基于Caffe ResNet-50网络实现图片分类(仅推理)的实验复现
摘要:本实验主要是以基于Caffe ResNet-50网络实现图片分类(仅推理)为例,学习如何在已经具备预训练模型的情况下,将该模型部署到昇腾AI处理器上进行推理。
本文分享自华为云社区《【CANN训练营】【2022第二季】【新手班】基于Caffe ResNet-50网络实现图片分类(仅推理)的实验复现》,作者: StarTrek 。
本实验主要是以基于Caffe ResNet-50网络实现图片分类(仅推理)为例,学习如何在已经具备预训练模型的情况下,将该模型部署到昇腾AI处理器上进行推理。该实验的主要任务有:
1、将Caffe ResNet-50网络的模型文件转换为适配昇腾AI处理器的离线模型( * .om文件);
2、加载该om文件,对2张 * .jpg图片进行同步推理,分别得到推理结果后,再对推理结果进行处理,输出top5置信度的类别标识;
3、将测试的图片替换为自己的图片并重新编译运行。
一、云服务器的使用
首先为了更好的让我们能够了解并学习昇腾的相关知识,华为CANN训练营为每一位学员都给予了一定的云服务器资源,关于云服务器的使用简单总结如下:
本次提供的共享镜像是:Ubuntu 18.04(系统) + 5.1.RC2.alpha005(CANN环境版本)
登陆华为云->进入控制台->申请ESC弹性云服务器->获取弹性公网IP->运用SSH远程访问云服务器->正常按照ubuntu系统的终端命令来操作使用服务器
资源链接:
远程终端软件推荐MobaXterm:https://mobaxterm.mobatek.net/
软件使用方法:https://blog.csdn.net/xuanying_china/article/details/120080644
进入终端后为root用户,需要进入HwHiAiUser用户
指令:
cd /home/
su - HwHiAiUser
可以使用ls或者ll指令随意浏览系统中已有的文件情况。
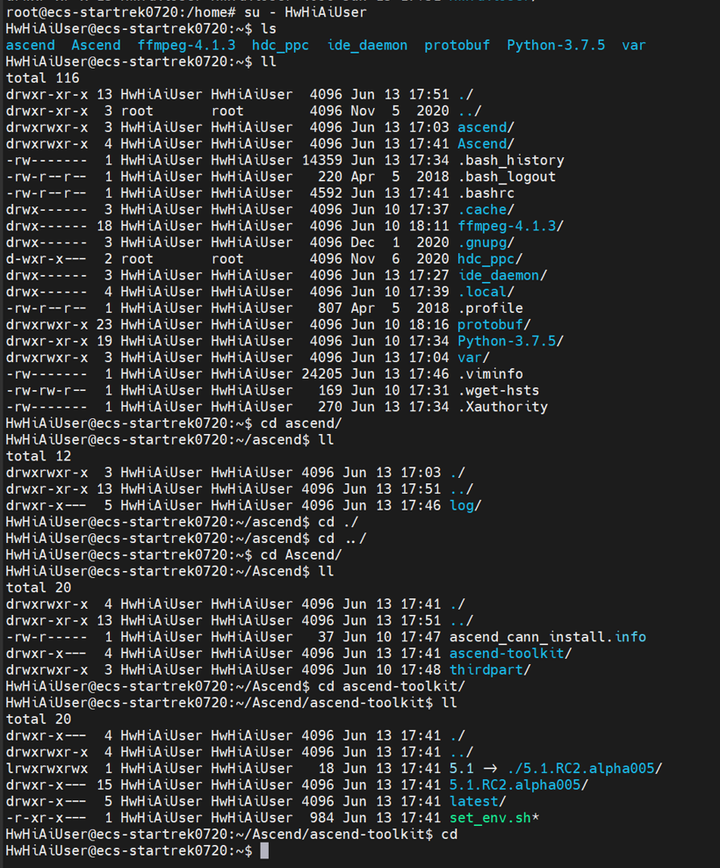
二、基于Caffe ResNet-50网络实现图片分类(仅推理)实验
准备工作完成之后,下面就可以开始正式的实验之旅啦!可以按照仓库里的readme文件所述步骤一步步操作,此处也仅仅只是简单的给出实验的步骤和实验图。
1、下载样例代码
克隆sample仓里的代码
git clone https://gitee.com/ascend/samples.git
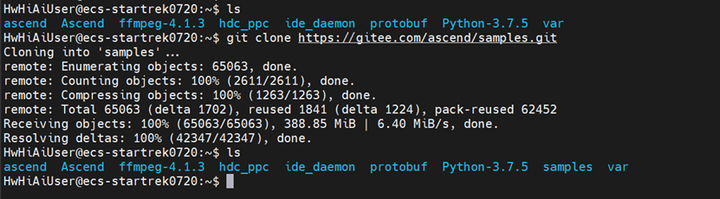
进入到resnet50_imagenet_classification样例的文件夹中
cd samples/
cd cplusplus/level2_simple_inference/1_classification/resnet50_imagenet_classification
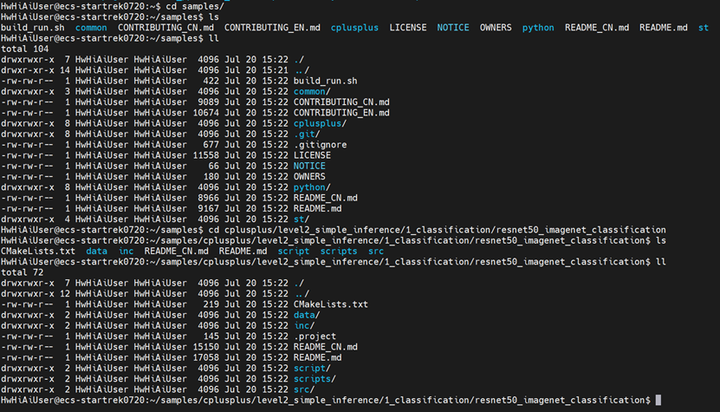
2、获取ResNet-50预训练模型
先创建一个用来存储该模型的文件夹,并打开该文件夹
mkdir caffe_model
cd caffe_model
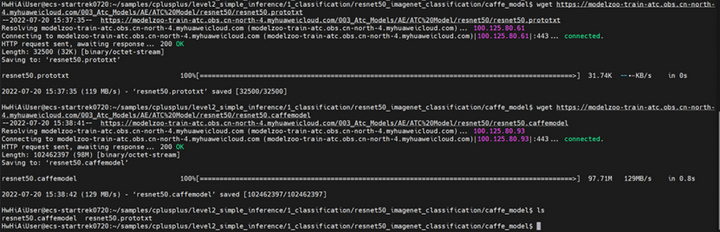
从网页直接通过命令下载预训练模型:权重文件(resnet50.caffemodel)和模型文件(resnet50.prototxt)
wegt https://modelzoo-train-atc.obs.cn-north-4.myhuaweicloud.com/003_Atc_Models/AE/ATC%20Model/resnet50/resnet50.prototxt
wegt https://modelzoo-train-atc.obs.cn-north-4.myhuaweicloud.com/003_Atc_Models/AE/ATC%20Model/resnet50/resnet50.caffemodel
3、模型转换
上述下载的预训练模型需要首先运用ATC模型转换工具将该模型转换成昇腾AI处理器支持的离线模型(.om)
官方文档ATC工具学习资源:
https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/51RC2alpha005/infacldevg/atctool
流程:
首先先切换到样例目录下(接着上面的操作就是上一级目录)
cd ../
然后运行模型转换工具
atc --model=caffe_model/resnet50.prototxt --weight=caffe_model/resnet50.caffemodel --framework=0 --output=model/resnet50 --soc_version=Ascend310 --input_format=NCHW --input_fp16_nodes=data --output_type=FP32 --out_nodes=prob:0
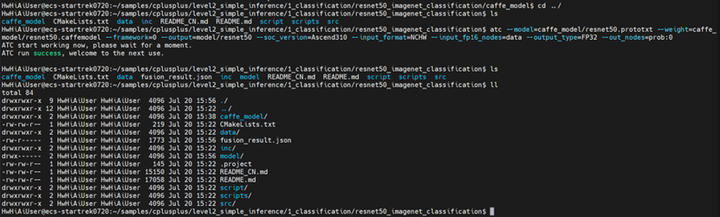
打开model文件夹可以看到resnet50.om已经转换完成了

4、下载测试图片
进入data文件夹,并下载两张ImageNet数据集中存在类别的图片
cd ../data/
wget https://c7xcode.obs.cn-north-4.myhuaweicloud.com/models/aclsample/dog1_1024_683.jpg
wget https://c7xcode.obs.cn-north-4.myhuaweicloud.com/models/aclsample/dog2_1024_683.jpg

测试的两张图


5、图片格式转换
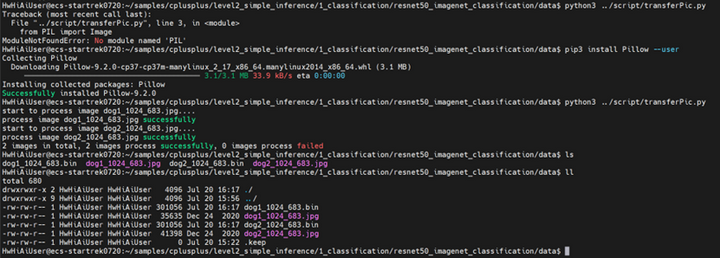
下载的图片是JPEG格式的,需要转换成适合模型输入要求格式的二进制文件(.bin)
在data目录下,执行transferPic.py脚本,将*.jpg转换为*.bin,同时将图片从1024 * 683的分辨率缩放为224 * 224。
python3 ../script/transferPic.py
6、编译运行
进入“cplusplus/level2_simple_inference/1_classification/resnet50_imagenet_classification”样例目录
cd ../
设置临时的环境变量,配置程序编译依赖的头文件与库文件路径
export DDK_PATH=$HOME/Ascend/ascend-toolkit/latest
export NPU_HOST_LIB=$DDK_PATH/acllib/lib64/stub

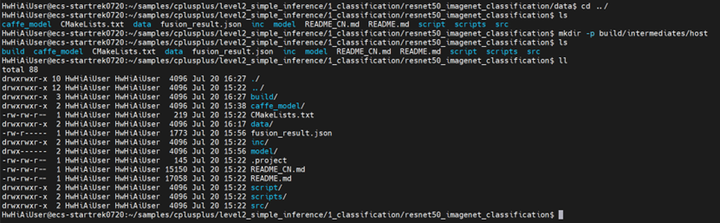
建立build文件夹,准备编译代码文件
mkdir -p build/intermediates/host
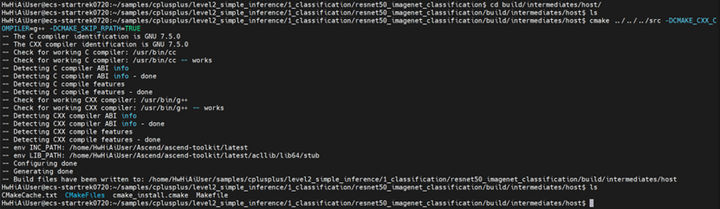
进入build文件夹,编译.cpp文件
cd build/intermediates/host
cmake ../../../src -DCMAKE_CXX_COMPILER=g++ -DCMAKE_SKIP_RPATH=TRUE
make

可以在样例目录(cplusplus/level2_simple_inference/1_classification/resnet50_imagenet_classification)下的out文件夹中找到编译好的可执行main文件,接下来我们直接运行main文件
cd ../../../out/
./main

三、替换图片数据进行测试
这里在网上随便找了两张图(一张金鱼label-1,一张金毛犬label-207),可以随意找几张图,只要是JPG格式的图片即可,图片中的事物类型最好是ImageNet数据集标签中的类型。
1、添加图片并转换格式
可以直接下载到本地电脑中,然后直接将文件拖到MobaXterm软件的云服务器文件列表中,为了方便直接先在列表中找到前面的data文件夹,然后直接拖拽到该文件夹下即可。


按照前面的操作(5、图片格式转换)重新进行图片文件格式的转换,在data目录下运行
python3 ../script/transferPic.py

2、修改sample_process.cpp源码,添加新增的两张图片的路径
在testFile列表中增加前面新添加的并转换好的那两张bin格式的文件路径,路径仿照前两个写即可,不过别忘记不同文件路径间的逗号分隔哦
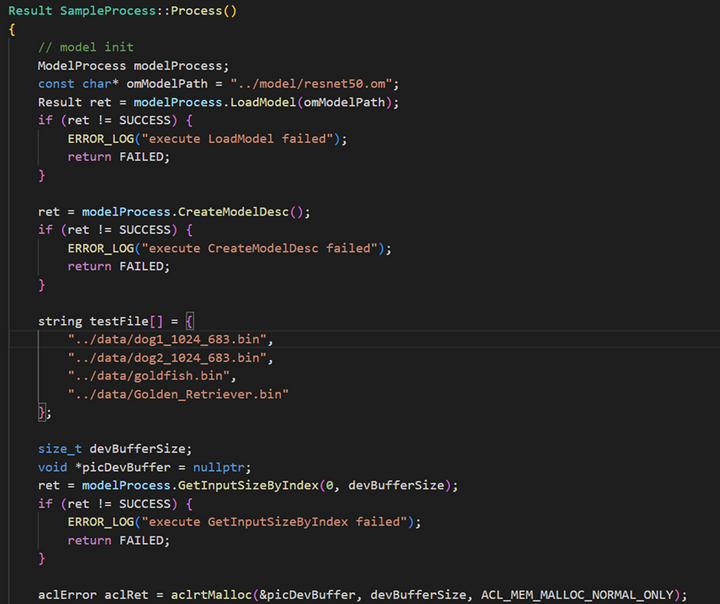
3、重新编译源码
按照前面的步骤进行即可(6、编译运行),需要注意的是,如果重启过服务器,之前设置的编译临时环境会丢失,需要再次设置临时的环境变量(配置程序编译依赖的头文件与库文件路径),然后可以在build/intermediates/host文件下直接运行make编译即可,编译器会自动编译修改过的源文件并覆盖。

4、推理
按照前面的步骤重新运行编译好的main文件即可(6、编译运行中的最后一步),注意文件的路径,需要在out文件夹下运行,因为main文件是被保存在这里的。
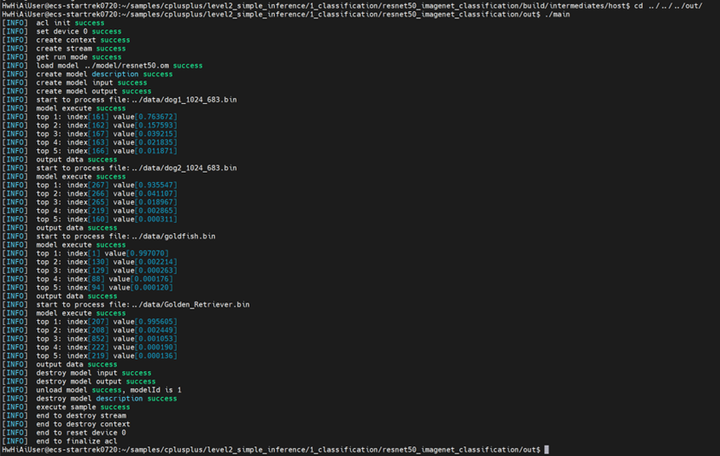
最后我们可以看到
标签为1是金鱼,第一张图是金鱼的概率为99.7070%
标签为207是金毛犬,第二张图是金毛犬的概率为99.5605%
基于Caffe ResNet-50网络实现图片分类(仅推理)的实验复现的更多相关文章
- 深度学习之神经网络核心原理与算法-caffe&keras框架图片分类
之前我们在使用cnn做图片分类的时候使用了CIFAR-10数据集 其他框架对于CIFAR-10的图片分类是怎么做的 来与TensorFlow做对比. Caffe Keras 安装 官方安装文档: ht ...
- Caffe 议事(二):从零开始搭建 ResNet 之 网络的搭建(上)
3.搭建网络: 搭建网络之前,要确保之前编译 caffe 时已经 make pycaffe 了. 步骤1:导入 Caffe 我们首先在 ResNet 文件夹中建立一个 mydemo.py 的文件,本参 ...
- 源码分析——迁移学习Inception V3网络重训练实现图片分类
1. 前言 近些年来,随着以卷积神经网络(CNN)为代表的深度学习在图像识别领域的突破,越来越多的图像识别算法不断涌现.在去年,我们初步成功尝试了图像识别在测试领域的应用:将网站样式错乱问题.无线领域 ...
- 第二十二节,TensorFlow中的图片分类模型库slim的使用、数据集处理
Google在TensorFlow1.0,之后推出了一个叫slim的库,TF-slim是TensorFlow的一个新的轻量级的高级API接口.这个模块是在16年新推出的,其主要目的是来做所谓的“代码瘦 ...
- 人脸识别(基于Caffe)
人脸识别(基于Caffe, 来自tyd) 人脸识别(判断是否为人脸) LMDB(数据库, 为Caffe支持的分类数据源) mkdir face_detect cd face_detect mkdir ...
- (转载)基于比较的少样本(one/few-shoting)分类
基于比较的方法 先通过CNN得到目标特征,然后与参考目标的特征进行比较. 不同在于比较的方法不同而已. 基本概念 数据集Omniglot:50种alphabets(文字或者文明); alphabet中 ...
- 基于Caffe训练AlexNet模型
数据集 1.准备数据集 1)下载训练和验证图片 ImageNet官网地址:http://www.image-net.org/signup.php?next=download-images (需用邮箱注 ...
- Ubuntu下caffe:用自己的图片训练并测试AlexNet模型
参考博客:https://blog.csdn.net/eereere/article/details/79118645#commentBox 目录 1.准备图片 2. 将 图片路径写入txt 参考 这 ...
- 人脸检测数据源制作与基于caffe构架的ALEXNET神经网络训练
本篇文章主要记录的是人脸检测数据源制作与ALEXNET网络训练实现检测到人脸(基于caffe). 1.数据获取 数据获取: ① benchmark是一个行业的基准(数据库.论文.源码.结果),例如WI ...
随机推荐
- jQuery操作标签,jQuery事件操作,jQuery动画效果,前端框架
jQuery操作标签 jQuery代码查找标签绑定的变量名推荐使用 $xxxEle 样式类操作 addClass();// 添加指定的CSS类名. removeClass();// 移除指定的CSS类 ...
- WinUI迁移到即将"过时"的.NET MAUI个人体验
迁移的初衷 本人平时是做.net相关的工作,对于.net技术栈也有一些了解,自从新的.net能够跨平台之后,之前也有跨平台的ui框架Xamarin,现在微软推出了.NET MAUI这个说是 统一了开发 ...
- @Inherited 原注解功能介绍
@Inherited 底层 package java.lang.annotation; /** * Indicates that an annotation type is automatically ...
- Apache ShenYu:分析、实现一个 Node.js 语言的 HTTP 服务注册客户端(HTTP Registry)
这块没空写文章了,先贴出实现代码吧 yuque.com/myesn
- SpringBoot Redis 实践指南
前言 SpringBoot Cache 是一个很好的缓存框架,可以兼容多种缓存实现,数据量较大的情况下,Redis 应该是最多被使用的. 本文重点介绍 SpringBoot 和 Redis 整合使用的 ...
- Spring Boot配置全局异常捕获
1 SpringBoot配置全局的异常捕获 项目的说明 配置thymeleaf作为视图模板 ExceptionController.java模拟测试用 MyAjaxExceptionHandler.j ...
- 如何在 pyqt 中捕获并处理 Alt+F4 快捷键
前言 如果在 Windows 系统的任意一个窗口中按下 Alt+F4,默认行为是关闭窗口(或者最小化到托盘).对于使用了亚克力效果的窗口,使用 Alt+F4 最小化到托盘,再次弹出窗口的时候可能出现亚 ...
- vue面试总结-2022
1.vue生命周期及各周期得特点 beforCreate 特点: 初始化实例,不能使用data和methods.ref 示例 beforeCreate: function () { console.g ...
- React项目中使用less/scss&全局样式/变量
使用create-react-app脚手架搭建初始化项目 > npm install -g create-react-app > npx create-react-app my-app c ...
- 如何提高访问 GitHub 的速度
更新记录 本文迁移自Panda666原博客,原发布时间:2021年5月11日. 因为一些特殊的原因,国内访问Github的速度确实比较慢.国内访问Github经常会出现连接不上.图片加载不出来.文件无 ...