Spark SQL External Data Sources JDBC简易实现
在spark1.2版本中最令我期待的功能是External Data Sources,通过该API可以直接将External Data Sources注册成一个临时表,该表可以和已经存在的表等通过sql进行查询操作。External Data Sources API代码存放于org.apache.spark.sql包中。
具体的分析可参见OopsOutOfMemory的两篇精彩博文:
http://blog.csdn.net/oopsoom/article/details/42061077
http://blog.csdn.net/oopsoom/article/details/42064075
自己尝试实现了一个简易的读取关系型数据库的外部数据源,代码参见:https://github.com/luogankun/spark-jdbc
支持MySQL/Oracle/DB2,以及几种简单的数据类型,暂时还不支持PrunedScan、PrunedFilteredScan,仅支持TableScan,后续在接着完善。
使用步骤:
1、编译spark-jdbc代码
sbt package
2、添加jar包到spark-env.sh
export SPARK_CLASSPATH=/home/spark/software/source/spark_package/spark-jdbc/target/scala-2.10/spark-jdbc_2.-0.1.jar:$SPARK_CLASSPATH
export SPARK_CLASSPATH=/home/spark/lib/ojdbc6.jar:$SPARK_CLASSPATH
export SPARK_CLASSPATH=/home/spark/lib/db2jcc4.jar:$SPARK_CLASSPATH
export SPARK_CLASSPATH=/home/spark/lib/mysql-connector-java-3.0..jar:$SPARK_CLASSPATH
3、SQL使用:启动spark-sql
参数说明:
url :关系型数据库url
user :关系型数据库用户名
password: 关系型数据库密码
sql:关系型数据库sql查询语句
MySQL:
CREATE TEMPORARY TABLE jdbc_table
USING com.luogankun.spark.jdbc
OPTIONS (
url 'jdbc:mysql://hadoop000:3306/hive',
user 'root',
password 'root',
sql 'select TBL_ID,TBL_NAME,TBL_TYPE FROM TBLS WHERE TBL_ID < 100'
); SELECT * FROM jdbc_table;
Oracle:
CREATE TEMPORARY TABLE jdbc_table
USING com.luogankun.spark.jdbc
OPTIONS (
url 'jdbc:oracle:thin:@hadoop000:1521/ora11g',
user 'coc',
password 'coc',
sql 'select HISTORY_ID, APPROVE_ROLE_ID, APPROVE_OPINION from CI_APPROVE_HISTORY'
); SELECT * FROM jdbc_table;
DB2:
CREATE TEMPORARY TABLE jdbc_table
USING com.luogankun.spark.jdbc
OPTIONS (
url 'jdbc:db2://hadoop000:60000/CI',
user 'ci',
password 'ci',
sql 'select LABEL_ID from coc.CI_APPROVE_STATUS'
); SELECT * FROM jdbc_table;
在测试过程中遇到的问题:
如上的代码在连接MySQL数据库操作时没有问题,但是在操作Oracle或者DB2数据库时,报错如下:
09:56:48,302 [Executor task launch worker-0] ERROR Logging$class : Error in TaskCompletionListener
java.lang.AbstractMethodError: oracle.jdbc.driver.OracleResultSetImpl.isClosed()Z
at org.apache.spark.rdd.JdbcRDD$$anon$1.close(JdbcRDD.scala:99)
at org.apache.spark.util.NextIterator.closeIfNeeded(NextIterator.scala:63)
at org.apache.spark.rdd.JdbcRDD$$anon$1$$anonfun$1.apply(JdbcRDD.scala:71)
at org.apache.spark.rdd.JdbcRDD$$anon$1$$anonfun$1.apply(JdbcRDD.scala:71)
at org.apache.spark.TaskContext$$anon$1.onTaskCompletion(TaskContext.scala:85)
at org.apache.spark.TaskContext$$anonfun$markTaskCompleted$1.apply(TaskContext.scala:110)
at org.apache.spark.TaskContext$$anonfun$markTaskCompleted$1.apply(TaskContext.scala:108)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at org.apache.spark.TaskContext.markTaskCompleted(TaskContext.scala:108)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:64)
at org.apache.spark.scheduler.Task.run(Task.scala:54)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:181)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:744)
09:56:48,302 [Executor task launch worker-1] ERROR Logging$class : Error in TaskCompletionListener
跟了下JdbcRDD源代码发现,问题在于:
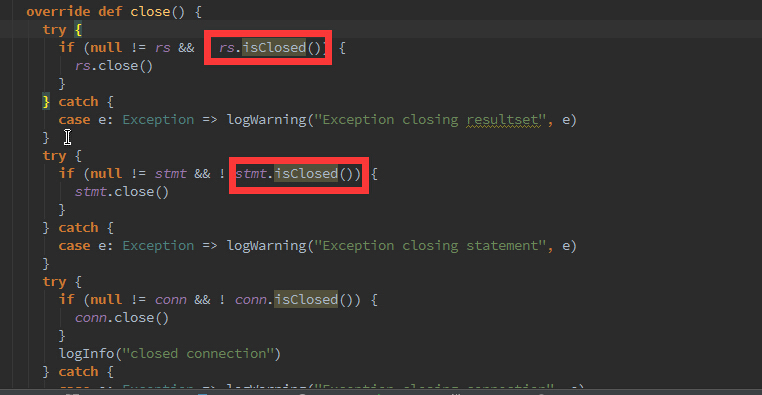
我在本案例中使用的oracle的驱动是ojdbc14-10.2.0.3.jar,查阅了些资料说是Oracle的实现类没有该方法;
该issues详见: https://issues.apache.org/jira/browse/SPARK-5239
解决办法:
1)升级驱动包;
2)暂时屏蔽掉这两个isClosed的判断方法(https://github.com/apache/spark/pull/4033)
4、Scala API使用方式
import com.luogankun.spark.jdbc._
val sqlContext = new HiveContext(sc)
val cities = sqlContext.jdbcTable("jdbc:mysql://hadoop000:3306/test", "root","root","select id, name from city")
cities.collect
后续将会继续完善,现在的实现确实很“丑陋”,凑合着先能使用吧。
Spark SQL External Data Sources JDBC简易实现的更多相关文章
- Spark SQL External Data Sources JDBC官方实现写测试
通过Spark SQL External Data Sources JDBC实现将RDD的数据写入到MySQL数据库中. jdbc.scala重要API介绍: /** * Save this RDD ...
- Spark SQL External Data Sources JDBC官方实现读测试
在最新的master分支上官方提供了Spark JDBC外部数据源的实现,先尝为快. 通过spark-shell测试: import org.apache.spark.sql.SQLContext v ...
- Spark SQL 之 Data Sources
#Spark SQL 之 Data Sources 转载请注明出处:http://www.cnblogs.com/BYRans/ 数据源(Data Source) Spark SQL的DataFram ...
- Spark(3) - External Data Source
Introduction Spark provides a unified runtime for big data. HDFS, which is Hadoop's filesystem, is t ...
- Spark SQL External DataSource简介
随着Spark1.2的发布,Spark SQL开始正式支持外部数据源.这使得Spark SQL支持了更多的类型数据源,如json, parquet, avro, csv格式.只要我们愿意,我们可以开发 ...
- How to: Provide Credentials for the Dashboards Module when Using External Data Sources
XAF中使用dashboard模块时,如果使用了sql数据源,可以使用此方法提供连接信息 https://www.devexpress.com/Support/Center/Question/Deta ...
- 【转载】Spark SQL之External DataSource外部数据源
http://blog.csdn.net/oopsoom/article/details/42061077 一.Spark SQL External DataSource简介 随着Spark1.2的发 ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- What’s new for Spark SQL in Apache Spark 1.3(中英双语)
文章标题 What’s new for Spark SQL in Apache Spark 1.3 作者介绍 Michael Armbrust 文章正文 The Apache Spark 1.3 re ...
随机推荐
- OC测试错误整理
3. NSDictionary *dict = [NSDictionary dictionaryWithObject:@"a value" forKey:@"aKey&q ...
- WIN7安装及配置JDK
1:什么是JDK? JDK是Java Development Kit 的简称,即Java开发工具包.JDK是ORACLE公司针对Java开发者的产品,提供了Java的开发环境和运行环境. 更多信息参看 ...
- 浅析Hadoop文件格式
Hadoop 作为MR 的开源实现,一直以动态运行解析文件格式并获得比MPP数据库快上几倍的装载速度为优势.不过,MPP数据库社区也一直批评Hadoop由于文件格式并非为特定目的而建,因此序列化和反序 ...
- iOS流量精灵完结版
从一开始的激动,到现在的三期完结持续了将近三个半月时间,心态也开始变的坦然. 开发期间没有兑现自己的若言,没有写下所有的感悟和困难.我没有借口可言,唯一能说的只能说自己太懒....哈哈 总体来说流量监 ...
- Python显示函数调用堆栈
网上找到如下几个思路: 1.用inspect模块 2.用sys._getframe模块 3.用sys.exc_traceback,先抛一个异常,然后抓出traceback #!/usr/bin/env ...
- Android中SQLite下 Cursor的使用。
引自博客大神一篇文 地址: http://blog.sina.com.cn/s/blog_15e2abdd90102wcdu.html rawQuery()方法用于执行select语句. /* ...
- tar.gz file installation
1. tar xzvf filename.tar.gz 2. cd filename 3. ./configure ./configure --prefix="path" 4. ...
- 电子词典的相关子函数db.c程序
整个电子词典是分块做的:包含的Dic_Server.c,Dic_Client.c,db.c,query.c,xprtcl.c,dict.h,xprtcl.h,dict.txt(单词文件) 下面是db. ...
- JavaScript取子串方法slice,substr,substring对比表
在程序语言中,字符串可以说是最常用的一种类型,而在程序中对字符串的操作也是十分频繁.当程序语言自带多种字符串操作的方法时,用该语言编程程序时就有很多的便利性,提高开发的效率.但是当方法过多,甚至目的相 ...
- Android 学习第3课,小例子
package temperature.convert; import java.util.Scanner; public class Converter { public static void m ...