基于Redis扩展模块的布隆过滤器使用
什么是布隆过滤器?
它实际上是一个很长的二进制向量和一系列随机映射函数。把一个目标元素通过多个hash函数的计算,将多个随机计算出的结果映射到不同的二进制向量的位中,以此来间接标记一个元素是否存在于一个集合中。
布隆过滤器可以做什么?
布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
布隆过滤器特点
如果布隆过滤器显示一个元素不存在于集合中,那么这个元素100%不存在与集合当中
如果布隆过滤器显示一个元素存在于集合中,那么很有可能存在,可能性取决于对布隆过滤器的定义(BF.RESERVE {key} {error_rate} {capacity})
布隆过滤器的原理图,这个就很容易理解了。
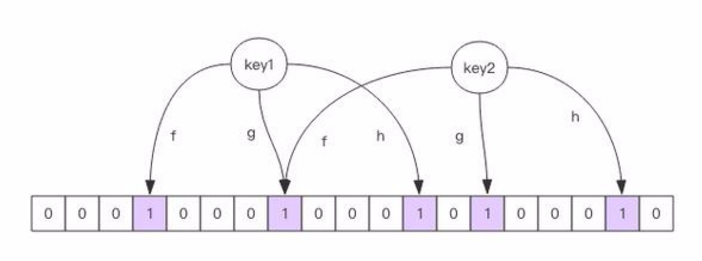
Redis中的布隆过滤器实现(rebloom模块扩展)
下载并编译
git clone git://github.com/RedisLabsModules/rebloom
cd rebloom
make
配置文件中加载rebloom
loadmodule /your_path/rebloom.so
重启Redis服务器即可
./bin/redis-cli -h 127.0.0.1 -p 6379 -a ****** shutdown
./bin/redis-server redis.conf
rebloom在Redis中的使用
bloom filter定义
BF.RESERVE {key} {error_rate} {capacity}
使用给定的期望错误率和初始容量创建空的Bloom过滤器(如果不存在的话)。如果打算向Bloom过滤器中添加许多项,则此命令非常有用,否则只能使用BF.ADD 添加项。
初始容量和错误率将决定过滤器的性能和内存使用情况。一般来说,错误率越小(即对误差的容忍度越低),每个过滤器条目的空间消耗就越大。
bloom filter基本操作
1,BF.ADD {key} {item}
单条添加元素
向Bloom filter添加一个元素,如果该key不存在,则创建该key(过滤器)。
如果项是新插入的,则为“1”;如果项以前可能存在,则为“0”。
2,BF.MADD {key} {item} [item...]
批量添加元素
布尔数(整数)的数组。返回值为0或1的范围的数据,这取决于是否将相应的输入元素新添加到过滤器中,或者是否已经存在。
3,BF.EXISTS {key} {item}
判断单个元素是否存在
如果存在,返回1,否则返回0
4,BF.MEXISTS {key} {item} [item...]
判断多个元素是否存在
布尔数(整数)的数组。返回值为0或1的范围的数据,这取决于是否将相应的元是否已经存在于key中。
127.0.0.1:> bf.reserve bloom_filter_test 0.0000001
OK
127.0.0.1:> bf.reserve bloom_filter_test 0.0000001
(error) ERR item exists
127.0.0.1:>
127.0.0.1:>
127.0.0.1:> bf.add bloom_filter_test key1
(integer)
127.0.0.1:> bf.add bloom_filter_test key2
(integer)
127.0.0.1:>
127.0.0.1:> bf.madd bloom_filter_test key2 key3 key4 key5
) (integer)
) (integer)
) (integer)
) (integer)
127.0.0.1:> bf.exists bloom_filter_test key2
(integer)
127.0.0.1:> bf.exists bloom_filter_test key3
(integer)
127.0.0.1:> bf.mexists bloom_filter_test key3 key4 key5
) (integer)
) (integer)
) (integer)
127.0.0.1:>
5,bf.insert
bf.insert{key} [CAPACITY {cap}] [ERROR {ERROR}] [NOCREATE] ITEMS {item…}
该命令将向bloom过滤器添加一个或多个项,如果它还不存在,则默认情况下创建它。有几个参数可用于修改此行为。
key:过滤器的名称
capacity:如果指定了,应该在后面加上要创建的过滤器的所需容量。如果过滤器已经存在,则忽略此参数。如果自动创建了过滤器,并且没有此参数,则使用默认容量(在模块级指定)。见bf.reserve。
error:如果指定了,后面应该跟随着新创建的过滤器的错误率(如果它还不存在)。如果自动创建过滤器而没有指定错误,则使用默认的模块级错误率。见bf.reserve。
nocreate:如果指定,表示如果过滤器不存在,就不应该创建它。如果过滤器还不存在,则返回一个错误,而不是自动创建它。如果需要在创建过滤器和添加过滤器之间进行严格的分离,可以使用这种方法。将NOCREATE与容量或错误一起指定是一个错误。
item:指示要添加到筛选器的项的开头。必须指定此参数。
127.0.0.1:> bf.insert bloom_filter_test2 items key1 key2 key3
) (integer)
) (integer)
) (integer)
127.0.0.1:> bf.insert bloom_filter_test2 items key1 key2 key3
) (integer)
) (integer)
) (integer)
127.0.0.1:> bf.insert bloom_filter_test2 capacity error 0.00001 nocreate items key1 key2 key3
) (integer)
) (integer)
) (integer)
127.0.0.1:>
127.0.0.1:> bf.insert bloom_filter_test2 capacity error 0.00001 nocreate items key4 key5 key6
) (integer)
) (integer)
) (integer)
127.0.0.1:>
bf持久化操作
对bloom过滤器进行增量保存。这对于不能适应常规save和restore模型的大型bloom filter非常有用。
第一次调用这个命令时,iter的值应该是0。这个命令将返回连续的(iter, data)对,直到(0,NULL),以表示完成
python伪代码演示:
chunks = []
iter = 0
while True:
iter, data = BF.SCANDUMP(key, iter)
if iter == 0:
break
else:
chunks.append([iter, data]) # Load it back
for chunk in chunks:
iter, data = chunk
BF.LOADCHUNK(key, iter, data)
bf.scandump示例
127.0.0.1:> bf.scandump bloom_filter_test2
) (integer)
) "\x06\x00\x00\x00\x00\x00\x00\x00\x01\x00\x00\x00\x04\x00\x00\x00\x80\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x06\x00\x00\x00\x00\x00\x00\x00{\x14\xaeG\xe1z\x84?\x88\x16\x8a\xc5\x8c+#@\a\x00\x00\x00j\x00\x00\x00\n"
127.0.0.1:> bf.scandump bloom_filter_test2
) (integer)
) "\x00\x00\x00\x00\xa2\x00\x00\x00\x00\x00\x00B\x01\x00\x00\x00\x00\x00\x00\x00\x80\x00\x00 \x00\x00\b\x00\x00\x00\x00\b\x00\x00@\x00\x01\x04\x18\x02\x00\x00\x00\x82\x00\x00\x80@\x00\b\x00\x00\x00\x00 \x00\x00@\x00\x00\x00\x00\x18\b\x00\b\x00\b\x00\x80B\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x80\x00\x00\x00\x00 (\x00\x00\x00\x00@\x00\x00\x00\x00@\x00\x00\x04\x00\x00\x00\x00\x00\x00\x00\x80\x00\x00\x00\x80\x00\x00@\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\b"
127.0.0.1:> bf.scandump bloom_filter_test2
) (integer)
) ""
127.0.0.1:>
blool filter数据类型的属性
bf.debug
这里可以看到,随着bloom filter元素的增加,其空间容量也在不断地增加
127.0.0.1:> bf.debug bloom_filter_test
) "size:5"
) "bytes:4194304 bits:33554432 hashes:24 hashwidth:64 capacity:1000200 size:5 ratio:1e-07"
127.0.0.1:>
127.0.0.1:>
127.0.0.1:> bf.debug bloom_filter_test
) "size:128955"
) "bytes:4194304 bits:33554432 hashes:24 hashwidth:64 capacity:1000200 size:128955 ratio:1e-07"
127.0.0.1:>
127.0.0.1:>
127.0.0.1:> bf.debug bloom_filter_test
) "size:380507"
) "bytes:4194304 bits:33554432 hashes:24 hashwidth:64 capacity:1000200 size:380507 ratio:1e-07"
127.0.0.1:>
127.0.0.1:>
127.0.0.1:> bf.debug bloom_filter_test
) "size:569166"
) "bytes:4194304 bits:33554432 hashes:24 hashwidth:64 capacity:1000200 size:569166 ratio:1e-07"
127.0.0.1:>
127.0.0.1:>
127.0.0.1:> bf.debug bloom_filter_test
) "size:852316"
) "bytes:4194304 bits:33554432 hashes:24 hashwidth:64 capacity:1000200 size:852316 ratio:1e-07"
127.0.0.1:>
127.0.0.1:>
127.0.0.1:> bf.debug bloom_filter_test
) "size:1000005"
) "bytes:4194304 bits:33554432 hashes:24 hashwidth:64 capacity:1000200 size:1000005 ratio:1e-07"
127.0.0.1:>
关于布隆过滤器数据类型的空间分析
redis的bigkeys选项可以分析整个实例中的big keys信息,但是无法分析出MBbloom--类型的key值得大小
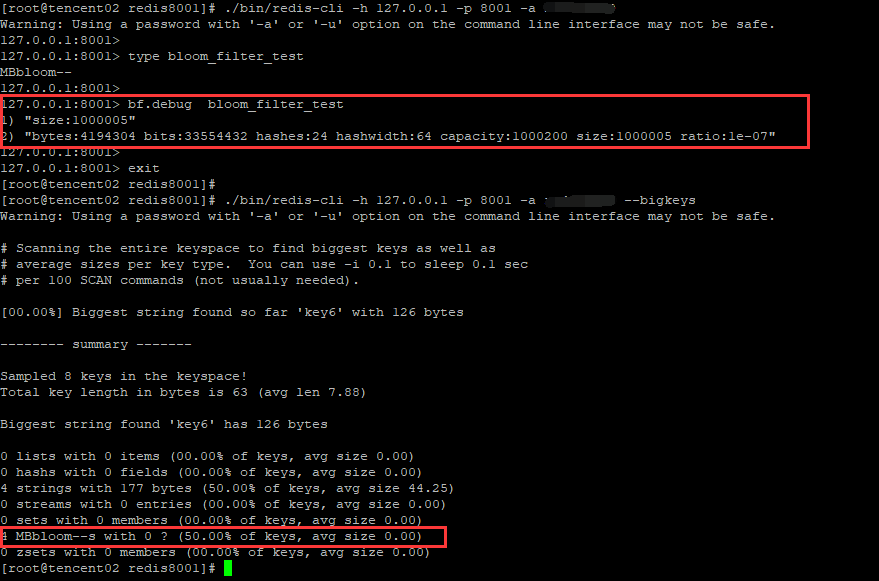
这里基于Redis的debug object功能,实现对MBbloom--类型的key的统计(没有找到怎么用Python执行bf.debug原生命令的执行方式)。
import redis
import sys
import time
import random def get_bf_bigkeys():
try:
redis_conn = redis.StrictRedis(host='127.0.0.1', port=, db=, password='******')
except:
print("connect redis error")
sys.exit()
dict_key = {}
cursor =
while cursor != :
if cursor == :
key = redis_conn.scan(cursor=, match='*', count=)
else:
key = redis_conn.scan(cursor=cursor,match='*', count=)
cursor = key[]
if len(key[]) > :
for var in key[]:
if str(redis_conn.type(var), encoding = "utf-8") == 'MBbloom--':
info = redis_conn.debug_object(var)
dict_key[var] = float(info['serializedlength']) / / # byte ---> mb res = sorted(dict_key.items(), key=lambda dict_key: dict_key[], reverse=True)
for i in range( if len(res) > else len(res)):
print(res[i]) if __name__ == "__main__":
get_bf_bigkeys()
统计结果示例如下
[root@tencent02 redis8001]# python3 static_big_bf_keys.py
(b'bloom_filter_test', 4.000059127807617)
(b'my_bf2', 0.04577445983886719)
(b'bloom_filter_test2', 0.00014019012451171875)
(b'my_bf1', 0.0001220703125)
[root@tencent02 redis8001]#
参考:
https://redislabs.com/blog/rebloom-bloom-filter-datatype-redis/
https://oss.redislabs.com/redisbloom/Bloom_Commands/
基于Redis扩展模块的布隆过滤器使用的更多相关文章
- 详细解析Redis中的布隆过滤器及其应用
欢迎关注微信公众号:万猫学社,每周一分享Java技术干货. 什么是布隆过滤器 布隆过滤器(Bloom Filter)是由Howard Bloom在1970年提出的一种比较巧妙的概率型数据结构,它可以告 ...
- Redis中的布隆过滤器及其应用
什么是布隆过滤器 布隆过滤器(Bloom Filter)是由Howard Bloom在1970年提出的一种比较巧妙的概率型数据结构,它可以告诉你某种东西一定不存在或者可能存在.当布隆过滤器说,某种东西 ...
- Redis()- 布隆过滤器
一.布隆过滤器 布隆过滤器:一种数据结构.由二进制数组(很长的二进制向量)组成的.布隆过滤器可以用于检索一个元素是否在一个集合中.它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识 ...
- Spark布隆过滤器(bloomFilter)
数据过滤在很多场景都会应用到,特别是在大数据环境下.在数据量很大的场景实现过滤或者全局去重,需要存储的数据量和计算代价是非常庞大的.很多小伙伴第一念头肯定会想到布隆过滤器,有一定的精度损失,但是存储性 ...
- Redis: 缓存过期、缓存雪崩、缓存穿透、缓存击穿(热点)、缓存并发(热点)、多级缓存、布隆过滤器
Redis: 缓存过期.缓存雪崩.缓存穿透.缓存击穿(热点).缓存并发(热点).多级缓存.布隆过滤器 2019年08月18日 16:34:24 hanchao5272 阅读数 1026更多 分类专栏: ...
- 浅谈redis的HyperLogLog与布隆过滤器
首先,HyperLogLog与布隆过滤器都是针对大数据统计存储应用场景下的知名算法. HyperLogLog是在大数据的情况下关于数据基数的空间复杂度优化实现,布隆过滤器是在大数据情况下关于检索一个元 ...
- 09 redis中布隆过滤器的使用
我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉那些已经看过的内容.问题来了,新闻客户端推荐系统如何实现推送去重的? 会想到服务器记录了用户看过的所有历史记录,当推 ...
- Redis布隆过滤器和布谷鸟过滤器
一.过滤器使用场景:比如有如下几个需求:1.原本有10亿个号码,现在又来了10万个号码,要快速准确判断这10万个号码是否在10亿个号码库中? 解决办法一:将10亿个号码存入数据库中,进行数据库查询,准 ...
- 从位图到布隆过滤器,C#实现
前言 本文将以 C# 语言来实现一个简单的布隆过滤器,为简化说明,设计得很简单,仅供学习使用. 感谢@时总百忙之中的指导. 布隆过滤器简介 布隆过滤器(Bloom filter)是一种特殊的 Hash ...
随机推荐
- k8s 开船记-修船:改 readinessProbe ,去 DaemonSet ,上 Autoscaler
(图片来自网络) 改 readinessProbe 对于昨天 k8s 尼克号发生的触礁事故,我们分析下来主要是2个原因,一是当时4个节点不够用造成部分容器负载过高而宕机,二是 readinessPro ...
- 使用flatbuffers
问题 张三是个java程序员,他写产生数据的程序.李四是个python程序员,他要用python处理张三产生的数据.最直观常用的方法就是张三用java把产生的数据保存成csv或者xml文件,然后李四用 ...
- 静态页面开发JS页面跳转加密解密URL和参数
页面跳转加密URL地址参数传递 window.location.href="foot.html?"+"good="+encodeURI(encodeURI(go ...
- LVS+Keepalived-DR模式
Environment:4台CentOS机器 两台LVS 两台web服务器 LVS主备的操作,都需要安装ipvsadm和keepalived yum -y install ipvsadm keepal ...
- centos7 redis 6379端口telnet不通
1.查看redis服务是否启动,如图所示,redis已经启动 2.查看是否监听正确的ip和端口 发现问题:端口号6379没错,但是ip是127.0.0.1,表示只能本地访问,问题就出在这. 3.修改r ...
- luogu1337 [JSOI2004]平衡点 / 吊打XXX(模拟退火)
推荐博客:模拟退火总结(模拟退火)by FlashHu.模拟退火的原理,差不多就是不断地由现有的值不断地试探,不断地转到更优的值,并在一定概率下转到较差的值. 题目传送门:luogu1337 [JSO ...
- Django基础day01
后端(******) 软件开发结构c/s http协议的由来 sql语句的由来 统一接口统一规范 HTTP协议 1.四大特性 1.基于TCP/IP作用于应用层之上的协议 2.基于请求响应 3.无状态 ...
- 防止DataGridview闪烁
在Load事件中加入 typeof(DataGridView).InvokeMember("DoubleBuffered", BindingFlags.NonPublic | Bi ...
- 《Java知识应用》Java-线程池(ScheduledExecutorService)
先回顾一下,Runnable 的使用方法. package demo.knowledgepoints.scheduledtask.run; /*** * 线程类 */public class Thre ...
- 《Dotnet9》系列-开源C# WPF项目强力推荐
时间如流水,只能流去不流回! 点赞再看,养成习惯,这是您给我创作的动力! 本文 Dotnet9 https://dotnet9.com 已收录,站长乐于分享dotnet相关技术,比如Winform.W ...