MapReduce入门实战
MapReduce 思想
MapReduce 是 Google 提出的一个软件架构,用于大规模数据集的并行运算。概率“Map(映射)”和“Reduce(归约)”以及它们的思想都是从函数式编程语言借鉴的,还有从矢量编程语言借来的特性。
当前的软件实现是指定一个“Map”函数,用来把一组键值对映射成一组新的键值对,指定并发的“Reduce”函数,用来保证所有映射的键值对中的每一个都共享相同的键组。
Hadoop MapReduce 的任务过程分为两个阶段:
- Map 阶段:把大任务分解为若干个小任务来并行处理。这些任务可以并行计算,彼此之间没有依赖关系。
- Reduce 阶段:对 map 阶段的结果进行全局汇总。
Hadoop 序列化
为什么要序列化?
序列化是我们通过网络通信传输数据时或者把对象持久化到文件,需要把对象序列化成二进制的结构。
观察源码时发现自定义 Mapper 类与自定义 Reducer 类都有泛型类约束,比如自定义 Mapper 有四个泛型参数,但是都不是 Java 基本类型。
为什么 Hadoop 要选择建立自己的序列化格式而不使用 java 自带 serializable?
- 序列化在分布式程序中非常重要,在 Hadoop 中,集群中多个节点的进程间的通信是通过 RPC(远程过程调用:RemoteProcedureCall)实现;RPC 将消息序列化成二进制流发送到远程节点,远程节点再将接收到的二进制数据反序列化为原始的消息,因此 RPC 往往追求如下特点:
- 数据更紧凑,能充分利用网络带宽资源
- 快速:序列化和反序列化的性能开销更低
- Hadoop 使用的是自己的序列化格式 Writable,它比 java 的序列化 serialization 更紧凑速度更快。一个对象使用 Serializable 序列化后,会携带很多额外信息比如校验信息,Header,继承体系等
Java 基本类型与 Hadoop 常用序列化类型
| Java 基本类型 | Hadoop Writable 类型 |
|---|---|
| boolean | BooleanWritable |
| byte | ByteWritable |
| int | IntWritable |
| float | FloatWritable |
| long | LongWritable |
| double | DoubleWritable |
| String | Text |
| map | MapWritable |
| array | ArrayWritable |
基本的序列化类型往往不能满足需求,比如我们常常需要传递一些自定义的 bean 对象。在 Hadoop 中为了实现自定义对象序列化需要实现 Writable 接口。
- 实现 Writable 接口
- 有无参构造函数
- 重写序列化 write 方法和反序列化 readFields 方法。(注意序列化和反序列化的字段顺序必须完全一致)
- 如果自定义 Bean 对象需要放在 Mapper 输出 KV 中的 K 里面,那么该对象还需要实现 Comparable 接口,因为 MapReduce 框架中的 Shuffle 过程要求 key 必须能排序
案例实战
需求:下面有一个水果摊老板的一个售卖记录,这三列分别是:水果名称、水果重量、还有总价。我们需要统计每个水果的总重量和重价。
苹果 3 12
李子 4 8
苹果 2 8
桃子 4 20
香蕉 2 4
火龙果 1 4
- 配置 Hadoop 环境变量
- 导入 maven 依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop-version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop-version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop-version}</version>
</dependency>
- 编写保存售卖记录的实体类
@Setter
@Getter
public class FruitsRecord implements Writable {
private int weight;
private double totalPrice;
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(weight);
out.writeDouble(totalPrice);
}
@Override
public void readFields(DataInput in) throws IOException {
this.weight = in.readInt();
this.totalPrice = in.readDouble();
}
@Override
public String toString() {
return "FruitsRecord{" +
"weight=" + weight +
", totalPrice=" + totalPrice +
'}';
}
}
- 编写 Mapper 类
import com.mmc.hadoop.bean.FruitsRecord;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FruitsMapper extends Mapper<LongWritable,Text,Text, FruitsRecord> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, FruitsRecord>.Context context) throws IOException, InterruptedException {
//获取一行的数据
String line = value.toString();
String[] fields = line.split(" ");
Text outKey= new Text(fields[0]);
FruitsRecord fruitsRecord=new FruitsRecord();
fruitsRecord.setWeight(Integer.parseInt(fields[1]));
fruitsRecord.setTotalPrice(Double.parseDouble(fields[2]));
context.write(outKey,fruitsRecord);
}
}
- 编写 Reduce 类
import com.mmc.hadoop.bean.FruitsRecord;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FruitsReducer extends Reducer<Text, FruitsRecord,Text,FruitsRecord> {
@Override
protected void reduce(Text key, Iterable<FruitsRecord> values, Reducer<Text, FruitsRecord, Text, FruitsRecord>.Context context) throws IOException, InterruptedException {
int totalWeight = 0;
double totalPrice =0;
for (FruitsRecord fruitsRecord : values){
totalWeight += fruitsRecord.getWeight();
totalPrice+= fruitsRecord.getTotalPrice();
}
FruitsRecord fruitsRecord = new FruitsRecord();
fruitsRecord.setWeight(totalWeight);
fruitsRecord.setTotalPrice(totalPrice);
context.write(key, fruitsRecord);
}
}
- 编写 Driver 类
import com.mmc.hadoop.bean.FruitsRecord;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FruitsDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// System.setProperty("java.library.path","d://");
Configuration conf = new Configuration();
Job job=Job.getInstance(conf,"FruitsDriver");
//指定本程序的jar包所在的路径
job.setJarByClass(FruitsDriver.class);
//指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(FruitsMapper.class);
job.setReducerClass(FruitsReducer.class);
//指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FruitsRecord.class);
//指定reduce输出数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FruitsRecord.class);
//指定job的输入文件目录和输出目录
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
boolean result = job.waitForCompletion(true);
System.exit( result ? 0: 1);
}
}
总结:
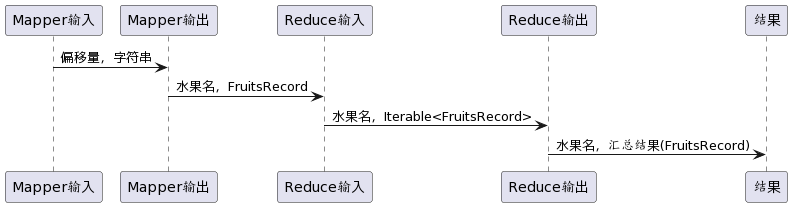
Mapper 里面,Mapper 类的四个泛型分别为入参的 KV 和出参的 KV。Reduce 里面的也有4个泛型,分别为入参的KV和出参的KV。Reduce入参的 KV 与 Mapper 里面出参的 KV 类型是对应的。只不过 Reduce 的入参的 Value 类型是集合类型的。
时序图如下:
运行任务
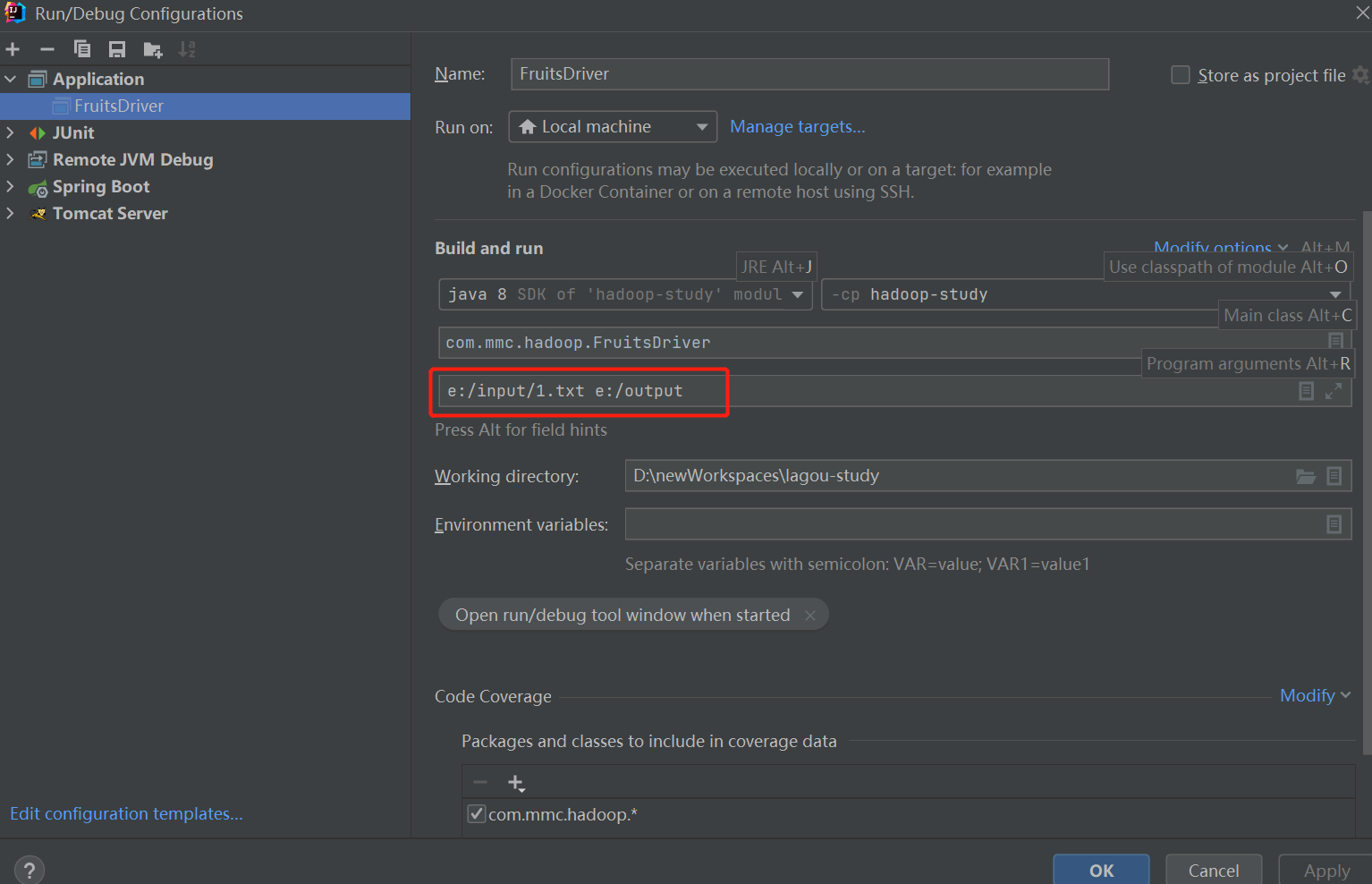
本地模式
直接在 IDEA 中运行驱动类即可。因为程序里输入文件路径和输出文件路径是取的 main 函数里的 args。所以运行的时候需要指定参数。
遇到的问题
问题 1:

问题 2:创建目录错误
org.apache.hadoop.io.nativeio.NativeIO$Windows.createDirectoryWithMode0(Ljava/lang/String
解决方案:
两个问题都是 windows 的 hadoop/bin 目录下缺少文件导致的。文件下载路径:https://github.com/cdarlint/winutils
- 找到对应版本的 hadoop.dll 和 winutils.exe 下载下来放到 hadoop/bin 目录下。
- C: windows\System32 放入 hadoop.dll 文件
- 重启电脑
输出目录:
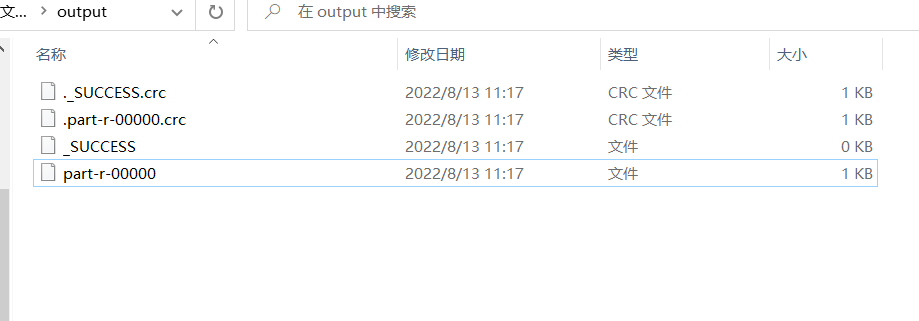
打开结果文件 part-r-00000:
李子 FruitsRecord{weight=4, totalPrice=8.0}
桃子 FruitsRecord{weight=4, totalPrice=20.0}
火龙果 FruitsRecord{weight=1, totalPrice=4.0}
苹果 FruitsRecord{weight=5, totalPrice=20.0}
香蕉 FruitsRecord{weight=2, totalPrice=4.0}
Yarn 集群模式
- 把程序打包成 jar 包,上传到 linux
- 将测试的 txt 上传到 HDFS 上面
- 启动 Hadoop 集群
- 使用 Hadoop 命令提交任务运行
hadoop jar wc.jar com.mmc.hadoop.FruitsDriver
/user/input /user/output
MapReduce入门实战的更多相关文章
- Spark入门实战系列--10.分布式内存文件系统Tachyon介绍及安装部署
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Tachyon介绍 1.1 Tachyon简介 随着实时计算的需求日益增多,分布式内存计算 ...
- Spark入门实战系列--1.Spark及其生态圈简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .简介 1.1 Spark简介 年6月进入Apache成为孵化项目,8个月后成为Apache ...
- Spark入门实战系列--2.Spark编译与部署(中)--Hadoop编译安装
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .编译Hadooop 1.1 搭建环境 1.1.1 安装并设置maven 1. 下载mave ...
- Spark入门实战系列--2.Spark编译与部署(下)--Spark编译安装
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .编译Spark .时间不一样,SBT是白天编译,Maven是深夜进行的,获取依赖包速度不同 ...
- Spark入门实战系列--3.Spark编程模型(上)--编程模型及SparkShell实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark编程模型 1.1 术语定义 l应用程序(Application): 基于Spar ...
- Spark入门实战系列--4.Spark运行架构
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 1. Spark运行架构 1.1 术语定义 lApplication:Spark Appli ...
- Spark入门实战系列--5.Hive(上)--Hive介绍及部署
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Hive介绍 1.1 Hive介绍 月开源的一个数据仓库框架,提供了类似于SQL语法的HQ ...
- Spark入门实战系列--6.SparkSQL(上)--SparkSQL简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .SparkSQL的发展历程 1.1 Hive and Shark SparkSQL的前身是 ...
- Spark入门实战系列--8.Spark MLlib(上)--机器学习及SparkMLlib简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .机器学习概念 1.1 机器学习的定义 在维基百科上对机器学习提出以下几种定义: l“机器学 ...
随机推荐
- 做一个能对标阿里云的前端APM工具(下)
上篇请访问这里做一个能对标阿里云的前端APM工具(上) 样本多样性问题 上一小节中的实施方案是微观的,即单次性的.具体的.但是从宏观上看,我需要保证性能测试是公允的,符合大众预期的.为了达到这种效果, ...
- 关于我学git这档子事(4)
------------恢复内容开始------------ 当本地分支(main/dev)比远程仓库分支(main/dev)落后几次提交时 先: git pull 更新本地仓库 再 git push ...
- 官方出品,比 mydumper 更快的逻辑备份工具
mysqldump 和 mydumper 是我们常用的两个逻辑备份工具. 无论是 mysqldump 还是 mydumper 都是将备份数据通过 INSERT 的方式写入到备份文件中. 恢复时,myl ...
- neo4j删除节点和关系
两种方法: 一.用下列 Cypher 语句: match (n) detach delete n 原理:匹配所有的节点,然后进行删除. 二. 从文件系统上删除对应的数据库. 1.停掉服务: 2.删除 ...
- ansible变量引用
1. 在/etc/ansible/hosts默认文件中定义变量 [test] 192.168.163.130 #[test:vars] #key=ansible 或者 192.168.163.130 ...
- ssh-免密钥登陆
实现openssh免密钥登陆(公私钥验证) 在主机A上,通过root用户,使用ssh-keygen生成的两个密钥:id_rsa和id_rsa.pub 私钥(id_rsa)保存在本地主机,公钥(id_r ...
- application.yml 常用基本配置
前言 在平时的项目开发中,自己对application.yml的配置的写法较为熟悉,现在自己就application.yml常用的配置进行总结如下: 1.Tomcat 配置 server: #设置请求 ...
- CVPR 2017:See the Forest for the Trees: Joint Spatial and Temporal Recurrent Neural Networks for Video-based Person Re-identification
[1] Z. Zhou, Y. Huang, W. Wang, L. Wang, T. Tan, Ieee, See the Forest for the Trees: Joint Spatial a ...
- Servlet-3 :JDBC+重定向
请求重定向 redirect1) Servlet接收到浏览器端请求并处理完成后,给浏览器端一个特殊的响应,这个特殊的响应要求浏览器去请求一个新的资源,整个过程中浏览器端会发出两次请求,且浏览器地址栏会 ...
- NIO.2中Path、 Paths、Files类的使用