利用中文数据跑Google开源项目word2vec
一直听说word2vec在处理词与词的相似度的问题上效果十分好,最近自己也上手跑了跑Google开源的代码(https://code.google.com/p/word2vec/)。
1、语料
首先准备数据:采用网上博客上推荐的全网新闻数据(SogouCA),大小为2.1G。
wget ftp://ftp.labs.sogou.com/Data/SogouCA/SogouCA.tar.gz --ftp-user=hebin_hit@foxmail.com --ftp-password=4FqLSYdNcrDXvNDi -r
解压数据包:
gzip -d SogouCA.tar.gz
tar -xvf SogouCA.tar
再将生成的txt文件归并到SogouCA.txt中,取出其中包含content的行并转码,得到语料corpus.txt,大小为2.7G。
cat *.txt > SogouCA.txt
cat SogouCA.txt | iconv -f gbk -t utf- -c | grep "<content>" > corpus.txt
2、分词
用ANSJ对corpus.txt进行分词,得到分词结果resultbig.txt,大小为3.1G。

nohup ./word2vec -train resultbig.txt -output vectors.bin -cbow -size -window -negative -hs -sample 1e- -threads -binary &
vectors.bin是word2vec处理resultbig.txt后生成的词的向量文件,在实验室的服务器上训练了1个半小时。
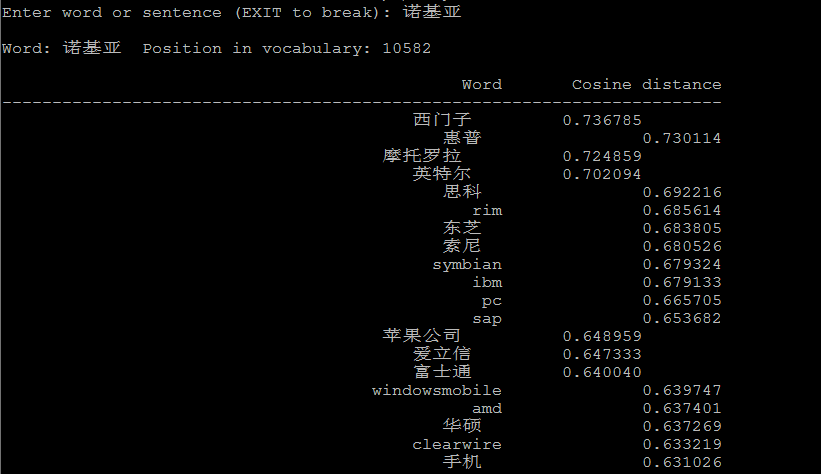
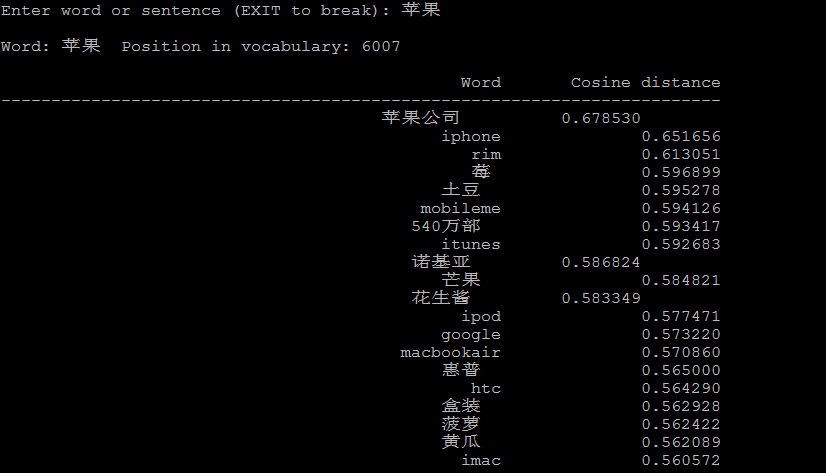
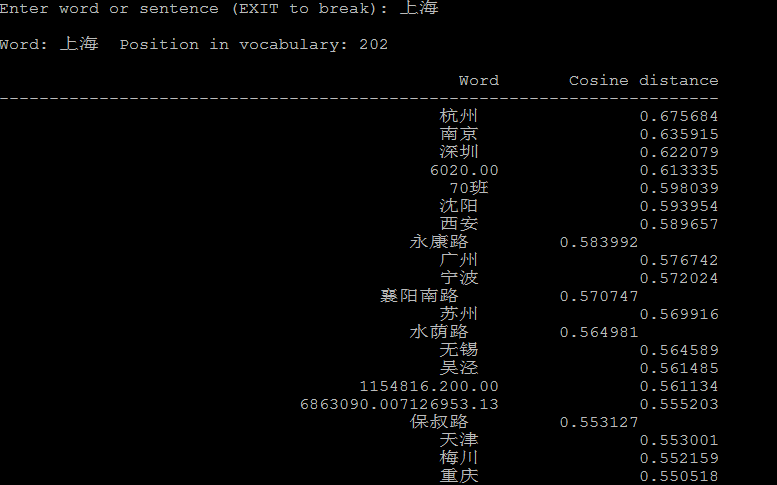
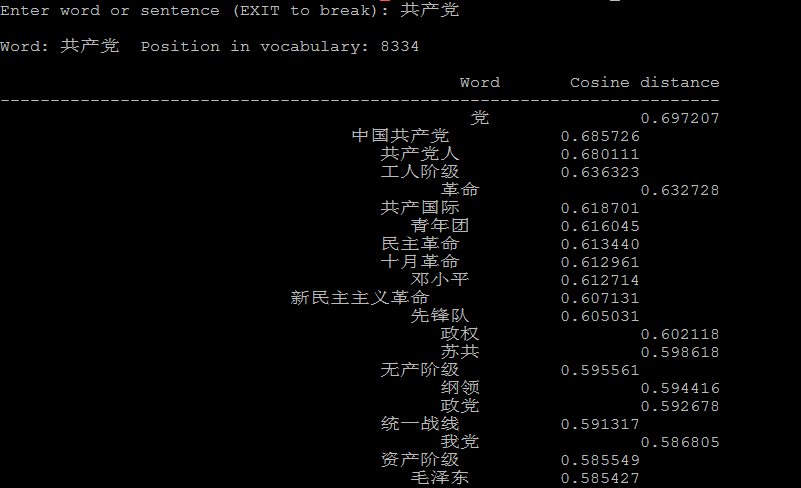
./distance vectors.bin
./distance可以看成计算词与词之间的距离,把词看成向量空间上的一个点,distance看成向量空间上点与点的距离。
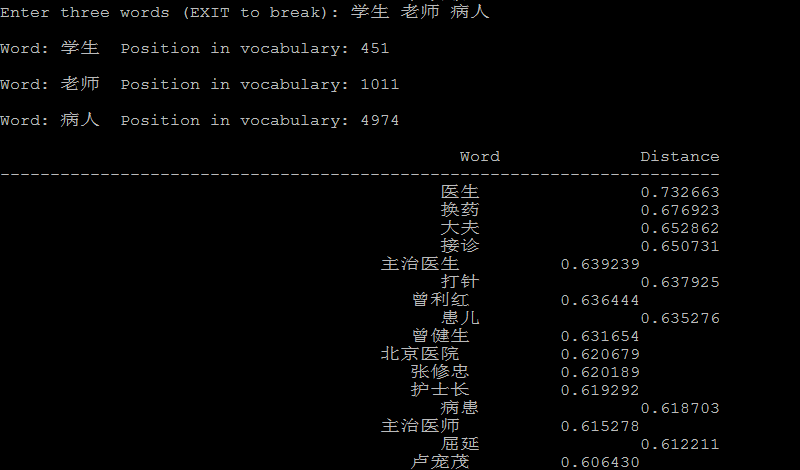
下面是一些例子:



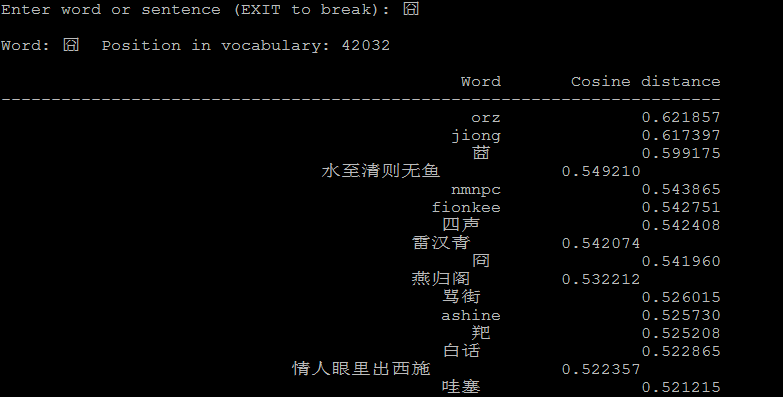
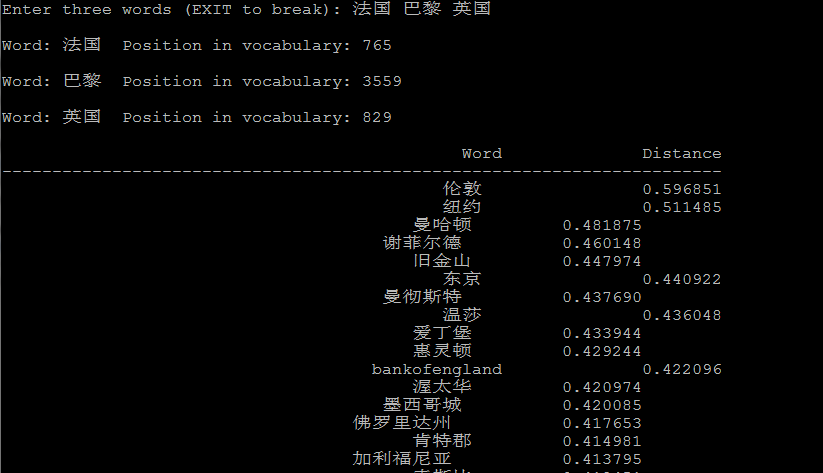
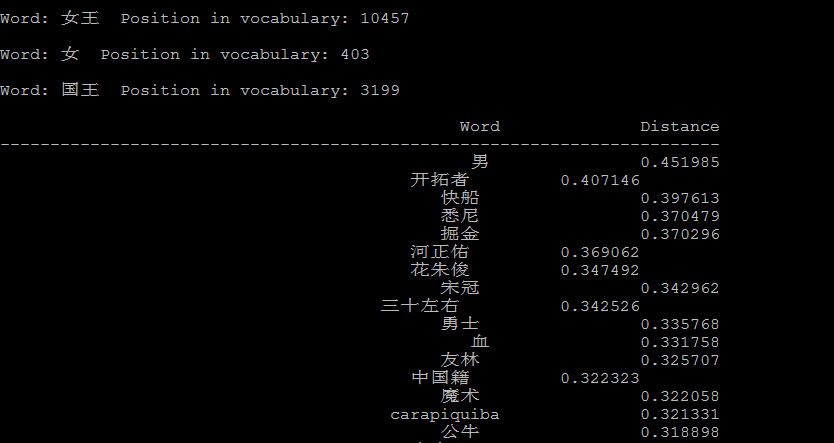
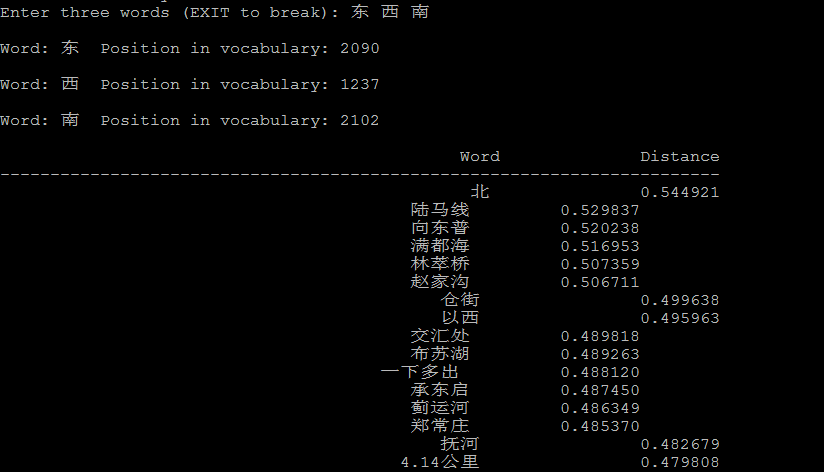
4.2 潜在的语言学规律
4.3 聚类
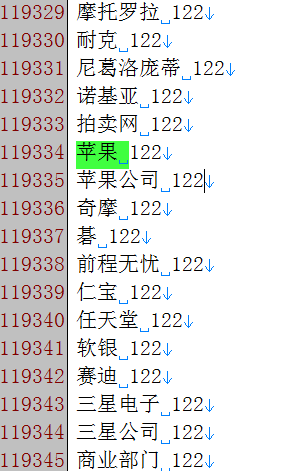
将经过分词后的语料resultbig.txt中的词聚类并按照类别排序:
1 nohup ./word2vec -train resultbig.txt -output classes.txt -cbow 0 -size 200 -window 5 -negative 0 -hs 1 -sample 1e-3 -threads 12 -classes 500 &
2 sort classes.txt -k 2 -n > classes_sorted_sogouca.txt
例如:

4.4 短语分析
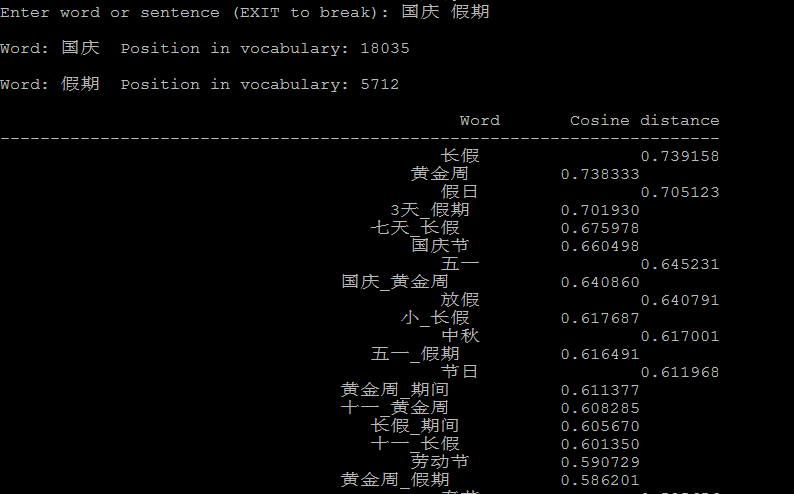
先利用经过分词的语料resultbig.txt中得出包含词和短语的文件sogouca_phrase.txt,再训练该文件中词与短语的向量表示。
./word2phrase -train resultbig.txt -output sogouca_phrase.txt -threshold -debug
./word2vec -train sogouca_phrase.txt -output vectors_sogouca_phrase.bin -cbow -size -window -negative -hs -sample 1e- -threads -binary
下面是几个计算相似度的例子:


5、参考链接:
1. word2vec:Tool for computing continuous distributed representations of words,https://code.google.com/p/word2vec/
2. 用中文把玩Google开源的Deep-Learning项目word2vec,http://www.cnblogs.com/wowarsenal/p/3293586.html
3. 利用word2vec对关键词进行聚类,http://blog.csdn.net/zhaoxinfan/article/details/11069485
6、后续准备仔细阅读的文献:
[1] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient Estimation of Word Representations in Vector Space. In Proceedings of Workshop at ICLR, 2013.
[2] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of NIPS, 2013.
[3] Tomas Mikolov, Wen-tau Yih, and Geoffrey Zweig. Linguistic Regularities in Continuous Space Word Representations. In Proceedings of NAACL HLT, 2013.
[4] Collobert R, Weston J, Bottou L, et al. Natural language processing (almost) from scratch[J]. The Journal of Machine Learning Research, 2011, 12: 2493-2537.
利用中文数据跑Google开源项目word2vec的更多相关文章
- Google开源项目风格指南
Google开源项目风格指南 来源 https://github.com/zh-google-styleguide/zh-google-styleguide Google 开源项目风格指南 (中文版) ...
- 35 个你也许不知道的 Google 开源项目
转载自:http://blog.csdn.net/cnbird2008/article/details/18953113 Google是支持开源运动的最大公司之一,它们现在总共发布有超过500个的开源 ...
- Google 开源项目风格指南
Python风格规范 分号 Tip 不要在行尾加分号, 也不要用分号将两条命令放在同一行. 行长度 Tip 每行不超过80个字符 例外: 长的导入模块语句 注释里的URL 不要使用反斜杠连接行. Py ...
- Google 开源项目风格指南阅读笔记(C++版)
虽说是编程风格指南,可是干货也不少,非常多C++的有用技术在里面. 头文件 通常每一个.cpp文件都相应一个.h文件:#define保护全部头文件都应该使用#define防止头文件被多重包括,为保证唯 ...
- PYTHON风格规范-Google 开源项目风格指南
Python风格规范 分号 Tip 不要在行尾加分号, 也不要用分号将两条命令放在同一行. 行长度 Tip 每行不超过80个字符 例外: 长的导入模块语句 注释里的URL 不要使用反斜杠连接行. Py ...
- Google 开源项目的风格指南
谷歌C++代码风格指南.农业所需的代码.更难得的是不FQ,决定性的最爱!! . http://zh-google-styleguide.readthedocs.org/en/latest/google ...
- google 开源项目阅读计划
1. glog 2. gflags 3. carto 4. ...
- 自然语言处理高手_相关资源_开源项目(比如:分词,word2vec等)
(1) 中科院自动化所的博士,用神经网络做自然语言处理:http://licstar.net (2) 分词项目:https://github.com/fxsjy/jieba(3) 清华大学搞的中文分词 ...
- Github上关于iOS的各种开源项目集合(强烈建议大家收藏,查看,总有一款你需要)
下拉刷新 EGOTableViewPullRefresh - 最早的下拉刷新控件. SVPullToRefresh - 下拉刷新控件. MJRefresh - 仅需一行代码就可以为UITableVie ...
随机推荐
- 使用exec命令删除前几天产生的日志
上次学习了访问某个网站并产生相应的日志保存在指定位置,但是时间长了,日志会占用磁盘大量的空间,下面使用exec这个命令删除之前的日志: 命令格式: find 目录绝对路径 -mtime +n(时间) ...
- QT笔记之VS开发添加类
1. 2. 3.
- 通过Mac远程调试iPhone/iPad上的网页(转)
我们知道在 Mac/PC 上的浏览器都有 Web 检查器这类的工具(如最著名的 Firebug)对前端开发进行调试,而在 iPhone/iPad 由于限于屏幕的大小和触摸屏的使用习惯,直接对网页调试非 ...
- MultiProvider
声明:原创作品,转载时请注明文章来自SAP师太技术博客( 博/客/园www.cnblogs.com):www.cnblogs.com/jiangzhengjun,并以超链接形式标明文章原始出处,否则将 ...
- [linux] shellshock
1> Test if the system is vulnerable env X="() { :;} ; echo vulnerable" /bin/sh -c " ...
- js中的正则表达式
一.正则中的汉字 常见的:/[^\x00-\x7F]+?/ /^[\u2E80-\u9FFF]+$/ 过滤汉字即是:string.replace(/^[\u2E80-\u9FFF]+$/g, &quo ...
- git ignore 添加忽略文件不生效解决办法
在git中如果想忽略掉某个文件,不让这个文件提交到版本库中,可以使用修改根目录中 .gitignore 文件的方法(如无,则需自己手工建立此文件).这个文件每一行保存了一个匹配的规则例如: /targ ...
- centos apache源码安装过程记录
1.下载相关源文件 wget http://mirror.bjtu.edu.cn/apache/httpd/httpd-2.4.18.tar.gzwget http://mirrors.hust.ed ...
- linux下多路复用模型之Select模型
Linux关于并发网络分为Apache模型(Process per Connection (进程连接) ) 和TPC , 还有select模型,以及poll模型(一般是Epoll模型) Select模 ...
- oracle PROCEDURE AS IS区别
在存储过程(PROCEDURE)和函数(FUNCTION)中没有区别,在视图(VIEW)中只能用 ,在游标(CURSOR)中只能用IS不能用AS.