python3抓取淘宝评论内容
好久没有写爬虫了,今天研究了下淘宝商品评论的内容。
一开始用最简单的方法,挂代理,加请求头,对网页请求,是抓不到数据的,在网上找了一些相关文章,也基本已经过时了,就是网站逻辑有改动,用旧的方法是抓不到的。研究了一下,终于有了结果。
1. 百度->淘宝,进入官网
最后选择男装->西装,进入宝贝详情页。下面开始打开调试模式,快捷键Ctrl + Shift + i
2. 想办法找出评论内容所在地址。
先清空调试栏(点击如下):

然后刷新页面,Ctrl + R进行刷新。
下面就开始找评论在哪里。首先点击XHR,推测评论是有AJAX展示的,点击后发现不是。
再去Doc里面找找,也不是。那就从All里面一个一个找吧。
嘿,看到了一个东西,有点像:
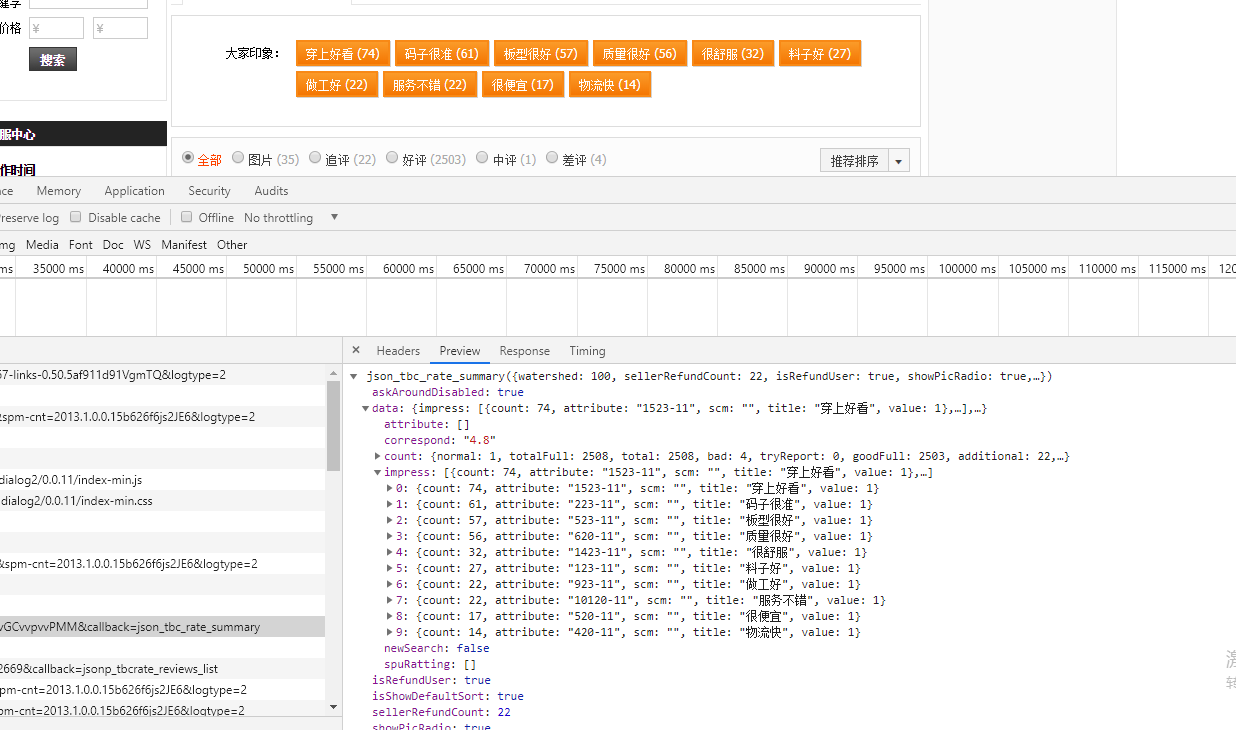
切,也不对,接着往下找。
坚持不懈地努力下,终于找到了:
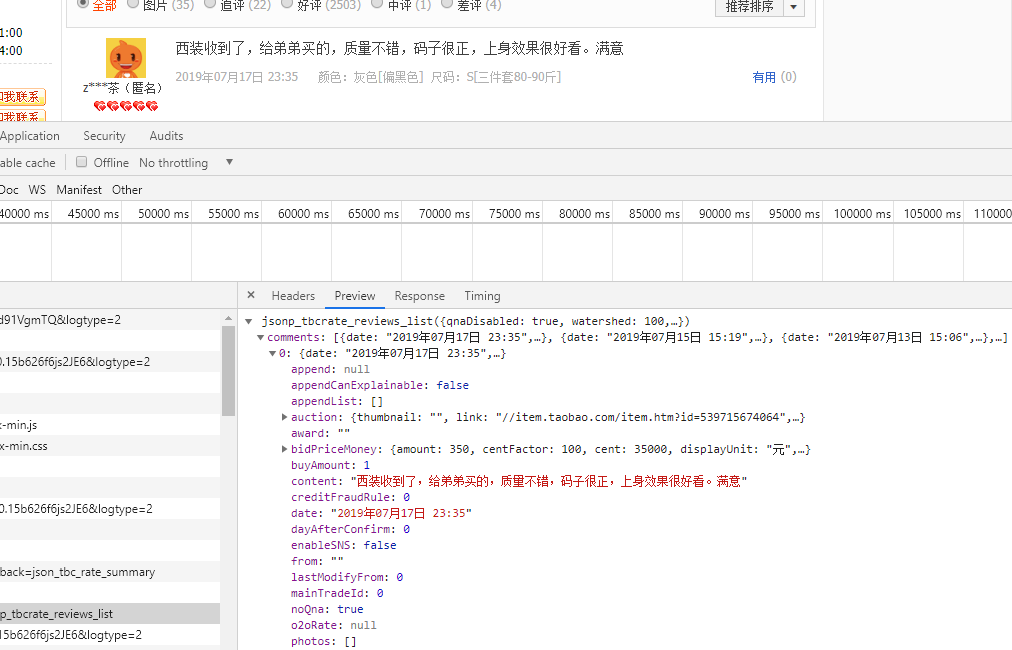
下面对这个url进行解析,只要能请求出来,那就没问题了。
3. 首先,直接添加headers,是请求不到的。那怎么办呢?一点点试呗。
最后尝试到,将请求头,请求参数全部加上,然后携带cookie,才能获取到内容,很难受。
因为,实际生产中,一旦需要验证cookie,才能获取正确响应的网站,我个人是没有太好的解决方法,只要抓取过快,就会被封掉。
代码如下:
import re
import requests headers = {
'Referer': 'https://item.taobao.com/item.htm?spm=a219r.lm874.14.173.2d324edc7BaCKr&id=591671671551&ns=1&abbucket=9',
'User-Agent': '请添加自己的useragent',
'cookie':"这里请添加你自己的cookie"
} url = 'https://rate.taobao.com/feedRateList.htm?' query_params = {
'auctionNumId': '',
'userNumId': '',
'currentPageNum': '',
'pageSize': '',
'rateType': '',
'orderType': 'sort_weight',
'attribute': '',
'sku': '',
'hasSku': 'false',
'folded': '',
'ua': '098#E1hvhpvEvbQvU9CkvvvvvjiPRFM96jECP2M91j3mPmPv1jYbRFzUljtnPLLytjEHRsKjvpvhvvpvvvhCvvOvUvvvphvEvpCWm2KHvvwzaNoUkC4AVA1lYWmQrEt1pYsptbvqrADn9W2+FfmtEpcyTWexRdIAcUmDYE7reB6k1W29QCyawZ4Q0f0DW3CQog0HsXZpebyCvm9vvvvvphvvvvvv96CvpvB/vvm2phCvhRvvvUnvphvppvvv96CvpCCvkphvC99vvOCzpuyCvv9vvUv0cP8JVvGCvvpvvvvvRphvCvvvvvm5vpvhvvmv99==',
'_ksTS': '1563849303999_1462',
'callback': 'jsonp_tbcrate_reviews_list'
} response = requests.get(url=url, headers=headers, params=query_params).text
print(response)
contents = re.compile('"content":"(.*?)"').findall(response)
for content in contents:
print(content)
代码没有任何封装,能看就行,不影响交流。至于翻页部分,就不再看了。
python3抓取淘宝评论内容的更多相关文章
- Python爬虫实战八之利用Selenium抓取淘宝匿名旺旺
更新 其实本文的初衷是为了获取淘宝的非匿名旺旺,在淘宝详情页的最下方有相关评论,含有非匿名旺旺号,快一年了淘宝都没有修复这个. 可就在今天,淘宝把所有的账号设置成了匿名显示,SO,获取非匿名旺旺号已经 ...
- 简单的抓取淘宝关键字信息、图片的Python爬虫|Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇)
Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇) 淘宝改字段,Bugfix,查看https://github.com/hunterhug/taobaoscrapy.git 由于Gith ...
- 一次Python爬虫的修改,抓取淘宝MM照片
这篇文章是2016-3-2写的,时隔一年了,淘宝的验证机制也有了改变.代码不一定有效,保留着作为一种代码学习. 崔大哥这有篇>>小白爬虫第一弹之抓取妹子图 不失为学python爬虫的绝佳教 ...
- 芝麻HTTP:Python爬虫实战之抓取淘宝MM照片
本篇目标 1.抓取淘宝MM的姓名,头像,年龄 2.抓取每一个MM的资料简介以及写真图片 3.把每一个MM的写真图片按照文件夹保存到本地 4.熟悉文件保存的过程 1.URL的格式 在这里我们用到的URL ...
- Selenium模拟浏览器抓取淘宝美食信息
前言: 无意中在网上发现了静觅大神(崔老师),又无意中发现自己硬盘里有静觅大神录制的视频,于是乎看了其中一个,可以说是非常牛逼了,让我这个用urllib,requests用了那么久的小白,体会到sel ...
- Python爬虫实战四之抓取淘宝MM照片
原文:Python爬虫实战四之抓取淘宝MM照片其实还有好多,大家可以看 Python爬虫学习系列教程 福利啊福利,本次为大家带来的项目是抓取淘宝MM照片并保存起来,大家有没有很激动呢? 本篇目标 1. ...
- python(27) 抓取淘宝买家秀
selenium 是Web应用测试工具,可以利用selenium和python,以及chromedriver等工具实现一些动态加密网站的抓取.本文利用这些工具抓取淘宝内衣评价买家秀图片. 准备工作 下 ...
- 使用CURL抓取淘宝页面
/** * 根据地址抓取淘宝页面html代码 * @param type $url 地址 * @return boolean */ public function getTaoBaoHtml($url ...
- Python爬虫学习==>第十二章:使用 Selenium 模拟浏览器抓取淘宝商品美食信息
学习目的: selenium目前版本已经到了3代目,你想加薪,就跟面试官扯这个,你赢了,工资就到位了,加上一个脚本的应用,结局你懂的 正式步骤 需求背景:抓取淘宝美食 Step1:流程分析 搜索关键字 ...
随机推荐
- Netty实现丢弃服务协议(Netty4.X学习一)
何为丢弃服务(Discard Protocol),丢弃服务就是一个协议,是最简单的协议,它的作用是接受到什么就丢弃什么,它对调试网路状态有一定的用处.基于TCP的丢弃服务,服务器实现了丢弃丢弃协议,服 ...
- mac install: /usr/bin/unrar: Operation not permitted
按照教程mac下解压缩rar文件工具-rarosx(免费),在mac上安装rar,在执行命令 sudo install -c -o $USER unrar /bin 出现错误:install: /bi ...
- luogu P1832 A+B Problem
题目背景 ·题目名称是吸引你点进来的 ·实际上该题还是很水的 题目描述 ·1+1=? 显然是2 ·a+b=? 1001回看不谢 ·哥德巴赫猜想 似乎已呈泛滥趋势 ·以上纯属个人吐槽 ·给定一个正整数n ...
- NRF5340首款双核处理器无线SoC
nRF5340基于Nordic经过验证并在全球范围广泛采用的nRF51和nRF52系列多协议SoC而构建,同时引入了具有先进安全功能的全新灵活双处理器硬件架构,支持包括蓝牙5.1/低功耗蓝牙 (Blu ...
- iOS开发之UIWebView
转自:http://www.cnblogs.com/zhuqil/archive/2011/07/28/2119923.html UIWebView是iOS sdk中一个最常用的控件.是内置的浏览器控 ...
- SpringBean生命周期及作用域
bean作用域 在Bean容器启动会读取bean的xml配置文件,然后将xml中每个bean元素分别转换成BeanDefinition对象.在BeanDefinition对象中有scope 属性,就是 ...
- hdu5969最大的位或
题目:http://acm.hdu.edu.cn/showproblem.php?pid=5969 题意:给定自然数l和r ,选取2个整数x,y,满足l <= x <= y <= r ...
- Kinect-v2 Examples with MS-SDK(译文二)
K2-asset提供的脚本组件 K2-asset在KinectScripts文件夹中提供通用脚本组件,并在KinectDemos / 文件夹的相应脚本子文件夹中提供特定于演示的组件.可以在自己的Uni ...
- python基础入门 列表
列表 1.关键字---list 2.定义:用来存储数据可存储多种数据类型 支持索引,切片 是有序的 可变的 3.定义一个列表 l1 = ['列表','字符串','lnh',123,'kk0','ttt ...
- VMware Fushion解决:与vmmon模块的版本不匹配: 需要385.0,现有330.0。
可以按下列步骤解决: 1. 退出VMware fusion2. 打开[终端]3. 执行命令:sudo rm -rf /System/Library/Extensions/vmmon.kext ,根据提 ...