Pandas IO 操作
| 格式类型 | 数据描述 | Reader | Writer |
| text | CSV | read_csv | to_csv |
| text | JSON | read_json | to_json |
| text | HTML | read_html | to_html |
| text | clipboard | read_clipboard | to_clipboard |
| binary | Excel | read_excel | to_excel |
| binary | HDF5 | read_hdf | to_hdf |
| binary | Feather | read_feather | to_feather |
| binary | Msgpack | read_msgpack | to_msgpack |
| binary | Stata | read_stata | to_stata |
| binary | SAS | read_sas | |
| binary | Python Pickle | read_pickle | to_pickle |
| SQL | SQL | read_sql | to_sql |
| SQL | Google Big Query | read_gbq | to_gbq |
可以看到,Pandas 的 I/O API是像 pd.read_csv() 一样访问的一组顶级 reader 函数,相应的 writer 函数是像 df.to_csv() 那样访问的对象方法
文本文件读取
read_table
读取文本文件
pandas.read_table(filepath_or_buffer, sep=’\t’, header=’infer’, names=None, index_col=None, dtype=None, engine=None, nrows=None)
read_csv
读取csv文件
pandas.read_csv(filepath_or_buffer, sep=’,’, header=’infer’, names=None, index_col=None, dtype=None, engine=None, nrows=None)
参数解释:
- filepath:接收string。代表文件路径。无默认
- sep:接收string。代表分隔符。read_csv默认为“,”,read_table默认为制表符“[Tab]”
- header:接收int或sequence。表示将某行数据作为列名。默认为infer,表示自动识别
- names:接收array。表示列名。默认为None
- index_col:接收int、sequence或False。表示索引列的位置,取值为sequence则代表多重索引。默认为None
- dtype:接收dict。代表写入的数据类型(列名为key,数据格式为values)。默认为None
- engine:接收c或者python。代表数据解析引擎。默认为c
- nrows:接收int。表示读取前n行。默认为None
- read_table和read_csv函数中的sep参数是指定文本的分隔符的,如果分隔符指定错误,在读取数据的时候,每一行数据将连成一片。
- header参数是用来指定列名的,如果是None则会添加一个默认的列名。
- encoding代表文件的编码格式,常用的编码有utf-8、utf-16、gbk、gb2312、gb18030等。如果编码指定错误数据将无法读取,IPython解释器会报解析错误。
读取 csv 文件算是一种最常见的操作了。假如已经有人将一些用户的信息记录在了一个csv文件 中,我们如何通过 Pandas 读取呢
创建 csv 文件
新建文本 --> 书写内容 --> 另存为 --> 文件名.csv --> 保存 --> 文件变为类似于Excel
在新建记事本内写入
name,age,birth,sex
Tom,18.0,2000-02-10,
Bob,30.0,1988-10-17,male
读取 csv 文件
可以直接使用 pd.read_csv 来读取 csv 文件
pd.read_csv("C:\\Users\\yybwy\\Desktop\\新建文本文档 (2).csv")
"""
name age birth sex
0 Tom 18.0 2000-02-10
1 Bob 30.0 1988-10-17 male
"""
读取出来生成了一个 DataFrame,索引是自动创建的一个数字,我们可以设置参数 index_col 来将某列设置为索引,可以传入索引号或者名称
pd.read_csv("C:\\Users\\yybwy\\Desktop\\新建文本文档 (2).csv",index_col="name")
"""
age birth sex
name
Tom 18.0 2000-02-10
Bob 30.0 1988-10-17 male
"""
从 StringIO 对象中读取
from io import StringIO
data="name,age,birth,sex\nTom,18.0,2000-02-10,\nBob,30.0,1988-10-17,male"
print(data)
"""
name,age,birth,sex
Tom,18.0,2000-02-10,
Bob,30.0,1988-10-17,male
""" pd.read_csv(StringIO(data))
"""
name age birth sex
0 Tom 18.0 2000-02-10 NaN
1 Bob 30.0 1988-10-17 male
"""
分隔符设定
设置参数 sep 来自定义字段之间的分隔符,设置参数 lineterminator 来自定义每行的分隔符
data = "name|age|birth|sex~Tom|18.0|2000-02-10|~Bob|30.0|1988-10-17|male"
pd.read_csv(StringIO(data), sep="|", lineterminator="~")
"""
name age birth sex
0 Tom 18.0 2000-02-10 NaN
1 Bob 30.0 1988-10-17 male
"""
指定数据类型
在读取数据时,解析器会进行类型推断,任何非数字列都会以对象 object 的形式出现。我们可以自己指定数据类型
pd.read_csv(StringIO(data), sep="|", lineterminator="~", dtype={"age": int})
添加标题
Pandas 默认将第一行作为标题,但是有时候,csv 文件并没有标题,我们可以设置参数 names 来添加标题
data="Tom,18.0,2000-02-10,\nBob,30.0,1988-10-17,male"
print(data)
"""
Tom,18.0,2000-02-10,
Bob,30.0,1988-10-17,male
""" pd.read_csv(StringIO(data), names=["name", "age", "birth", "sex"])
"""
name age birth sex
0 Tom 18.0 2000-02-10 NaN
1 Bob 30.0 1988-10-17 male
"""
读取部分列的数据
指定参数 usercols
data="name,age,birth,sex\nTom,18.0,2000-02-10,\nBob,30.0,1988-10-17,male"
print(data)
"""
name,age,birth,sex
Tom,18.0,2000-02-10,
Bob,30.0,1988-10-17,male
""" pd.read_csv(StringIO(data), usecols=["name", "age"])
"""
name age
0 Tom 18.0
1 Bob 30.0
"""
缺失值的处理
默认参数 keep_default_na=False ,会将空值都填充为 NaN
pd.read_csv(StringIO(data), keep_default_na=False)
有时候,空值的定义比较广泛,假定我们认为 18 也是空值,那么将它加入到参数 na_values 中即可
pd.read_csv(StringIO(data), na_values=[18])
文本文件存储
to_csv
DataFrame.to_csv(path_or_buf=None, sep=’,’, na_rep=”, columns=None, header=True, index=True,index_label=None,mode=’w’,encoding=None
参数解释:
- path_or_buf:接收string。代表文件路径。无默认
- sep:接收string。代表分隔符。默认为“,”
- na_rep:接收string。代表缺失值。默认为“”
- columns:接收list。代表写出的列名。默认为None
- header:接收boolean,代表是否将列名写出。默认为True
- index:接收boolean,代表是否将行名(索引)写出。默认为True
- index_labels:接收sequence。表示索引名。默认为None
- mode:接收特定string。代表数据写入模式。默认为w
encoding:接收特定string。代表存储文件的编码格式。默认为None
把 DataFrame 中数据写入 CSV 文件,在写入过程中,就要用到 to_csv()函数,其参数为即将生成的文件名
data = "Tom,18.0,2000-02-10,\nBob,30.0,1988-10-17,male"
csv_data = pd.read_csv(StringIO(data), names=["name", "age", "birth", "sex"])
csv_data
csv_data.to_csv('C:\\Users\\yybwy\\Desktop\\hah.csv')
把 DataFrame 写入文件时,索引和列名称连同数据一起写入。使用 index 和 header 选项,把它们的值设置为 False,可取消这一默认行为
csv_data.to_csv('C:\\Users\\yybwy\\Desktop\\haha.csv',index=False,header=False)
to_json
通常在得到了 DataFrame 之后,有时候我们需要将它转为一个 json 字符串,可以使用 to_json 来完成。转换时,可以通过指定参数 orient 来输出不同的格式,以下是几个参数:
| split | 字典像索引 - > [索引],列 - > [列],数据 - > [值]} |
| records | 列表像{[列 - >值},…,{列 - >值}] |
| index | 字典像{索引 - > {列 - >值}} |
| columns | 字典像{列 - > {索引 - >值}} |
| values | 只是值数组 |
DataFrame 默认情况下使用 columns 这种形式,Series 默认情况下使用 index 这种形式
df = pd.read_csv("C:\\Users\\yybwy\\Desktop\\新建文本文档 (2).csv", index_col="name")
df
"""
age birth sex
name
Tom 18.0 2000-02-10
Bob 30.0 1988-10-17 male
"""
columns
设置为 columns 后会将数据作为嵌套 JSON 对象进行序列化,并将列标签作为主索引
print(df.to_json())
"""
{
"age":{"Tom":18.0,"Bob":30.0},
"birth":{"Tom":"2000-02-10","Bob":"1988-10-17"},
"sex ":{"Tom":" ","Bob":"male"}
}
"""
index
设置为 index 后会将数据作为嵌套 JSON 对象进行序列化,并将索引标签作为主索引
print(df.to_json(orient="index"))
"""
{
"Tom":{"age":18.0,"birth":"2000-02-10","sex ":" "},
"Bob":{"age":30.0,"birth":"1988-10-17","sex ":"male"}
}
"""
records
设置为 records 后会将数据序列化为列 - >值记录的 JSON 数组,不包括索引标签
print(df.to_json(orient="records"))
"""
[
{"age":18.0,"birth":"2000-02-10","sex ":" "},
{"age":30.0,"birth":"1988-10-17","sex ":"male"}
]
"""
values
设置为 values 后会将是一个仅用于嵌套JSON数组值,不包含列和索引标签
print(df.to_json(orient="values"))
"""
[
[18.0,"2000-02-10"," "],
[30.0,"1988-10-17","male"]
]
"""
split
设置为 split 后会将序列化为包含值,索引和列的单独条目的JSON对象
print(df.to_json(orient="split"))
"""
{
"columns":["age","birth","sex "],
"index":["Tom","Bob"],
"data":[
[18.0,"2000-02-10"," "],
[30.0,"1988-10-17","male"]
]
}
"""
练习
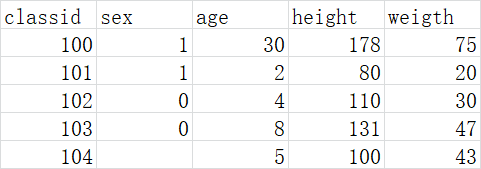
- 如果有空值就将这一行删除
- 取出身高体重两列构成新的 dataFrame
- 身高不在 50cm~170cm 范围内的删除;
- 体重不在 5kg~50kg 范围内的就删除;
- 画出身高体重散点分布图
import pandas as pd
# 读取内容
data1 = pd.read_csv("C:\\Users\yybwy\\Desktop\\新建文本文档 (3).csv")
# 有空值就将这一行删除
data2 = data1.dropna(axis=0, how="any")
# 取出身高体重两列构成新的 dataFrame
data3 = data2[['height','weigth']]
# 保留身高在50-170和体重在5-50的数据
data3[(data2.height > 50) & (data2.height < 170)& (data2.weight>5) & (data.weight<50)]
# 画出身高体重散点分布图
plt.scatter(data['height'], data['weight'])
plt.title("Height And Weight")
plt.xlabel("Height")
plt.ylabel("Weight")
Excel文件读取
read_excel
pandas.read_excel(io, sheetname=0, header=0, index_col=None, names=None, dtype=None)
参数解释:
- io:接收string。表示文件路径。无默认
- sheetname:接收string、int。代表excel表内数据的分表位置。默认为0
- header:接收int或sequence。表示将某行数据作为列名。默认为infer,表示自动识别
- names:接收int、sequence或者False。表示索引列的位置,取值为sequence则代表多重索引。默认为None
- index_col:接收int、sequence或者False。表示索引列的位置,取值为sequence则代表多重索引。默认为None
- dtype:接收dict。代表写入的数据类型(列名为key,数据格式为values)。默认为None
Excel文件储存
to_excel
DataFrame.to_excel(excel_writer=None, sheetname=None’, na_rep=”, header=True, index=True, index_label=None, mode=’w’, encoding=None)
to_csv方法的常用参数基本一致,区别之处在于指定存储文件的文件路径参数名称为excel_writer,并且没有sep参数,增加了一个sheetnames参数用来指定存储的Excel sheet的名称,默认为sheet1
数据库数据读取
Pandas提供了读取与存储关系型数据库数据的函数与方法。除了pandas库外,还需要使用SQLAlchemy库建立对应的数据库连接。SQLAlchemy配合相应数据库的Python连接工具(例如MySQL数据库需要安装mysqlclient或者pymysql库),使用create_engine函数,建立一个数据库连接
creat_engine中填入的是一个连接字符串。在使用Python的SQLAlchemy时,MySQL和Oracle数据库连接字符串的格式如下:
数据库产品名+连接工具名://用户名:密码@数据库IP地址:数据库端口号/数据库名称?charset = 数据库数据编码
import numpy as np
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:密码@127.0.0.1:3306/shujufenxi?charset=utf8')
print(engine) # Engine(mysql+pymysql://root:***@127.0.0.1:3306/shujufenxi?charset=utf8)
read_sql_table
只能够读取数据库的某一个表格,不能实现查询的操作
pandas.read_sql_table(table_name, con, schema=None, index_col=None, coerce_float=True, columns=None)
# 使用read_sql_table读取订单详情表
detail1 = pd.read_sql_table('meal_order_detail1', con=engine)
print('使用read_sql_table读取订单详情表的长度为:', len(detail1))
read_sql_query
只能实现查询操作,不能直接读取数据库中的某个表
pandas.read_sql_query(sql, con, index_col=None, coerce_float=True)
# 使用read_sql_query查看tesdb中的数据表数目
formlist = pd.read_sql_query('show tables', con=engine)
print('testdb数据库数据表清单为:', '\n', formlist)
read_sql
是两者的综合,既能够读取数据库中的某一个表,也能够实现查询操作
pandas.read_sql(sql, con, index_col=None, coerce_float=True, columns=None)
参数解释:
- sql or table_name:接收string。表示读取的数据的表名或者sql语句。无默认
- con:接收数据库连接,表示数据库连接信息。无默认
- index_col:接收int,sequence或者False。表示设定的列作为行名,如果是一个数列则是多重索引。默认为None
- coerce_float:接收boolean,将数据库中的decimal类型的数据转换为pandas中的float64类型的数据。默认为True
- columns:接收list,表示读取数据的列名。默认为None
# 使用read_sql读取订单详情表
detail2 = pd.read_sql('select * from meal_order_detail2',con=engine)
print('使用read_sql函数+sql语句读取的订单详情表长度为:', len(detail2))
detail3 = pd.read_sql('meal_order_detail3', con=engine)
print('使用read_sql函数+表格名称读取的订单详情表长度为:',len(detail3))
数据库数据存储
to_sql
DataFrame.to_sql(name, con, schema=None, if_exists=’fail’, index=True, index_label=None, dtype=None)
参数解释:
- name:接收string。代表数据库表名。无默认
- con:接收数据库连接。表示数据库连接信息。无默认
- if_exists:接收fail,replace,append。fail表示如果表名存在则不执行写入操作;replace表示如果存在,将原数据库表删除,再重新创建;append则表示在原数据库表的基础上追加数据。默认为fail
- index:接收boolean。表示是否将行索引作为数据传入数据库。默认True
- index_label:接收string或者sequence。代表是否引用索引名称,如果index参数为True此参数为None则使用默认名称。如果为多重索引必须使用sequence形式。默认为None
- dtype:接收dict。代表写入的数据类型(列名为key,数据格式为values)。默认为None
# 使用to_sql存储orderData
detail1.to_sql('test1', con=engine, index=False, if_exists='replace')
Pandas IO 操作的更多相关文章
- Pandas系列(十一)-文件IO操作
数据分析过程中经常需要进行读写操作,Pandas实现了很多 IO 操作的API,这里简单做了一个列举. 格式类型 数据描述 Reader Writer text CSV read_ csv to_cs ...
- [.NET] 利用 async & await 进行异步 IO 操作
利用 async & await 进行异步 IO 操作 [博主]反骨仔 [出处]http://www.cnblogs.com/liqingwen/p/6082673.html 序 上次,博主 ...
- 文件IO操作..修改文件的只读属性
文件的IO操作..很多同行的IO工具类都是直接写..但是如果文件有只读属性的话..则会写入失败..所以附加了一个只读的判断和修改.. 代码如下: /// <summary> /// 创建文 ...
- python之协程与IO操作
协程 协程,又称微线程,纤程.英文名Coroutine. 协程的概念很早就提出来了,但直到最近几年才在某些语言(如Lua)中得到广泛应用. 子程序,或者称为函数,在所有语言中都是层级调用,比如A调用B ...
- JAVASE02-Unit08: 文本数据IO操作 、 异常处理
Unit08: 文本数据IO操作 . 异常处理 * java.io.ObjectOutputStream * 对象输出流,作用是进行对象序列化 package day08; import java.i ...
- JAVASE02-Unit07: 基本IO操作 、 文本数据IO操作
基本IO操作 . 文本数据IO操作 java标准IO(input/output)操作 package day07; import java.io.FileOutputStream; import ja ...
- IO操作概念。同步、异步、阻塞、非阻塞
“一个IO操作其实分成了两个步骤:发起IO请求和实际的IO操作. 同步IO和异步IO的区别就在于第二个步骤是否阻塞,如果实际的IO读写阻塞请求进程,那么就是同步IO. 阻塞IO和非阻塞IO的区别在于第 ...
- Java基础复习笔记系列 七 IO操作
Java基础复习笔记系列之 IO操作 我们说的出入,都是站在程序的角度来说的.FileInputStream是读入数据.?????? 1.流是什么东西? 这章的理解的关键是:形象思维.一个管道插入了一 ...
- java中的IO操作总结
一.InputStream重用技巧(利用ByteArrayOutputStream) 对同一个InputStream对象进行使用多次. 比如,客户端从服务器获取数据 ,利用HttpURLConnect ...
随机推荐
- 排坑日记之批量从库IO进程停止
早上刚睁眼,看到了一堆数据库告警的短信,其中一个内容如下: Problem started at 05:02:58 on 2019.10.12 Problem name: Slave is stopp ...
- 移动端网页常用meta
今天在对前公司的某直播室前端进行改版时,整理了一下平时移动端页面开发时,最常用的meta.如下: <!--定义页面制作者,可以留姓名,也可以留联系方式--> <meta name=& ...
- 「3D建模」ZBrush如何雕刻头部
加载项目开始 1. 如果未显示灯箱,请按逗号(,)或灯箱按钮. 2. 单击项目选项卡,然后双击DefaultSphere项目.它将被加载到ZBrush中. 3. 在工具>几何子选项板中,将SDi ...
- VPGAME 的 Kubernetes 迁移实践
作者 | 伍冲斌 VPGAME 运维开发工程师 导读:VPGAME 是集赛事运营.媒体资讯.大数据分析.玩家社群.游戏周边等为一体的综合电竞服务平台.总部位于中国杭州,在上海和美国西雅图分别设立了电 ...
- https协议分析
一:什么是HTTPS https全称是超文本传输安全协议,https利用SSL/TLS加密数据包来进行http通信.https开发的主要目的,是提供对网站服务器的身份认证,保护交换数据的隐私与完整性. ...
- JavaScript专题之事件循环
准备知识 1. 进程(process) 进程是系统资源分配一个独立单位,一个程序至少有一个进程.比方说:一个工厂代表一个 CPU, 一个车间就是一个进程,任一时刻,只能有一个进程在运行,其他进程处于非 ...
- [NOIp2011] luogu P1311 选择客栈
我妈的抽象歌曲真 nb. 题目描述 给你 nnn 个点,每个点有两个参数 ci,dic_i,d_ici,di,给你一个数 DDD.定义一种方案合法,当且仅当你选出整数 i,j∈[1,n],i< ...
- vue内使用echarts
18年下班年用的vue + echarts,现在才想起来总结,着实不敬业 线上的项目叫股往(http://rich.xchol.com/#/) 好了,进入正题: 首先,需要新建一个vue的项目,在vu ...
- MySQL常用sql语句-----数据表的增删改操作
常用sql操作如下: 1.查看当前数据库的所有表 show tables; 2.创建表 create table stu(sid int,sname char(20),sage int default ...
- 2.单核CPU是如何实现多进程的?
单核cpu之所以能够实现多进程,主要是依靠于操作系统的进程的调度算法 如时间片轮转算法,在早期,举例说明:有5个正在运行的程序(即5个进程) : QQ 微信 有道词典 网易云 ...