Python(xlrd、xlwt模块)操作Excel实例(一)
一、前言
关于Python的xlrd、xlwt模块的使用,推介另一位博客主的博文:https://www.cnblogs.com/zhoujie/p/python18.html
这篇里面有详细介绍这两个模块的基本用法。
以下是关于我运用xlrd、xlwt模块的一个实例。需求如下:

需求是用宏去做的,但是因为时间比较紧急,我用了1天去“研究”怎么用宏去写,发现作为一个VBA入门者,比较难短时间学习并解决这个问题,因为VBA的可读性比较差的缘故吧。
于是我选择用Python去实现。
二、主体
这个需求还算比较简单,主要是分为“读”和“写”两部分。
(一)读取部分
从Excel文件“测试题.xls”里面的“表格数据1”,“表格数据2”,“数据透视表”三个sheet中提取区域和各区域的店铺,并要求同一区域内的店铺名称不重复。
需求也很简单,就是“区域”和“店铺名称”两个元素进行去重和读取。
1.读取思路
1.1读取范围
读取范围主要是从“表格数据1”,“表格数据2”,“数据透视表”三个sheet中提取区域和各区域的店铺,如下:
三个表都是从A1,B1或者A2,B2开始,但是表的末尾有些其他文字注释,于是我用的判断条件设为是否中文和是否为空值。
#构造一个函数判断是否中文
def is_Chinese(word):
for ch in word:
if '\u4e00' <= ch <= '\u9fff':
return True
return False
1.2去重判断
读取到的数据需要一个临时的“容器”,打算利用单个区域和店铺放到一个元组里面,然后把所有的元组放到一个列表里面。
然后将每个新元组和列表里面的元组对比,看是否已经存在于列表中,从而达到去重的目的。
def read_excel():
# 打开文件
workbook = xlrd.open_workbook(r'D:\安装包\测试题.xls') #写一个循环体,筛选出不重复的区域和店铺
#将涉及到区域和店铺的三个sheet中,不重复的区域和店铺名称写入元组内并存于一个列表内
sheet_name = ['表格数据1','表格数据2','数据透视表']
tup1 = []
for j in range(3):
sheet_source = workbook.sheet_by_name(sheet_name[j])
nrows = sheet_source.nrows
for i in range(nrows):
if is_Chinese(sheet_source.cell(i,0).value) == False and sheet_source.cell(i,0).value != "":
a = (sheet_source.cell(i,0).value,sheet_source.cell(i,1).value)
if a not in tup1 :
tup1.append(a)
else:
pass
else:
pass
读取完数据,按照它的需求,是要弹出一个提示框的
#python弹出窗口,提示“读取完成!”
msg.showinfo("Excel_Reading","读取已经完成!")
1.3统计店铺数量
“容器”tup1列表里面,放的是原始的数据,需要写个循环,去统计不同区域内的店铺数量。
#利用将元组转为字典,并统计各个区域的店铺数量
dict1 = {}
for i in tup1:
if i[0] not in dict1.keys():
dict1[i[0]] = 1
else:
dict1[i[0]] += 1
读取部分完成。完整代码如下:
import xlrd
import xlwt
import tkinter.messagebox as msg def is_Chinese(word):
for ch in word:
if '\u4e00' <= ch <= '\u9fff':
return True
return False #读取数据
def read_excel():
# 打开文件
workbook = xlrd.open_workbook(r'D:\安装包\测试题.xls') #写一个循环体,筛选出不重复的区域和店铺
#将涉及到区域和店铺的三个sheet中,不重复的区域和店铺名称写入元组内并存于一个列表内
sheet_name = ['表格数据1','表格数据2','数据透视表']
tup1 = []
for j in range(3):
sheet_source = workbook.sheet_by_name(sheet_name[j])
nrows = sheet_source.nrows
for i in range(nrows):
if is_Chinese(sheet_source.cell(i,0).value) == False and sheet_source.cell(i,0).value != "":
a = (sheet_source.cell(i,0).value,sheet_source.cell(i,1).value)
if a not in tup1 :
tup1.append(a)
else:
pass
else:
pass #python弹出窗口,提示“读取完成!”
msg.showinfo("Excel_Reading","读取已经完成!") #利用将元组转为字典,并统计各个区域的店铺数量
dict1 = {}
for i in tup1:
if i[0] not in dict1.keys():
dict1[i[0]] = 1
else:
dict1[i[0]] += 1
return (dict1)
(二)写入部分
需要新建一个Excel,创建一个叫“总表”的sheet,写入标题、表头,以及根据上述的read_excel函数返回的字典,写入内容。
1、样式部分
因为写入函数.write()里面有多个参数是用来设定你写入内容的样式的,所以这里做一个函数,把需要设定的参数做一个封包。
def set_style(height,bold=False):
style = xlwt.XFStyle() # 初始化样式 font = xlwt.Font() # 为样式创建字体
font.name = 'Times New Roman'
font.bold = bold
font.color_index = 4
font.height = height
style.font = font alignment = xlwt.Alignment()# 为样式创建居中方式
alignment.horz = xlwt.Alignment.HORZ_CENTER
style.alignment = alignment borders = xlwt.Borders() # 为样式创建边框
borders.left = xlwt.Borders.MEDIUM
borders.right = xlwt.Borders.MEDIUM
borders.top = xlwt.Borders.MEDIUM
borders.bottom = xlwt.Borders.MEDIUM borders.left_colour = 0x40 # 边框上色
borders.right_colour = 0x40
borders.top_colour = 0x40
borders.bottom_colour = 0x40
style.borders = borders return style
2、写入excel
def write_excel(**dd): #两个**代表输入一个字典作为参数
f = xlwt.Workbook() #创建工作簿 '''
创建第一个sheet:
sheet1
'''
sheet1 = f.add_sheet(u'总表',cell_overwrite_ok=True) #创建sheet sheet1.col(1).width = 256 * 20 #调整列宽,256是一个固定的单位 row1 = [u'区域',u'店铺数量(家)'] #生成标题
sheet1.write_merge(0,0,0,1,u'总表',set_style(300,True)) #生成第二行表头
for i in range(0,len(row1)):
sheet1.write(1,i,row1[i],set_style(220,True)) #写入数据
i = 2
for a,b in dd.items():
if b>=10: #将店铺数量大于10的数据,写入Excel
sheet1.write(i,0,a,set_style(220))
sheet1.write(i,1,b,set_style(220))
i +=1
else:
pass f.save('总表.xlsx') #保存文件,文件会保存在此Python脚本所在的文件夹内。
最后执行:
write_excel(**read_excel())
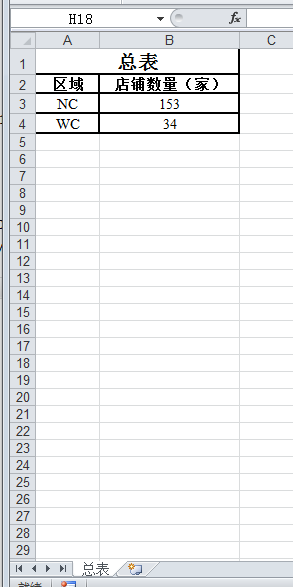
效果图:
总结
应该说Python的xlrd、xlwt模块对于Excel的数据读取和写入非常简易方便。但是在使用xlwt时,存在一个问题,就是它无法直接对现有的Excel工作表进行写入,只能新开一个Excel。或者将现有Excel复制一个副本,另存为。
Python(xlrd、xlwt模块)操作Excel实例(一)的更多相关文章
- Python使用xlwt模块 操作Excel文件
导出Excel文件 1. 使用xlwt模块 import xlwt import xlwt # 导入xlwt # 新建一个excel文件 file = xlwt.Workbook() # ...
- Python xlrd xlwt 读取写入Excel.
import xlrd import xlwt #读取 xlrd.Book.encoding = "gbk" wb = xlrd.open_workbook(filename='s ...
- xlwt 模块 操作excel
1.xlwt 基本用法 import xlwt #1 新建文件 new_file = open('test.xls', 'w') new_file.close() #2 创建工作簿 wookbook ...
- Python使用openpyxl模块操作Excel表格
''' Excel文件三个对象 workbook: 工作簿,一个excel文件包含多个sheet. sheet:工作表,一个workbook有多个,表名识别,如"sheet1",& ...
- Python中xlrd和xlwt模块读写Excel的方法
本文主要介绍可操作excel文件的xlrd.xlwt模块.其中xlrd模块实现对excel文件内容读取,xlwt模块实现对excel文件的写入. 着重掌握读取操作,因为实际工作中读取excel用得比较 ...
- Python如何读写Excel文件-使用xlrd/xlwt模块
时间: 2020-08-18 整理: qiyuan 安装和导入 1.模块介绍 在 python 中使用 xlrd/xlwt 和 openpyxl 模块可以对Excel电子表格(xls.xlsx文件)进 ...
- 用Python的pandas框架操作Excel文件中的数据教程
用Python的pandas框架操作Excel文件中的数据教程 本文的目的,是向您展示如何使用pandas 来执行一些常见的Excel任务.有些例子比较琐碎,但我觉得展示这些简单的东西与那些你可以在其 ...
- C#开发中使用Npoi操作excel实例代码
C#开发中使用Npoi操作excel实例代码 出处:西西整理 作者:西西 日期:2012/11/16 9:35:50 [大 中 小] 评论: 0 | 我要发表看法 Npoi 是什么? 1.整个Exce ...
- Python使用cx_Oracle模块操作Oracle数据库--通过sql语句和存储操作
https://www.jb51.net/article/125160.htm?utm_medium=referral Python使用cx_Oracle调用Oracle存储过程的方法示例 http ...
随机推荐
- Python基础入门-字符串
字符串详解 字符串的用法是最多的,很多功能的实现都离不开字符串,而且字符串的使用方法也很多,这里面不能说全部给大家一一介绍,只能说把一些常用的列举出来,方便回忆或者说供大家参考,谢谢!请继续往下看~~ ...
- DataAnnotationsModelValidator-基于数据注解方式的model验证器
http://www.cnblogs.com/artech/archive/2012/04/10/how-mvc-works.html http://www.cnblogs.com/artech/ar ...
- MVC下的cshtml和aspx页面
MVC中的aspx页面是System.Web.Mvc.ViewPage类的实例. 表示将视图呈现为 Web 窗体页所需的属性和方法. 继承层次结构 System.Object System.Web.U ...
- IIS 6.0 发布网站使用教程
原文地址:http://wenku.baidu.com/view/95d8b49851e79b89680226aa.html
- 使用C#代码发送邮件,不完整的demo
作为一只入行不久的小菜鸟,最近接触到利用C#代码发送邮件,做了一点小的demo练习.首先,需要配置,这边我做的是QQ邮箱的相关的练习,练习之前,首先应该解决的问题肯定是关于服务器的配置,这边偷一个懒, ...
- Winform中的DatagridView显示行号
1.设置 RowPostPaint 为true 2.启用RowPostPaint事件 /// <summary> /// DataGridView显示行号 /// </summary ...
- session相关
判断session是否已失效: HttpSession session=request.getSession(false); getSession(boolean)相比于getSession()更安全 ...
- java 图书馆系统 练习
话不多说 娱乐 ================================================== book 类(书本的基础属性) package 图书管理系统01; /** * @ ...
- react.js学习之路五
最近没时间写博客,但是我一直在学习react,我发现react是一个巨大的坑,而且永远填不完的坑 关于字符串的拼接: 在react中,字符串的拼接不允许出现双引号“” ,只能使用单引号' ',例如这样 ...
- 51nod1228 序列求和(伯努利数)
题面 传送门 题解 \(O(n^2)\)预处理伯努利数 不知道伯努利数是什么的可以看看这篇文章 不过这个数据范围拉格朗日差值应该也没问题--吧--大概-- //minamoto #include< ...