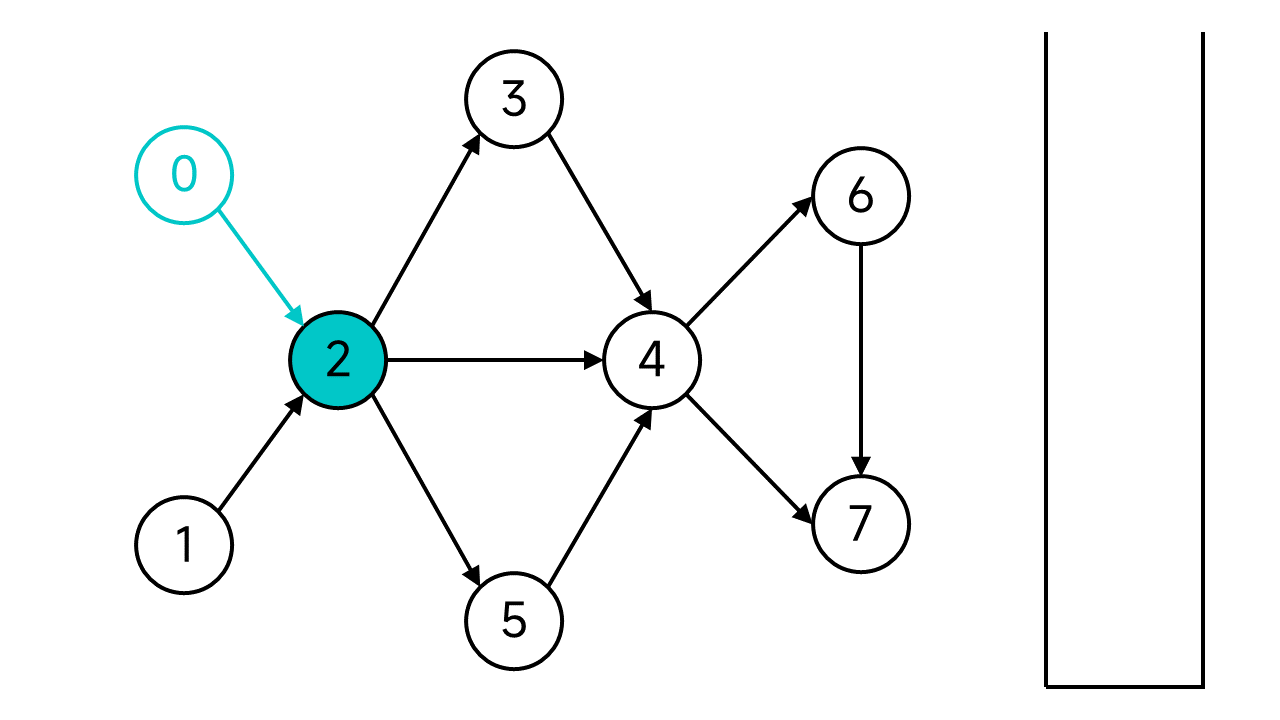
节点2的状态也设为已访问。节点2有3个邻居:3、4、5,都是未访问状态,不妨从3开始。一直这样访问下去,直到访问到没有出边的节点7。
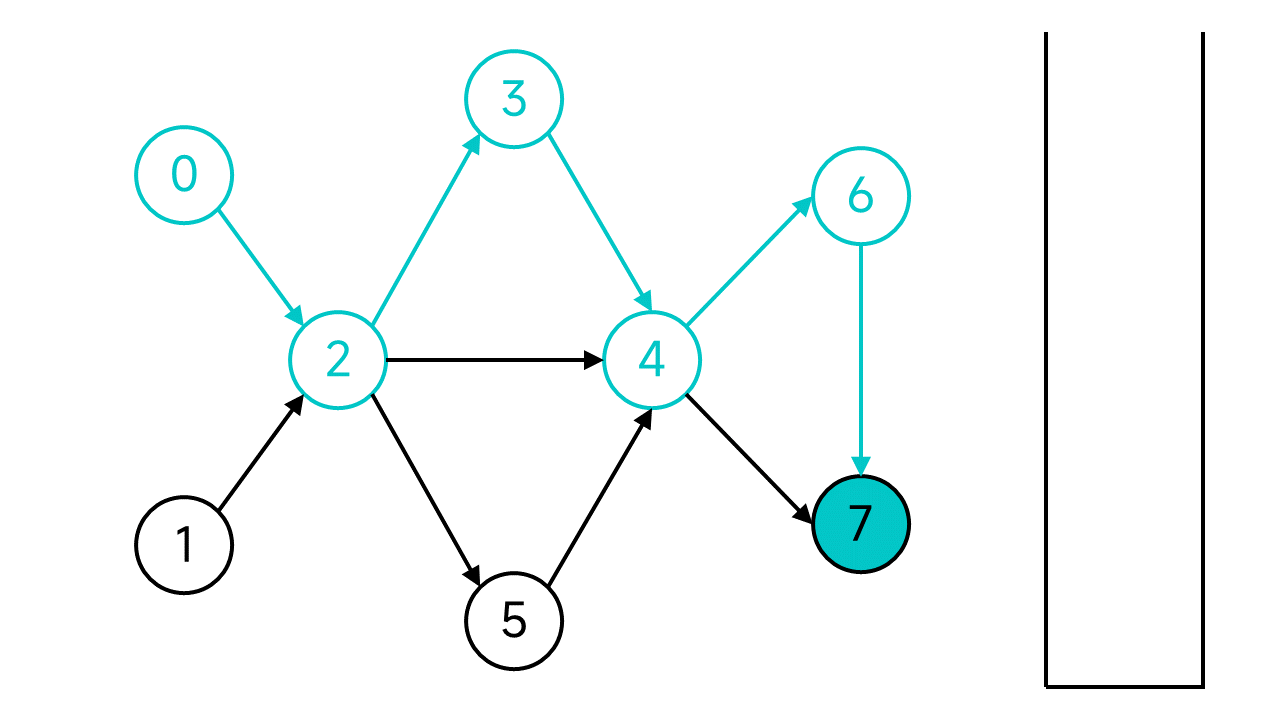
节点7没有出边了,这时候就将节点7入栈。
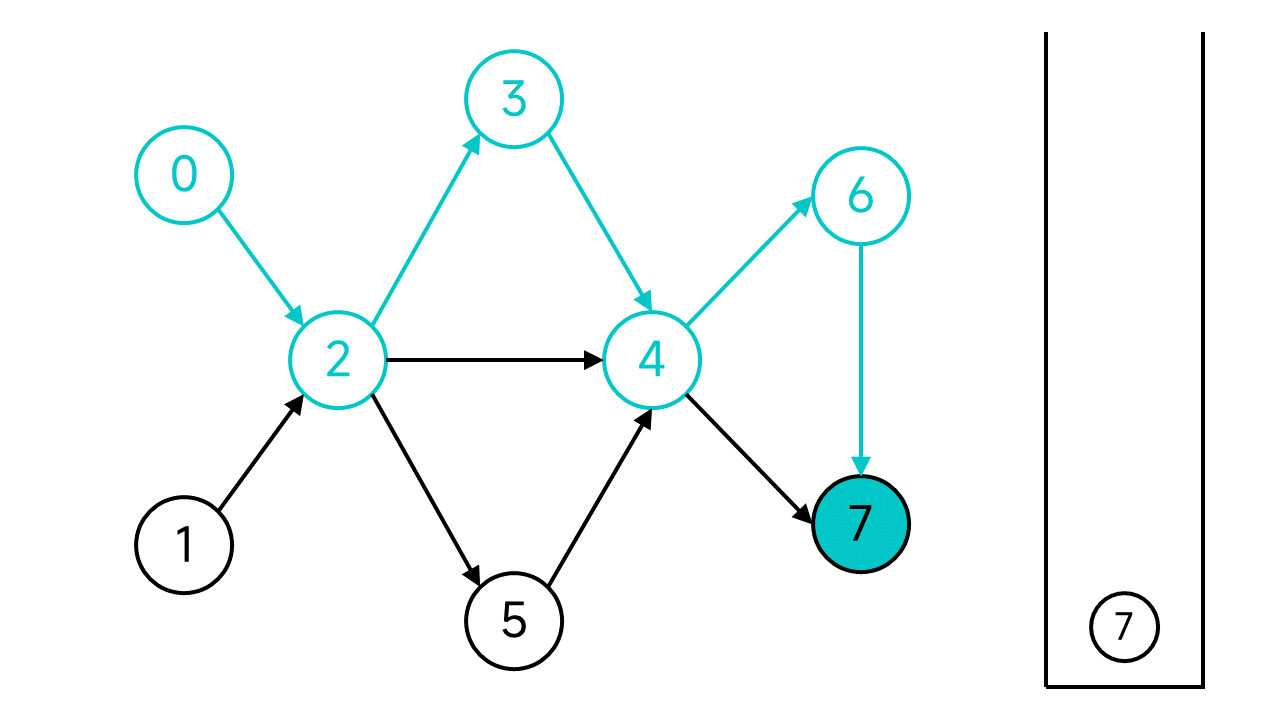
退回到节点6,虽然6还有邻居,但是唯一的邻居节点7是已访问状态,也入栈。再次退回,节点4的两个邻居也都已访问,依旧入栈并后退。以此类推,退回到节点2。
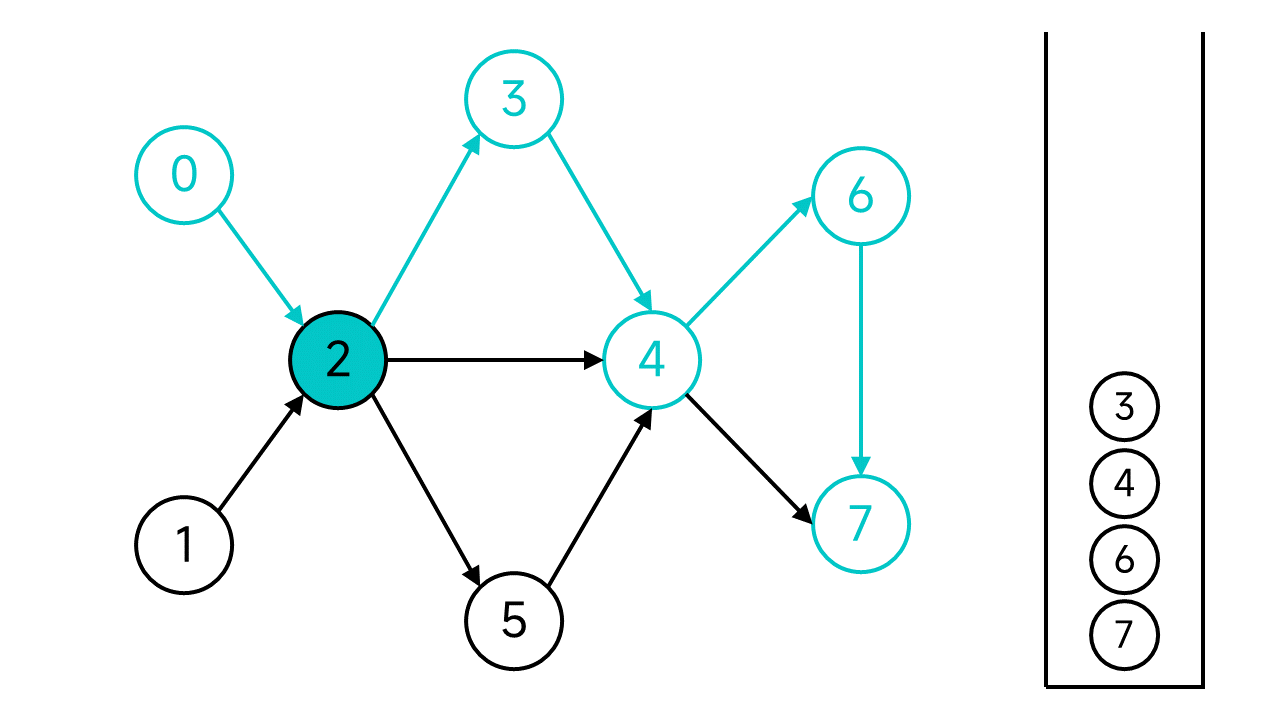
节点2有3个邻居,其中节点3和4已访问,但是节点5还未访问,访问节点5。
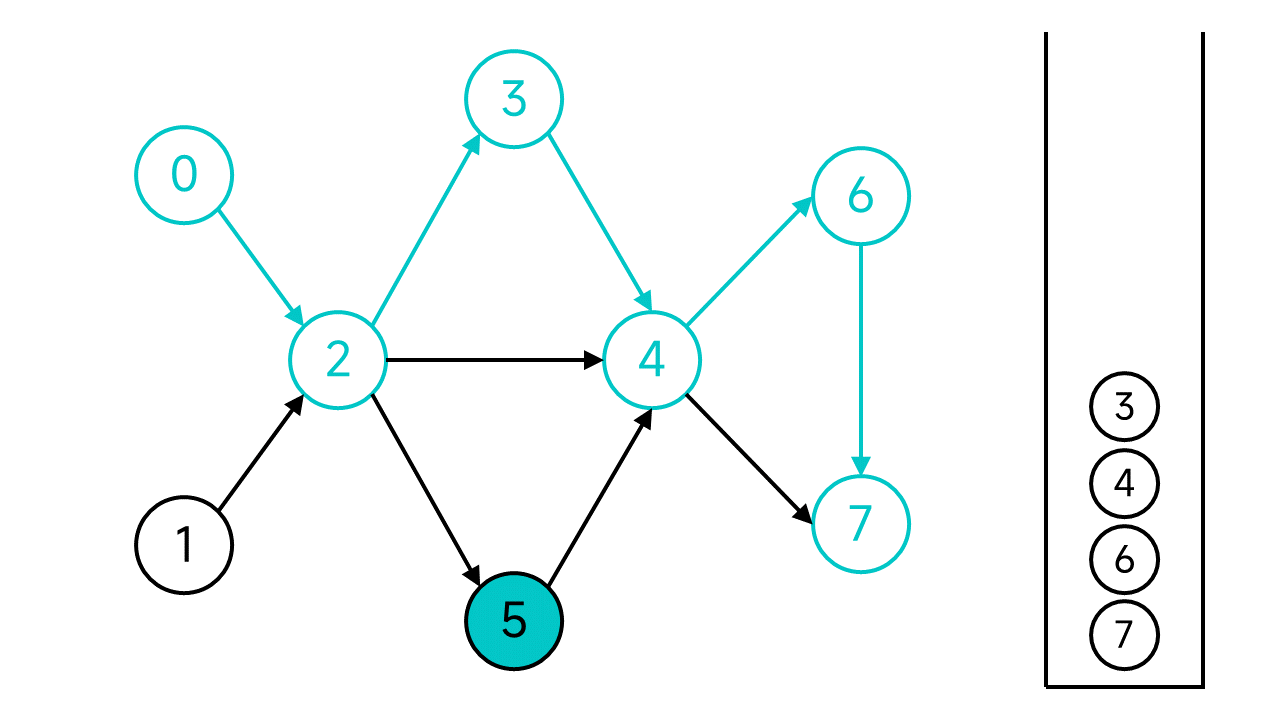
接下来的步骤是一样的,不再赘述了,直接退回到节点0并将0入栈。
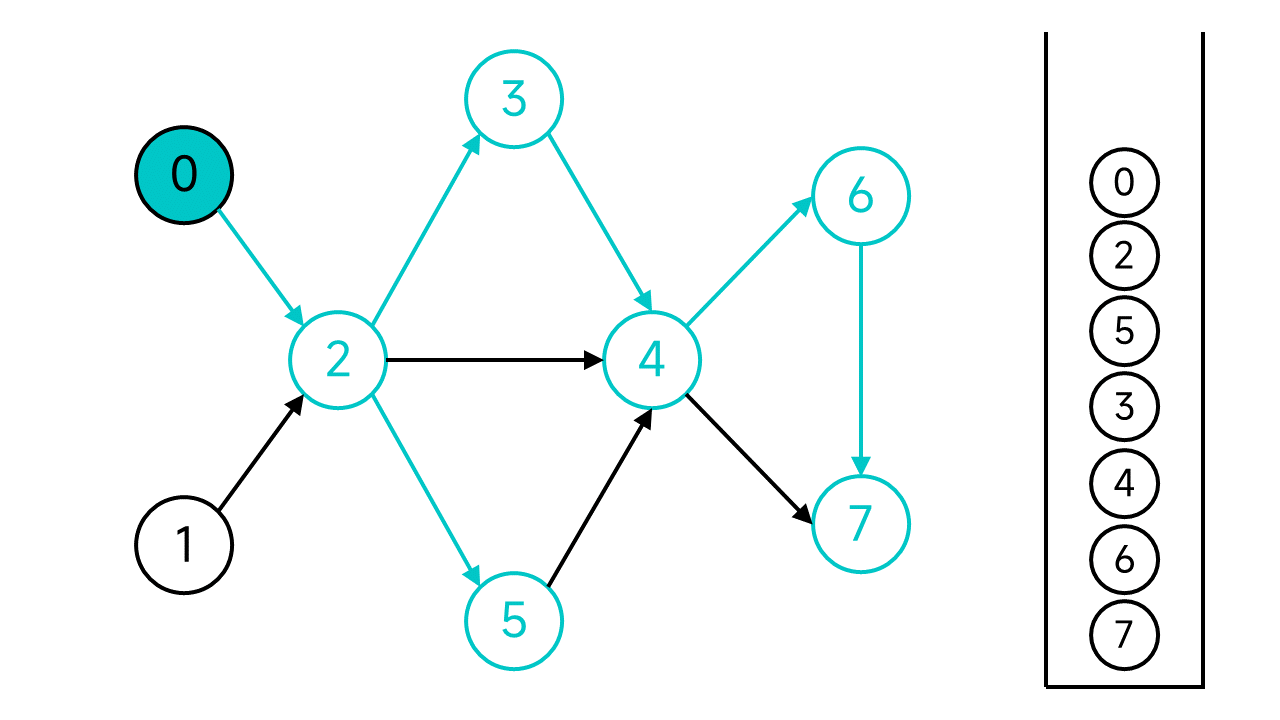
现在,从节点0开始的DFS宣告结束,但是图中还有未访问的节点:节点1,从节点1继续开始DFS。
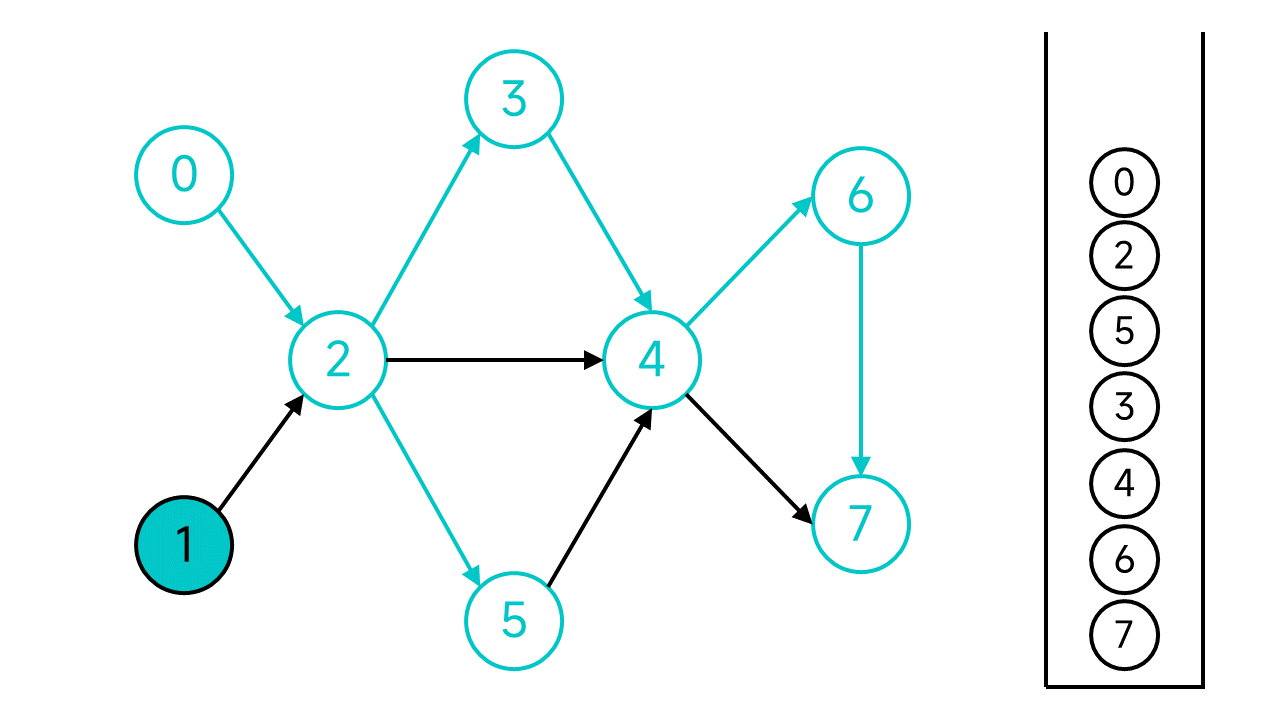
节点1的邻居节点2已经访问过了,直接将节点1入栈。
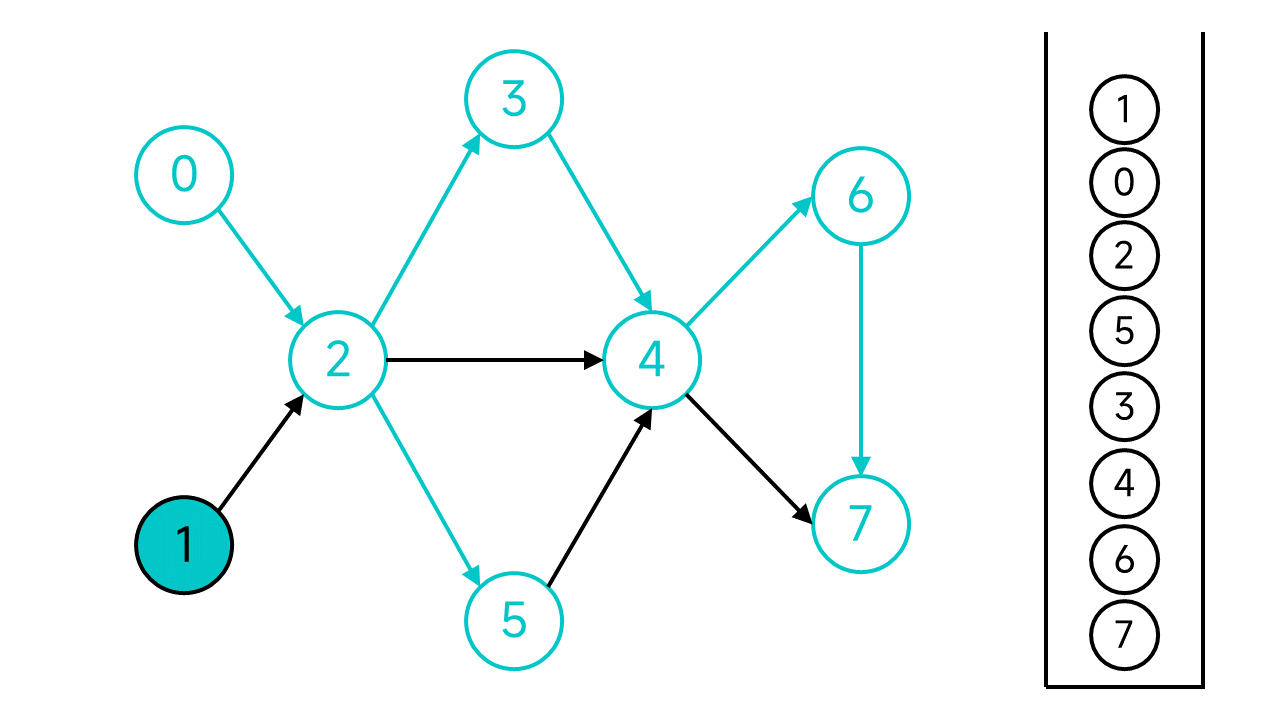
至此,整个DFS过程宣告结束。从栈顶到栈底的节点序列1 0 2 5 3 4 6 7就是整个图的一个拓扑排序序列。
实现
这里同样使用类型别名node_t代表节点序号unsigned long long:
using node_t = unsigned long long;
同样使用邻接表来存储图结构,整个图的定义如下:
class Graph {
unsigned long long n;
vector<vector<node_t>> adj;
protected:
void dfs(node_t cur, vector<bool> &visited, stack<node_t> &nodeStack);
public:
Graph(initializer_list<initializer_list<node_t>> list) : n(list.size()), adj({}) {
for (auto &l : list) {
adj.emplace_back(l);
}
}
vector<node_t> toposortDfs();
};
DFS
函数dfs的参数及说明如下:
cur:当前访问的节点。visited:存放各个节点状态的数组,false表示未访问,true表示已访问。初始化为全为false。nodeStack:存放节点的栈。
整个过程如下:
- 首先,我们需要将当前节点的状态设为已访问:
visited[cur] = true;
- 依次检查当前节点的所有邻居的状态:
for (node_t neighbor: adj[cur]) {
// ...
}
- 如果某个节点已访问,则跳过。
if (visited[neighbor]) continue;
- 否则,递归的对该节点进行DFS:
dfs(neighbor, visited, nodeStack);
- 所有邻居检查完后,就将该节点入栈:
nodeStack.push(cur);
整个dfs函数的代码如下:
void Graph::dfs(node_t cur, vector<bool> &visited, stack<node_t> &nodeStack) {
visited[cur] = true;
for (node_t neighbor: adj[cur]) {
if (visited[neighbor]) continue;
dfs(neighbor, visited, nodeStack);
}
nodeStack.push(cur);
}
拓扑排序
我们需要初始化3个数据结构:
sort:存放拓扑排序序列的数组。visited:见上文。nodeStack:见上文。
vector<node_t> sort;
vector<bool> visited(n, false);
stack<node_t> nodeStack;
整个过程如下:
- 依次检查每个节点的状态,如果未访问,则从该节点开始进行DFS:
for (node_t node = 0; node < n; ++node) {
if (visited[node]) continue;
dfs(node, visited, nodeStack);
}
- 此时
nodeStack已经存储了整个拓扑排序序列,我们只需要转移到sort数组并返回即可:
while (!nodeStack.empty()) {
sort.push_back(nodeStack.top());
nodeStack.pop();
}
return sort;
整个代码如下:
vector<node_t> Graph::toposortDfs() {
vector<node_t> sort;
vector<bool> visited(n, false);
stack<node_t> nodeStack;
for (node_t node = 0; node < n; ++node) {
if (visited[node]) continue;
dfs(node, visited, nodeStack);
}
while (!nodeStack.empty()) {
sort.push_back(nodeStack.top());
nodeStack.pop();
}
return sort;
}
测试
代码:
int main() {
Graph graph{{2},
{2},
{3, 4, 5},
{4},
{6, 7},
{4},
{7},
{}};
auto sort = graph.toposortDfs();
cout << "The topology sort sequence is:\n";
for (const auto &node: sort) {
cout << node << ' ';
}
return 0;
}
输出:
The topology sort sequence is:
1 0 2 5 3 4 6 7
复杂度分析
- 时间复杂度:\(O(n+e)\),\(n\)为节点总数,\(e\)为边的总数。其中DFS的时间复杂度为\(O(n+e)\)。
- 空间复杂度:\(O(n)\)(邻接表的空间复杂度为\(O(n+e)\),不计入在内),其中维护
visited数组和nodeStack栈分别需要\(O(n)\)的额外空间。
有向图的拓扑排序——DFS的更多相关文章
- ACM/ICPC 之 拓扑排序+DFS(POJ1128(ZOJ1083)-POJ1270)
两道经典的同类型拓扑排序+DFS问题,第二题较第一题简单,其中的难点在于字典序输出+建立单向无环图,另外理解题意是最难的难点,没有之一... POJ1128(ZOJ1083)-Frame Stacki ...
- 拓扑排序+DFS(POJ1270)
[日后练手](非解题) 拓扑排序+DFS(POJ1270) #include<stdio.h> #include<iostream> #include<cstdio> ...
- 拓扑排序-DFS
拓扑排序的DFS算法 输入:一个有向图 输出:顶点的拓扑序列 具体流程: (1) 调用DFS算法计算每一个顶点v的遍历完成时间f[v] (2) 当一个顶点完成遍历时,将该顶点放到一个链表的最前面 (3 ...
- 有向图和拓扑排序Java实现
package practice; import java.util.ArrayDeque; import java.util.Iterator; import java.util.Stack; pu ...
- CodeForces-1217D (拓扑排序/dfs 判环)
题意 https://vjudge.net/problem/CodeForces-1217D 请给一个有向图着色,使得没有一个环只有一个颜色,您需要最小化使用颜色的数量. 思路 因为是有向图,每个环两 ...
- 有向图的拓扑排序算法JAVA实现
一,问题描述 给定一个有向图G=(V,E),将之进行拓扑排序,如果图有环,则提示异常. 要想实现图的算法,如拓扑排序.最短路径……并运行看输出结果,首先就得构造一个图.由于构造图的方式有很多种,这里假 ...
- Ordering Tasks(拓扑排序+dfs)
Ordering Tasks John has n tasks to do. Unfortunately, the tasks are not independent and the executio ...
- HDU 5438 拓扑排序+DFS
Ponds Time Limit: 1500/1000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others)Total Sub ...
- C++编程练习(12)----“有向图的拓扑排序“
设G={V,E}是一个具有 n 个顶点的有向图,V中的顶点序列 v1,v2,......,vn,满足若从顶点 vi 到 vj 有一条路径,则在顶点序列中顶点 vi 必在顶点 vj 之前.则称这样的顶点 ...
- POJ1128 Frame Stacking(拓扑排序+dfs)题解
Description Consider the following 5 picture frames placed on an 9 x 8 array. ........ ........ ... ...
随机推荐
- 云计算_OpenStack
部署方式-Fuel 注:部署失败且Fuel方式已过时. 部署方式-packstack 注:基于系统版本CentOS 7.9 2009部署 系统基本设置 设置静态IP=192.168.80.60 设置h ...
- IDEA中如何导入jar包、IDEA中找不到对应类改怎样解决?(详细图解过程)
今天突然心血来潮.用IDEA运行之前用eclipse编写的项目.发现遇到了一些bug,现在习惯了使用maven管理项目的依赖.一时间忘记了怎样将jar包导入项目中.特此记录一下 文章目录 1.未加入j ...
- LcdTools如何实现PX01读取SD中BIN文件并通过端口发出去
在实际应用中我们会碰到需要下载很大容量固件,比如TP固件几百K大小BIN文件,这种情况下用LcdTools写初始化代码的方式实现就不大现实:此时我们可以通过PX01 SD来实现. 首先,把需要操作的B ...
- 2.-url和视图函数
一.URL-结构 1.定义:统一资源定位符 Uniform Resource Locator 2.作用:用来表示互联网上某个资源地址 3.URL的一般语法格式为(注:[]代码其中的内容可以省略): 格 ...
- 基于.NetCore开发博客项目 StarBlog - (19) Markdown渲染方案探索
前言 笔者认为,一个博客网站,最核心的是阅读体验. 在开发StarBlog的过程中,最耗时的恰恰也是文章的展示部分功能. 最开始还没研究出来如何很好的使用后端渲染,所以只能先用Editor.md组件做 ...
- SQL Server-表结构的操作
1.修改表的字段的数据类型 alter table [File_Info] alter column Upload_Request_ID nvarchar(14) not null 2.添加表的字段并 ...
- C# 语法分析器(二)LR(0) 语法分析
系列导航 (一)语法分析介绍 (二)LR(0) 语法分析 (三)LALR 语法分析 (四)二义性文法 (五)错误恢复 (六)构造语法分析器 首先,需要介绍下 LALR 语法分析的基础:LR(0) 语法 ...
- Python基础部分:8、for循环和range的使用
目录 一.while循环补充说明 1.死循环 2.嵌套及全局标志位 二.for...循环 1.for...循环特点 2.for...循环语法结构 三.range方法 1.什么是range 2.不同版本 ...
- miniconda使用
基本指令 conda create -n xxx python=3.7 // 创建Python3.7的名为xxx虚拟环境 conda env list // 显示所有的虚拟环境 conda activ ...
- PHPMQTT问题一二三
问题一:PHPMQTT作为客户端订阅超过一定数量的主题后,系统就会报错. 思路:在网上查找原因,失败: 打开调试debug = true ; 结果proc方法中报错: eof receive 问题二: ...