SQL基础之GROUPING
1.grouping sets
记得前几天第一次接触grouping sets时,笔者的感觉是一脸懵逼。
后来一不小心看到msdn上对grouping sets的说明,顿时豁然开朗,其实grouping sets就是由多个group by联合起来,关系如下。
select A , B from table group by grouping sets(A, B) 等价于
select A , null as B from table group by A
union all
select null as A , B from table group by B
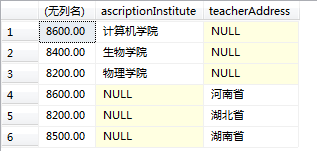
为了更好的理解我创建了teacher表,表数据如下,查询结果集中左边的为使用union all的group by字句,右边的为使用grouping sets的结果集。

select null as teacherAddress,MAX(teacherSalary),ascriptionInstitute from teacher group by ascriptionInstitute
union all
select teacherAddress,MAX(teacherSalary),NULL as ascriptionInstitute from teacher group by teacherAddress select teacherAddress,MAX(teacherSalary),ascriptionInstitute from teacher group by GROUPING SETS (ascriptionInstitute,teacherAddress)


上面提到grouping sets是等价于带union all的group by子句,之所以是等价而不是等于,从两者结果集中的对比就可以一目了之,那就是它们的顺序不一样。这说明grouping sets并不只是group by的语法糖,这两者内部的执行过程应该是全然不同的,在百度过程中发现大多数答案都是这句话:“聚合是一次性从数据库中取出所有需要操作的数据,在内存中对数据库进行聚合操作并生成结果。而UNION ALL是多次扫描表,将返回的结果进行UNION操作。性能方面grouping sets能减少IO操作但会增加CPU占用时间”。我不理解的地方是一次性取出数据后,是如何在内存中进行聚合操作的?结果集虽然顺序不一样但数据是相同的,这说明依旧进行了联合操作而这个联合操作并不是多次扫描表,关键内部多次是如何扫描的我很好奇?对于性能我想知道为什么会这样子而不是看到现象。另外在grouping sets中如果将括号中的参数换个位置那么结果也将改变,这说明结果集中的顺序与参数的位置也有关,这让我更加好奇grouping sets的内部执行过程了。
select MAX(teacherSalary),ascriptionInstitute ,teacherAddress from teacher group by GROUPING SETS (ascriptionInstitute,teacherAddress)
select MAX(teacherSalary),ascriptionInstitute ,teacherAddress from teacher group by GROUPING SETS (teacherAddress,ascriptionInstitute)

2.grouping( )
grouping函数用来区分NULL值,这里NULL值有2种情况,一是原本表中的数据就为NULL,二是由rollup、cube、grouping sets生成的NULL值。
当为第一种情况中的空值时,grouping(NULL)返回0;当为第二种情况中的空值时,grouping(NULL)返回1。实例如下,从结果中可以看到第二个结果集中原本为null的数据由于grouping函数为1,故显示ROLLUP-NULL字符串。
select teacherAddress,ascriptionInstitute,COUNT(teacherId ) from teacher group by teacherAddress,ascriptionInstitute
select teacherAddress,ascriptionInstitute,COUNT(teacherId ) from teacher group by rollup(teacherAddress,ascriptionInstitute) select ISNULL(teacherAddress,case when GROUPING(teacherAddress)=1 then 'ROLLUP-NULL' end) as teacherAddress,
ISNULL(ascriptionInstitute,case when GROUPING(ascriptionInstitute)=1 then 'ROLLUP-NULL' end) as ascriptionInstitute,
COUNT(teacherId )
from teacher group by rollup(teacherAddress,ascriptionInstitute)



3.grouping_id( )
grouping_id函数也是计算分组级别的函数,注意如果要使用grouping_id函数那必须得有group by字句,而且group by字句的中的列与grouping_id函数的参数必须相等。比如group by A,B,那么必须使用grouping_id(A,B)。下面用一个等效关系来说明grouping_id()与grouping()的联系,grouping_id(A, B)等效于grouping(A) + grouping(B),但要注意这里的+号不是算术相加,它表示的是二进制数据组合在一起,比如grouping(A)=1,grouping(B)=1,那么grouping_id(A, B)=11B,也就是十进制数3。原来的表数据执行下面的sql语句结果太多效果不明显,所以我改了下表数据,不过对比两个结果集效果很明显。
select ISNULL(teacherAddress,case when GROUPING(teacherAddress)=1 then 'ROLLUP-NULL' end) as teacherAddress,
ISNULL(ascriptionInstitute,case when GROUPING(ascriptionInstitute)=1 then 'ROLLUP-NULL' end) as ascriptionInstitute,
ISNULL(teacherSex,case when GROUPING(teacherSex)=1 then 'ROLLUP-NULL' end) as teacherSex,
COUNT(teacherId )
from teacher group by rollup(teacherAddress,ascriptionInstitute,teacherSex) select ISNULL(teacherAddress,case when GROUPING(teacherAddress)=1 then 'ROLLUP-NULL' end) as teacherAddress,
ISNULL(ascriptionInstitute,case when GROUPING(ascriptionInstitute)=1 then 'ROLLUP-NULL' end) as ascriptionInstitute,
ISNULL(teacherSex,case when GROUPING(teacherSex)=1 then 'ROLLUP-NULL' end) as teacherSex,
COUNT(teacherId ) as '数量' ,
GROUPING_ID(teacherAddress,ascriptionInstitute,teacherSex)
from teacher group by rollup(teacherAddress,ascriptionInstitute,teacherSex)


SQL基础之GROUPING的更多相关文章
- 《SQL基础教程》+ 《SQL进阶教程》 学习笔记
写在前面:本文主要注重 SQL 的理论.主流覆盖的功能范围及其基本语法/用法.至于详细的 SQL 语法/用法,因为每家 DBMS 都有些许不同,我会在以后专门介绍某款DBMS(例如 PostgreSQ ...
- [SQL] SQL 基础知识梳理(一)- 数据库与 SQL
SQL 基础知识梳理(一)- 数据库与 SQL [博主]反骨仔 [原文地址]http://www.cnblogs.com/liqingwen/p/5902856.html 目录 What's 数据库 ...
- [SQL] SQL 基础知识梳理(二) - 查询基础
SQL 基础知识梳理(二) - 查询基础 [博主]反骨仔 [原文]http://www.cnblogs.com/liqingwen/p/5904824.html 序 这是<SQL 基础知识梳理( ...
- [SQL] SQL 基础知识梳理(三) - 聚合和排序
SQL 基础知识梳理(三) - 聚合和排序 [博主]反骨仔 [原文]http://www.cnblogs.com/liqingwen/p/5926689.html 序 这是<SQL 基础知识梳理 ...
- [SQL] SQL 基础知识梳理(四) - 数据更新
SQL 基础知识梳理(四) - 数据更新 [博主]反骨仔 [原文]http://www.cnblogs.com/liqingwen/p/5929786.html 序 这是<SQL 基础知识梳理( ...
- [SQL] SQL 基础知识梳理(五) - 复杂查询
SQL 基础知识梳理(五) - 复杂查询 [博主]反骨仔 [原文]http://www.cnblogs.com/liqingwen/p/5939796.html 序 这是<SQL 基础知识梳理( ...
- 黑马程序员+SQL基础(上)
黑马程序员+SQL基础 ---------------<a href="http://edu.csdn.net"target="blank">ASP ...
- Oracle SQL 基础学习
oracel sql 基础学习 CREATE TABLE USERINFO ( ID ,) PRIMARY KEY, USERNAME ), USERPWD ), EMAIL ), REDATE DA ...
- 第一章 SQL基础
第一部分:SQL基础1. 为什么学习SQL自人类社会形成之日起,社会的运转就在不断地产生和使用各种信息(文献.档案.资料.数据等):在如今所谓的信息时代,由于计算机和互联网的作用,信息的产生和使用达到 ...
随机推荐
- druid连接池异常
在从excel导入10W条数据到mysql中时,运行一段时间就会抛这个异常,连接池问题 org.springframework.transaction.CannotCreateTransactionE ...
- HTTPS那些事(二)SSL证书
转自:http://www.guokr.com/post/116169/ 从第一部分HTTPS原理中, 我们可以了解到HTTPS核心的一个部分是数据传输之前的握手,握手过程中确定了数据加密的密码.在握 ...
- ubuntu下apache2 安装 配置 卸载 CGI设置 SSL设置
一.安装.卸载apache2 apache2可直接用命令安装 sudo apt-get install apache2 卸载比较麻烦,必须卸干净,否则会影响ap ...
- 使用DBI(perl)实现文本文件的导入导出mysql
DBI 是perl脚本连接数据库的一个模块.perl脚本相对shell更灵活,功能更强大,跨平台能力强.相对可执行jar包要简单很多. 1.下载安装包DBI-1.631.tar.gzperl脚本下载 ...
- Android 解读.apk解压后文件详细说明
转自:http://xdang.org/post-602.html 以下原文: 反编译 — 在apk文件中能得到什么 最近在做android客户端与服务器安全通信,有一种常见的不安全因素:很多软件常常 ...
- setTimeout()与setInterval()——走马灯效果
JavaScript中的setTimeout()与setInterval()都是指延时执行某一操作. 但setInterval()指每隔指定时间执行某操作,会循环不断地执行该操作:setTimeout ...
- mysql 性能优化方案 (转)
网 上有不少mysql 性能优化方案,不过,mysql的优化同sql server相比,更为麻烦与复杂,同样的设置,在不同的环境下 ,由于内存,访问量,读写频率,数据差异等等情况,可能会出现不同的结果 ...
- UESTC 33 Area --凸包面积
题意: 求一条直线分凸包两边的面积. 解法: 因为题意会说一定穿过,那么不会有直线与某条边重合的情况.我们只要找到一个直线分成的凸包即可,另一个的面积等于总面积减去那个的面积. 怎么得到分成的一个凸包 ...
- BZOJ2763[JLOI2011]飞行路线 [分层图最短路]
2763: [JLOI2011]飞行路线 Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 2523 Solved: 946[Submit][Statu ...
- save()、saveOrUpdate()、merge()的区别
一.Save() save()方法能够保存实体到数据库.假如两个实体之间有关系(例如employee表和address表有一对一关系),如果在没有事务的情况下调用这个方法保存employee这个实体, ...