python3抓取淘宝评论内容
好久没有写爬虫了,今天研究了下淘宝商品评论的内容。
一开始用最简单的方法,挂代理,加请求头,对网页请求,是抓不到数据的,在网上找了一些相关文章,也基本已经过时了,就是网站逻辑有改动,用旧的方法是抓不到的。研究了一下,终于有了结果。
1. 百度->淘宝,进入官网
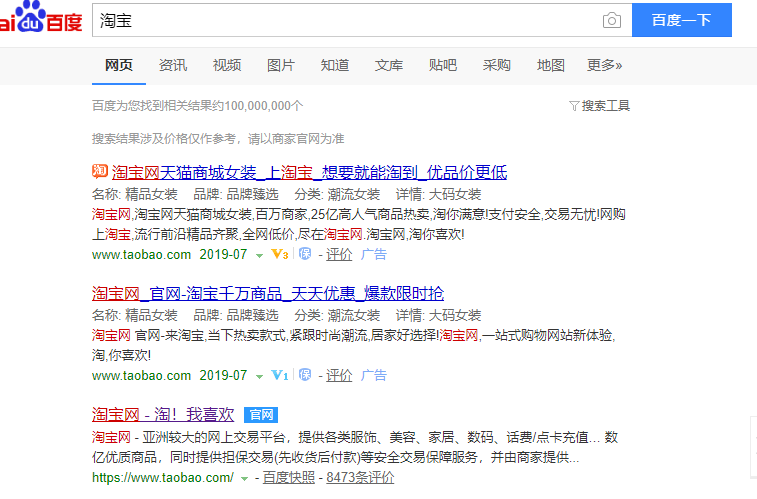
最后选择男装->西装,进入宝贝详情页。下面开始打开调试模式,快捷键Ctrl + Shift + i
2. 想办法找出评论内容所在地址。
先清空调试栏(点击如下):

然后刷新页面,Ctrl + R进行刷新。
下面就开始找评论在哪里。首先点击XHR,推测评论是有AJAX展示的,点击后发现不是。
再去Doc里面找找,也不是。那就从All里面一个一个找吧。
嘿,看到了一个东西,有点像:
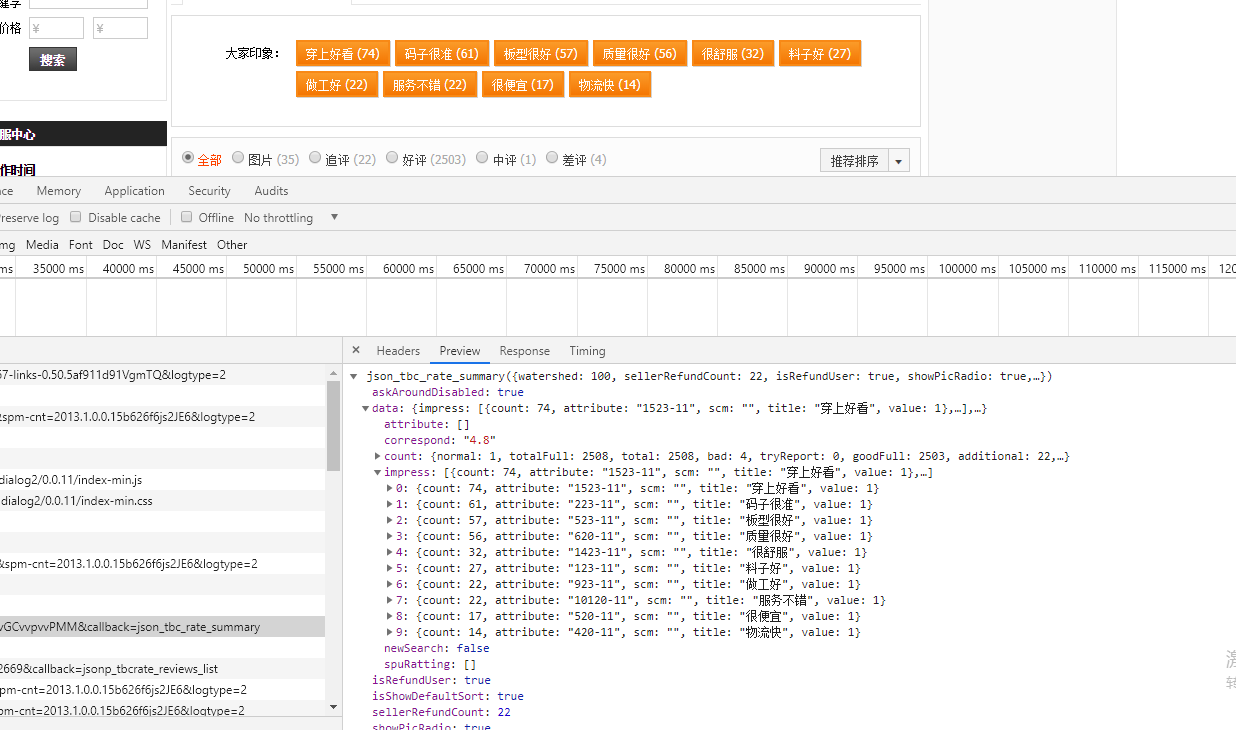
切,也不对,接着往下找。
坚持不懈地努力下,终于找到了:
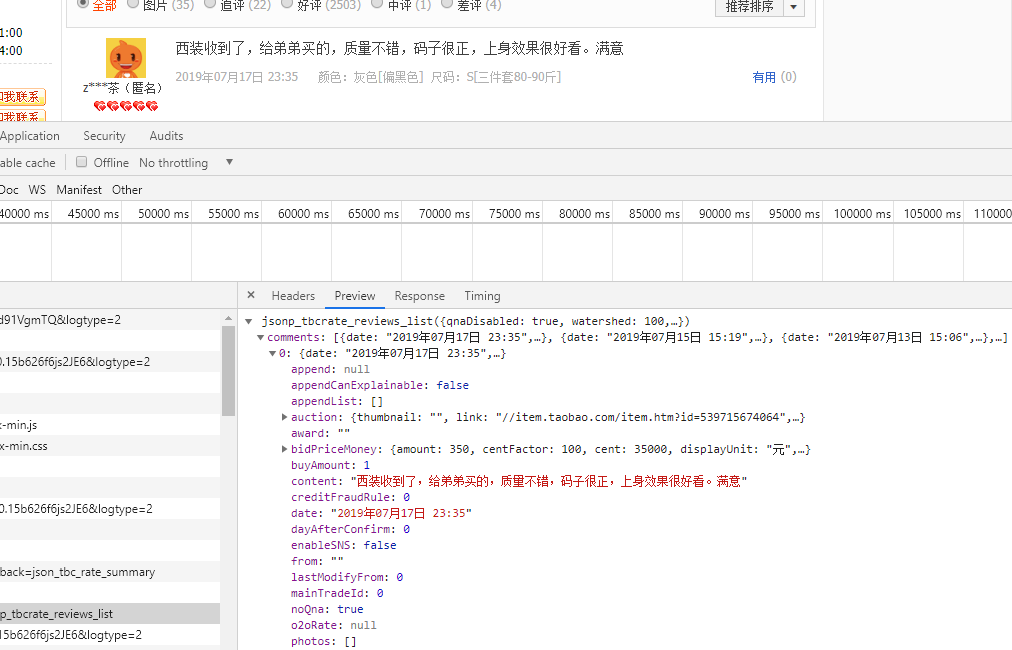
下面对这个url进行解析,只要能请求出来,那就没问题了。
3. 首先,直接添加headers,是请求不到的。那怎么办呢?一点点试呗。
最后尝试到,将请求头,请求参数全部加上,然后携带cookie,才能获取到内容,很难受。
因为,实际生产中,一旦需要验证cookie,才能获取正确响应的网站,我个人是没有太好的解决方法,只要抓取过快,就会被封掉。
代码如下:
import re
import requests headers = {
'Referer': 'https://item.taobao.com/item.htm?spm=a219r.lm874.14.173.2d324edc7BaCKr&id=591671671551&ns=1&abbucket=9',
'User-Agent': '请添加自己的useragent',
'cookie':"这里请添加你自己的cookie"
} url = 'https://rate.taobao.com/feedRateList.htm?' query_params = {
'auctionNumId': '',
'userNumId': '',
'currentPageNum': '',
'pageSize': '',
'rateType': '',
'orderType': 'sort_weight',
'attribute': '',
'sku': '',
'hasSku': 'false',
'folded': '',
'ua': '098#E1hvhpvEvbQvU9CkvvvvvjiPRFM96jECP2M91j3mPmPv1jYbRFzUljtnPLLytjEHRsKjvpvhvvpvvvhCvvOvUvvvphvEvpCWm2KHvvwzaNoUkC4AVA1lYWmQrEt1pYsptbvqrADn9W2+FfmtEpcyTWexRdIAcUmDYE7reB6k1W29QCyawZ4Q0f0DW3CQog0HsXZpebyCvm9vvvvvphvvvvvv96CvpvB/vvm2phCvhRvvvUnvphvppvvv96CvpCCvkphvC99vvOCzpuyCvv9vvUv0cP8JVvGCvvpvvvvvRphvCvvvvvm5vpvhvvmv99==',
'_ksTS': '1563849303999_1462',
'callback': 'jsonp_tbcrate_reviews_list'
} response = requests.get(url=url, headers=headers, params=query_params).text
print(response)
contents = re.compile('"content":"(.*?)"').findall(response)
for content in contents:
print(content)
代码没有任何封装,能看就行,不影响交流。至于翻页部分,就不再看了。
python3抓取淘宝评论内容的更多相关文章
- Python爬虫实战八之利用Selenium抓取淘宝匿名旺旺
更新 其实本文的初衷是为了获取淘宝的非匿名旺旺,在淘宝详情页的最下方有相关评论,含有非匿名旺旺号,快一年了淘宝都没有修复这个. 可就在今天,淘宝把所有的账号设置成了匿名显示,SO,获取非匿名旺旺号已经 ...
- 简单的抓取淘宝关键字信息、图片的Python爬虫|Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇)
Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇) 淘宝改字段,Bugfix,查看https://github.com/hunterhug/taobaoscrapy.git 由于Gith ...
- 一次Python爬虫的修改,抓取淘宝MM照片
这篇文章是2016-3-2写的,时隔一年了,淘宝的验证机制也有了改变.代码不一定有效,保留着作为一种代码学习. 崔大哥这有篇>>小白爬虫第一弹之抓取妹子图 不失为学python爬虫的绝佳教 ...
- 芝麻HTTP:Python爬虫实战之抓取淘宝MM照片
本篇目标 1.抓取淘宝MM的姓名,头像,年龄 2.抓取每一个MM的资料简介以及写真图片 3.把每一个MM的写真图片按照文件夹保存到本地 4.熟悉文件保存的过程 1.URL的格式 在这里我们用到的URL ...
- Selenium模拟浏览器抓取淘宝美食信息
前言: 无意中在网上发现了静觅大神(崔老师),又无意中发现自己硬盘里有静觅大神录制的视频,于是乎看了其中一个,可以说是非常牛逼了,让我这个用urllib,requests用了那么久的小白,体会到sel ...
- Python爬虫实战四之抓取淘宝MM照片
原文:Python爬虫实战四之抓取淘宝MM照片其实还有好多,大家可以看 Python爬虫学习系列教程 福利啊福利,本次为大家带来的项目是抓取淘宝MM照片并保存起来,大家有没有很激动呢? 本篇目标 1. ...
- python(27) 抓取淘宝买家秀
selenium 是Web应用测试工具,可以利用selenium和python,以及chromedriver等工具实现一些动态加密网站的抓取.本文利用这些工具抓取淘宝内衣评价买家秀图片. 准备工作 下 ...
- 使用CURL抓取淘宝页面
/** * 根据地址抓取淘宝页面html代码 * @param type $url 地址 * @return boolean */ public function getTaoBaoHtml($url ...
- Python爬虫学习==>第十二章:使用 Selenium 模拟浏览器抓取淘宝商品美食信息
学习目的: selenium目前版本已经到了3代目,你想加薪,就跟面试官扯这个,你赢了,工资就到位了,加上一个脚本的应用,结局你懂的 正式步骤 需求背景:抓取淘宝美食 Step1:流程分析 搜索关键字 ...
随机推荐
- 如何把图片变得炫酷多彩,Python教你这样实现!
有趣的图片 如何能让图片变得好玩?首先需要让它动起来!可如果是多张图片,我们还可以将其拼接起来组成gif动图,可一张图怎么玩?记得之前写过一个小练习,把一张图片拆分成九宫格的分片图.那么,能否由此下手 ...
- 最强Java并发编程详解:知识点梳理,BAT面试题等
本文原创更多内容可以参考: Java 全栈知识体系.如需转载请说明原处. 知识体系系统性梳理 Java 并发之基础 A. Java进阶 - Java 并发之基础:首先全局的了解并发的知识体系,同时了解 ...
- Java修炼——文件字节输入输出流复制和缓冲流复制
一:文件字节输入输出流复制 首先明确数据源和目的文件,然后就是"中转站",最后就是关闭 package com.bjsxt.ioproject; import java.io.Fi ...
- 数据库Oracle通用函数
通用函数:可用于任意数据类型,并且适用于空值.• NVL (expr1, expr2) • NVL2 (expr1, expr2, expr3) • NULLIF (expr1, expr2) • C ...
- HDU5919 Sequence II(主席树)
Mr. Frog has an integer sequence of length n, which can be denoted as a1,a2,⋯,ana1,a2,⋯,anThere are ...
- 2017 CCPC秦皇岛 L题 One Dimensions Dave
BaoBao is trapped in a one-dimensional maze consisting of grids arranged in a row! The grids are nu ...
- POJ3111
Demy has n jewels. Each of her jewels has some value vi and weight wi. Since her husband John got br ...
- 【Git】Windows 配置 SSH-Key
查看本地公钥是否存在 执行以下语句来判断是否已经存在本地公钥 cat ~/.ssh/id_rsa.pub 如果出现如下截图,则本地公钥不存在,继续按步骤进行. 如果看到一长串以 ssh-rsa 或 s ...
- 还不懂MySQL索引?这1次彻底搞懂B+树和B-树
前言 看了很多关于索引的博客,讲的大同小异.但是始终没有让我明白关于索引的一些概念,如B-Tree索引,Hash索引,唯一索引….或许有很多人和我一样,没搞清楚概念就开始研究B-Tree,B+Tree ...
- Socket与系统调用深度分析
学习一下对Socket与系统调用的分析分析 一.介绍 我们都知道高级语言的网络编程最终的实现都是调用了系统的Socket API编程接口,在操作系统提供的socket系统接口之上可以建立不同端口之间的 ...