pyhton 基础数据的爬取1
1. 什么是网络爬虫?
在大数据时代,信息的采集是一项重要的工作,而互联网中的数据是海量的,如果单纯靠人力进行信息采集,不仅低效繁琐,搜集的成本也会提高。如何自动高效地获取互联网中我们感兴趣的信息并为我们所用是一个重要的问题,而爬虫技术就是为了解决这些问题而生的。
网络爬虫(Web crawler)也叫做网络机器人,可以代替人们自动地在互联网中进行数据信息的采集与整理。它是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,可以自动采集所有其能够访问到的页面内容,以获取相关数据。
从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。
2. 网络爬虫的作用
1.可以实现搜索引擎
我们学会了爬虫编写之后,就可以利用爬虫自动地采集互联网中的信息,采集回来后进行相应的存储或处理,在需要检索某些信息的时候,只需在采集回来的信息中进行检索,即实现了私人的搜索引擎。
如果想获取一个简单的网站信息该怎么做呢?
import requests # 获取百度网站信息
r = requests.get('http://www.baidu.com') # 查看状态码
print(r.status_code) # 指定字符编码
r.encoding = 'utf-8' print(r.text)
首先我们要导入requests 库 并用 r.requests.get获取到百度网站的信息 然后使用 r.status_code 查看到当前的状态码 如果是200则表示获取成功
r.encoding 指定字符编码 最后调用 r.text 将获取的内容输出出来
执行一下 我们想要的结果就出来了

那想获取网站上的商品信息又该怎么办呢
首先我们找到一个网站 搜索一件商品 点击进去 复制他的链接
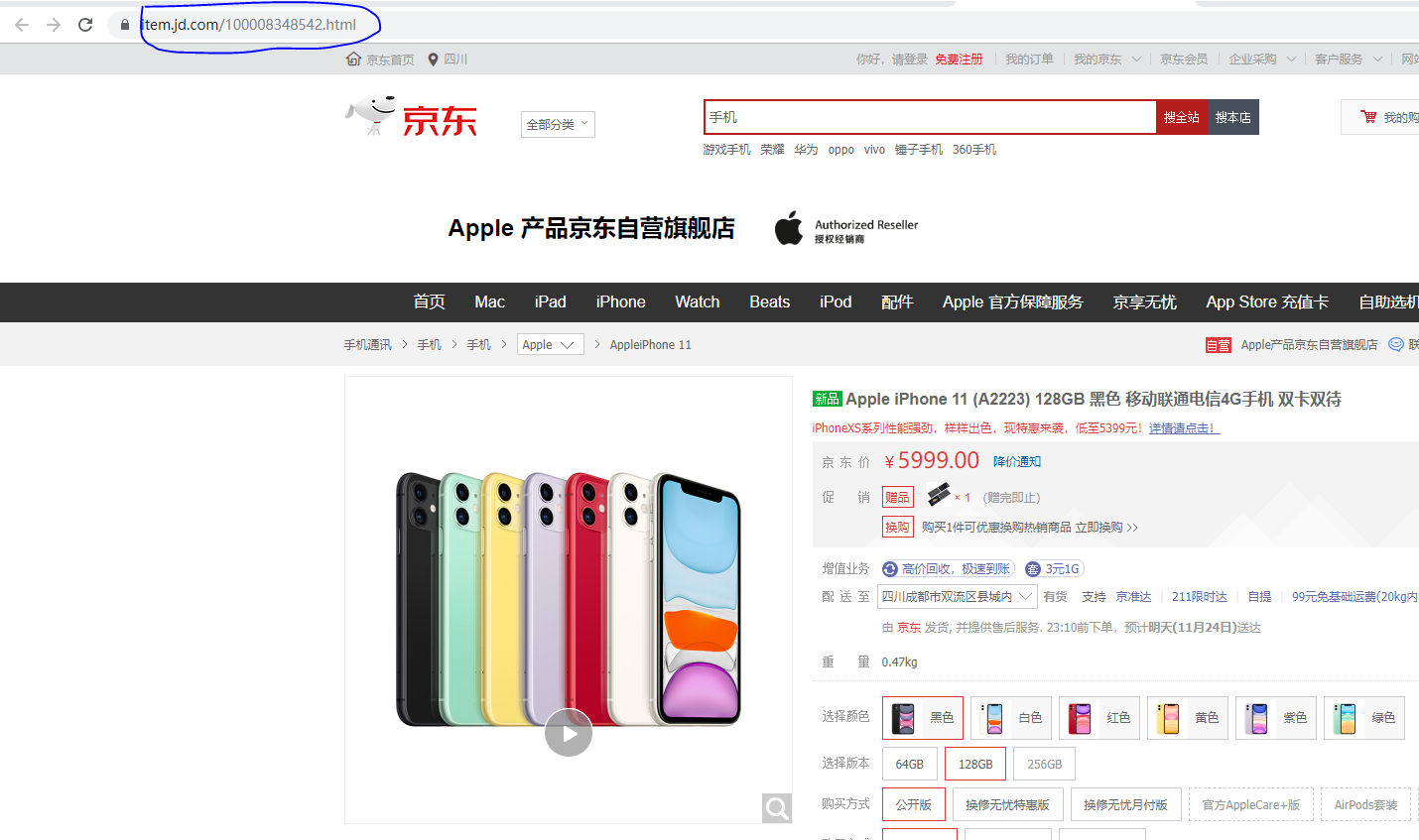
然后进行程序的编写 这里我们要用到 try 和 except 方法
import requests url = 'https://item.jd.com/100008348542.html' try:
r = requests.get(url)
r.raise_for_status() # 检测状态码如果是200则不报错 如果不是200 则抛出异常
# 获取字符编码
r.encoding = r.apparent_encoding
print(r.text[:1000]) except:
print("爬取失败")
显示结果

是不是很简单呢?
例2
import requests url = 'https://www.amazon.cn/dp/B06XGXXDV9?ref_=Oct_DLandingSV2_PC_45268aee_0&smid=A26HDXW89ZT98L' try:
kv = {"User-Agent": 'Mozilla5.0'}
r = requests.get(url, headers=kv)
# headers=kv 将自己请求头部信息更改为 kv这个字典的数据
# 若果不更改头部信息默认是以requests库的身份去访问的网站
# 有时候会导致获取信息的获取异常 我们吧头部信息该为 Mozilla5.0
# 就会让服务器认为我们是以用户的身份去访问的网站
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text)
print(r.request.headers)
except:
print("爬取失败")
如果访问一个网站信息时发现 信息没有提取出来 则有可能是访问的服务器 通过判断你的头部信息拒绝了你的访问 这时候我们就要更改自己请求头的信息了
修改前

修改后 User-Agent 被修改了

如果你想要输入一个内容 查看百度返回的结果 可以通过查看百度接口来进行获取

我们可以看到当你输入图片 上面的wd会跟着输入的改变而改变 我们通过这个可以得出 只要修改wd的值就可以查看到相应的内容
下面我们通过代码来实现一下百度的搜索
import requests
keyword=input("请输入你要查找的内容:")
try:
kv = {"wd":keyword,
"User-Agent": 'Mozilla5.0'
}
r = requests.get('http://www.baidu.com',kv)
r.raise_for_status()
print(len(r.text))
except:
print("爬取失败")
显示结果 我们以len计算一下数据的长度就可以了
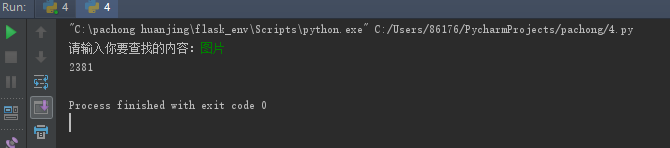
如果我们要获取网上的一张图片并将他保存在本地硬盘该怎么办呢?
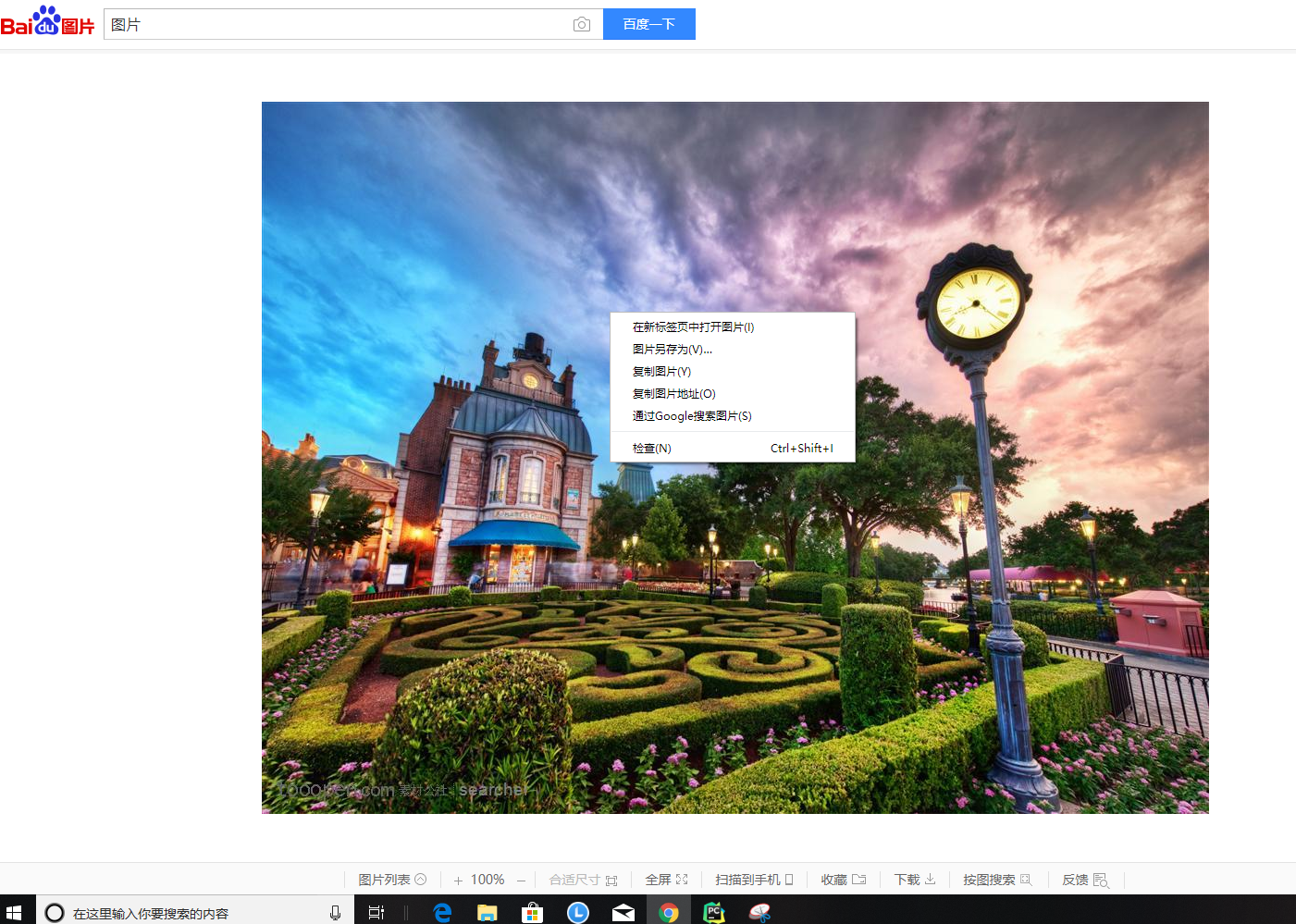
首先我们鼠标右击复制图片地址
然后进行程序的编写
import requests
import os
#图片链接
url = 'http://b-ssl.duitang.com/uploads/item/201210/03/20121003220216_xTBdK.jpeg'
root = 'D://pics//'
path = root + url.split('/')[-1] try:
if not os.path.exists(root): #判断是否有这个目录 如果没有则创建一个
os.mkdir(root)
if not os.path.exists(path): #判断是否有这个文件如果没有 则从url链接上面获取
r = requests.get(url)
with open(path,'wb') as f:
f.write(r.content) #r.content 是文件的二进制返回内容 f.write(r.content) 将返回的二进制形式写到文件中
f.close()
print("文件保存成功")
else:
print("文件已存在")
except :
print("爬取失败")
然后产看D盘是否有这个文件
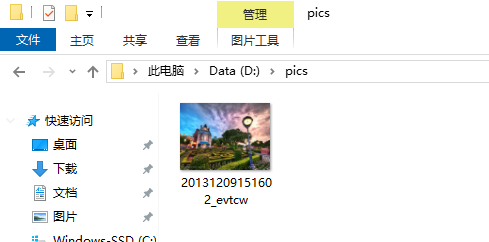
然后你就会发现图片已经保存在了本地 并且在pics目录下
pyhton 基础数据的爬取1的更多相关文章
- 爬虫(二)Python网络爬虫相关基础概念、爬取get请求的页面数据
什么是爬虫 爬虫就是通过编写程序模拟浏览器上网,然后让其去互联网上抓取数据的过程. 哪些语言可以实现爬虫 1.php:可以实现爬虫.php被号称是全世界最优美的语言(当然是其自己号称的,就是王婆 ...
- 使用 Chrome 浏览器插件 Web Scraper 10分钟轻松实现网页数据的爬取
web scraper 下载:Web-Scraper_v0.2.0.10 使用 Chrome 浏览器插件 Web Scraper 可以轻松实现网页数据的爬取,不写代码,鼠标操作,点哪爬哪,还不用考虑爬 ...
- Ajax数据的爬取(淘女郎为例)
mmtao Ajax数据的爬取(淘女郎为例) 如有疑问,转到 Wiki 淘女郎模特抓取教程 网址:https://0x9.me/xrh6z 判断一个页面是不是 Ajax 加载的方法: 查看网页源代码, ...
- Python_记一次网站数据定向爬取实现
记一次网站数据定向爬取实现 by:授客 QQ:1033553122 测试环境: Python版本:Python 3.4 Win7 请勿用于商业及非法用途,仅供学习研究用,否则后果自负 数据爬取场景 如 ...
- 爬虫--selenuim和phantonJs处理网页动态加载数据的爬取
1.谷歌浏览器的使用 下载谷歌浏览器 安装谷歌访问助手 终于用上谷歌浏览器了.....激动 问题:处理页面动态加载数据的爬取 -1.selenium -2.phantomJs 1.selenium 二 ...
- 爬虫开发6.selenuim和phantonJs处理网页动态加载数据的爬取
selenuim和phantonJs处理网页动态加载数据的爬取阅读量: 1203 动态数据加载处理 一.图片懒加载 什么是图片懒加载? 案例分析:抓取站长素材http://sc.chinaz.com/ ...
- python爬虫---CrawlSpider实现的全站数据的爬取,分布式,增量式,所有的反爬机制
CrawlSpider实现的全站数据的爬取 新建一个工程 cd 工程 创建爬虫文件:scrapy genspider -t crawl spiderName www.xxx.com 连接提取器Link ...
- (五)selenuim和phantonJs处理网页动态加载数据的爬取
selenuim和phantonJs处理网页动态加载数据的爬取 一 图片懒加载 自己理解------就是在打开一个页面的时候,图片数量特别多,图片加载会增加服务器的压力,所以我们在这个时候,就会用到- ...
- 基于java的网络爬虫框架(实现京东数据的爬取,并将插入数据库)
原文地址http://blog.csdn.net/qy20115549/article/details/52203722 本文为原创博客,仅供技术学习使用.未经允许,禁止将其复制下来上传到百度文库等平 ...
随机推荐
- MAC本地生成SSH KEY的方法
由于时间原因,直接转载,后期有空再来好好整理一下,大家先凑合着用哈: 参考链接:https://blog.csdn.net/wangjunling888/article/details/5111565 ...
- Flutter Text文本
import 'package:flutter/material.dart'; void main() { runApp( App() ); } class App extends Stateless ...
- 使用NDK(r20)编译FFmpeg
前两天在论坛上看到一个问题,大意是怎么在UBUNTU下使用NDK-r20编译FFmpeg.我第一反应是不该用r20,因为我在很早前用过没有gcc版本的NDK,发现有很多问题不能编译,就立马回复了个使用 ...
- 如何开发优质的 Flutter App:Flutter App 软件调试指南
本次博主带来的是<深入 Flutter 系列课程>第三讲,主要聊聊如何进行 Flutter App 代码的调试.本次课程将在GitChat平台上免费进行,通过本场 Chat,您将获得以下技 ...
- linux学习(十)Shell中的控制语句
目录 1. 条件测试语句 1.1 test语句 1.2[]语句 1.3文件测试 1.4字符串测试 1.5数值测试 1.5逻辑操作符 @(Shell中的控制语句) 1. 条件测试语句 测试语句十Shel ...
- [20191101]完善vim的bccalc插件8.txt
[20191101]完善vim的bccalc插件8.txt --//今天移植bccalc插件到linux,发现一些问题.我自己已经在windows下使用一段时间,从来没有在linux下测试.看来很少人 ...
- 昨天周末晚上没有出去,码了一小段,先留着kangkang。
昨天周末晚上没有出去,码了一小段,先留着kangkang. import numpy as npimport matplotlibmatplotlib.use('Agg')import matplot ...
- 算法问题实战策略 FENCE
地址 https://algospot.com/judge/problem/read/FENCE 开始考虑暴力遍历 #include <iostream> #include <str ...
- LG2679 「NOIP2015」子串 线性DP
问题描述 LG2679 题解 设\(opt[i][j]\)代表A串前\(i\)个,匹配\(B\)串前\(j\)个,选择了\(k\)个子串的方案数. 转移用前缀和优化一下. \(\mathrm{Code ...
- redhat 安装 oracle中途遇到的问题(1)
(1)安装到68%时出现弹出框 Error in invoking target 'install' of makefile '/home/oracle/app/oracle/product/11.2 ...