设计一个A表数据抽取到B表的抽取过程
原题如下:
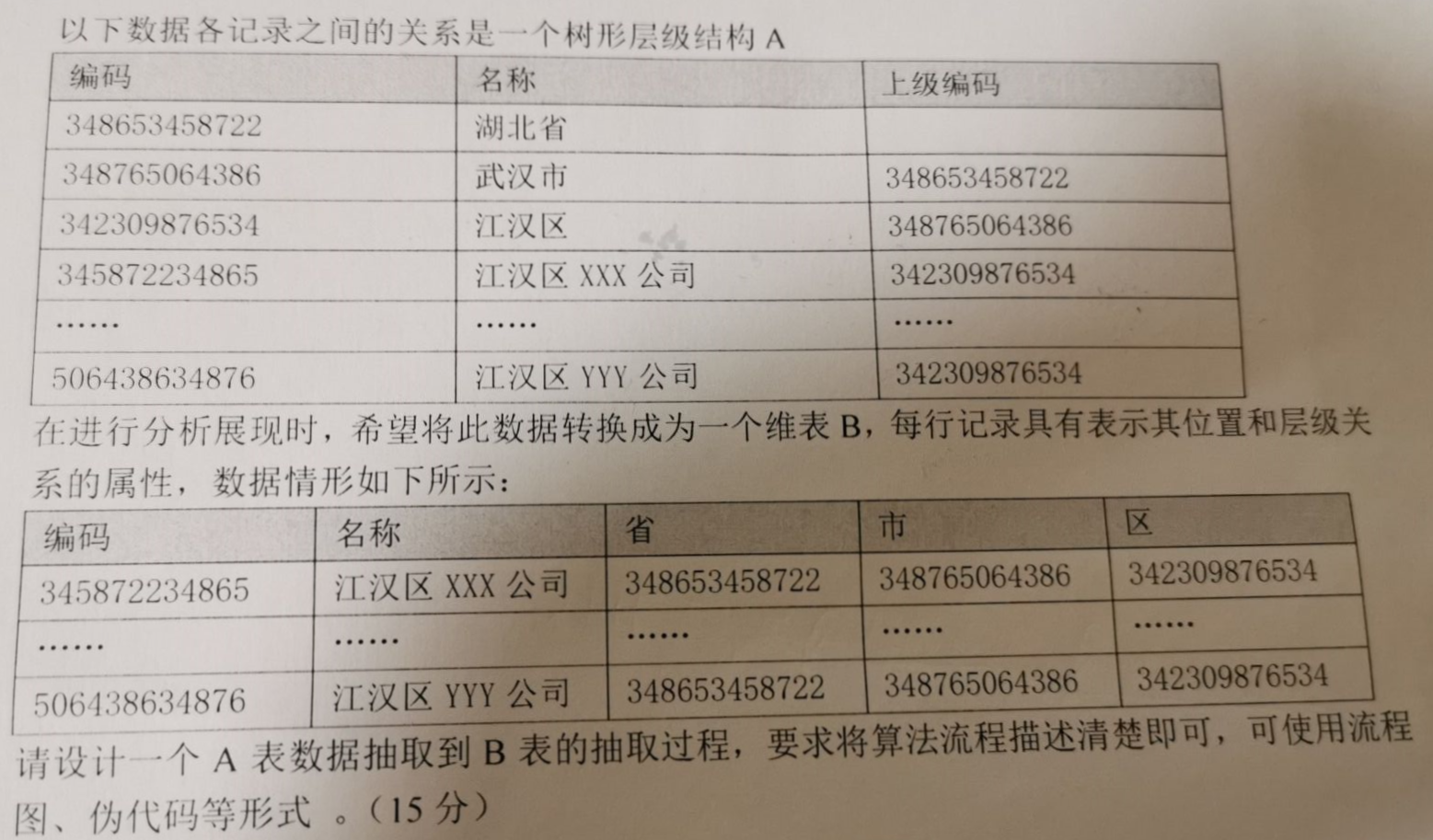
解题代码如下:
table1类:
@Data
@NoArgsConstructor
@AllArgsConstructor
public class table1{
private String num;
private String name;
private String fatherNum;
}
table2类:
@Data
@NoArgsConstructor
@AllArgsConstructor
public class table2{
private String num;
private String name;
private String sheng;
private String shi;
private String qu;
}
changeTable类:
@Data
@NoArgsConstructor
@AllArgsConstructor
class Node{
//编号
private String num;
//名称
private String name;
//父节点
private Node fatherNum;
//子节点树
private List<Node> sonNum;
}
@Data
public class changeTable {
//零散节点,key为编号
private Map<String,Node> MapData = new HashMap<>();
//结构同HashMap,list中存储的每个节点其形状都为树形,其中根为省节点
private List<Node> treeData = new ArrayList<>();
//处理完后生成的新表
private List<table2> tab = new ArrayList<>();
private void createTree(List<table1> datas) {
for(table1 data : datas) {
//为省列,直接添加到treeData中,形成树根
if(data.getFatherNum()==null) {
treeData.add(MapData.get(data.getNum()));
}else {
//当前节点中设置父亲点
MapData.get(data.getNum()).setFatherNum(MapData.get(data.getFatherNum()));
//父节点中设置孩子节点
List<Node> sonNum = MapData.get(data.getFatherNum()).getSonNum();
sonNum.add(MapData.get(data.getNum()));
MapData.get(data.getFatherNum()).setSonNum(sonNum);
}
}
}
//生成零散节点,方便获取
private void createMap(List<table1> datas) {
for(table1 data:datas) {
MapData.put(data.getNum(), new Node(data.getNum(),data.getName(),new Node(),new ArrayList<Node>()));
}
}
//生成新表数据
private void createTable2() {
for(Node node : treeData) {
//node为树根,0为深度
createRow(node,);
}
}
//使用深度优先遍历产生数据
private void createRow(Node node,int depth) {
//当能达到第三层(0层:省,1层:市,2层:区,3层:公司名),则新增数据
if(depth==) {
table2 table2 = new table2();
table2.setNum(node.getNum());
table2.setName(node.getName());
table2.setQu(node.getFatherNum().getNum());
table2.setShi(node.getFatherNum().getFatherNum().getNum());
table2.setSheng(node.getFatherNum().getFatherNum().getFatherNum().getNum());
tab.add(table2);
}else {
//遍历当前节点子节点树
for(Node nod : node.getSonNum()) {
createRow(nod,depth+);
}
}
}
public List<table2> getTable2(List<table1> dataList){
createMap(dataList);
createTree(dataList);
createTable2();
return tab;
}
}
Test类:
public class Test {
public static void main(String[] args) {
//模拟查询数据库
List<table1> dataList = new ArrayList<>();
dataList.add(new table1("","江汉区XXX公司",""));
dataList.add(new table1("","长沙市",""));
dataList.add(new table1("","武汉市",""));
dataList.add(new table1("","岳麓区",""));
dataList.add(new table1("","湖北省",null));
dataList.add(new table1("","岳麓区ZZZ公司",""));
dataList.add(new table1("","湖南省",null));
dataList.add(new table1("","江汉区",""));
dataList.add(new table1("","江汉区YYY公司",""));
//创建转换对象
changeTable changeTable = new changeTable();
//得到转换结果
List<table2> table2s = changeTable.getTable2(dataList);
for(table2 tab :table2s ) {
System.out.println(tab);
}
}
}
算法解析:
注释已经解释的非常详细了,具体过程我就不再叙述了。
其中table1与table2是两个po对象,而@data注解相当于被注解类中所有成员加上了get、set方法,@NoArgsConstructor为无参构造方法,@AllArgsConstructor为全参构造方法。
运行结果:

注意:当数据非常多时,这种设计将不再适用,因为将所有数据加载到内存中会导致栈溢出。这时可以先将数据库中所有省列查询出来,(省列没有上级编号,这就是很好的查询条件);接着循环遍历省列,根据遍历的省查询出下面所有市;然后遍历查询出来的所有市得到市下面的所有区;然后遍历区下面的所有公司,最后组装数据。虽然性能远不如一次性导入数据,但针对于数据量大时是非常好的解决办法。
设计一个A表数据抽取到B表的抽取过程的更多相关文章
- 取A表数据,关联B表任意一条数据
表A=================== AID, AName 1 jack 2 mary 3 lily 表B================== BID, AID, BName 1 1 aaa ...
- SQL Server 的表数据简单操作(表数据查询)
--表数据查询----数据的基本查询-- --数据简单的查询--select * | 字段名[,字段名2, ...] from 数据表名 [where 条件表达式] 例: use 商品管理数据库 go ...
- merge源表数据移植到目标表新表数据中
merge into dbo.ak_SloteCardTimes a using(select RecordID,CardNO,SloteCardTime from dbo.Tb_CardDate b ...
- 【database】复制表数据到相同备份表
目的及由来,因为数据库表都采取逻辑删除isDeleted=true/flase,但是之前有些报表或者其他的sql并没有在sql中指明此条件.为了不影响之前代码,所以: 1.数据库中创建一张相同的表,把 ...
- 获取B表数据添加到A表中作为一个下拉列表元素存在
1.ProductController类里toedit方法内添加: ProductModel product = ProductModel.dao.findById(id); //通过id查找服务类 ...
- mysql把A表数据插入到B表数据的几种方法
web开发中,我们经常需要将一个表的数据插入到另外一个表,有时还需要指定导入字段,设置只需要导入目标表中不存在的记录,虽然这些都可以在程序中拆分成简单sql来实现,但是用一个sql的话,会节省大量代码 ...
- java基于xml配置的通用excel单表数据导入组件(一、实际应用过程)
主要应用技术:poi + betwixt + reflect 一.实际应用过程 1.创建与目标表结构一样,表名为‘{目标表名}_import’的临时表: 2.创建用于存储导入问题数据的表:t_impo ...
- 第三方控件netadvantage UltraWebGrid如何生成带加号多级表数据也就是带子表
1.看代码不解释: ds.Relations.Add("fk", ds.Tables[0].Columns["Id"], ds.Tables[1].Column ...
- A表数据插入到B表(表结构不一致)
D_A 有E\F\H 3字段 D_B 有 A\B\C\D\E\ID 字段 将 D_B 个别字段插入到D_A 表 INSERT INTO D_A(E,F,H) select B,A,ID from ...
- Sql 将A表数据插入到B表
A表和B表字段不同 --insert into B(Name,PersonalId,Education,IsDel) select Name, PersonId as PersonalId, ( ca ...
随机推荐
- codeforces 465 C. No to Palindromes!(暴力+思维)
题目链接:http://codeforces.com/contest/465/problem/C 题意:给出一个不存在2个或以上回文子串的字符串,全是由小写字母组成而且字母下表小于p,问刚好比这个字符 ...
- Codeforces1093E_Intersection of Permutations
题意 给定两个排列a和b,两种操作,交换b_i和b_j,询问a[l_a...r_a]和b[l_b...r_b]有多少个数相同. 分析 由于给的是排列,保证b的每个数都有a的对应,构造数组c,c[i]表 ...
- Spring Cloud(一):服务注册与发现
Spring Cloud是什么 Spring Cloud是一系列框架的有序集合.它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册.配置中心.消息总线.负载均 ...
- Bootstrap4默认样式不对胃口?教你使用NPM+Webpack+SASS来定制
Bootstrap 是一个流行的前端样式库,可以方便快速的构建应用,但默认样式可能不尽人意,本文就介绍如何使用 NPM, Webpack, SASS 针对它的源码来定制自己的主题.版本使用的是 Boo ...
- 可见性有序性,Happens-before来搞定
写在前面 上一篇文章并发 Bug 之源有三,请睁大眼睛看清它们 谈到了可见性/原子性/有序性三个问题,这些问题通常违背我们的直觉和思考模式,也就导致了很多并发 Bug 为了解决 CPU,内存,IO 的 ...
- 2、顺序表的实现(java代码)
1.这里实现了简单的顺序表的,为空判断.是否已满判断,插入.删除,查询元素下标等功能 public class Linear_List { private int[] arr; //用来保存数据 pr ...
- Visual Studio Code 安装美化合集
这是一个关于VSCode编辑器的各种配置. 你可以在这里找到VSCode 的各种操作,如果这里找不到,请移步官方文档C++ programming with Visual Studio Code以及各 ...
- Mybatis值ResultMap的使用详解
Mybatis的定义 MyBatis 是一款优秀的持久层框架,它支持定制化 SQL.存储过程以及高级映射.MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集.MyBatis ...
- Linux 笔记 - 第十三章 Linux 系统日常管理之(四)Linux 中 rsync 工具和网络配置
博客地址:http://www.moonxy.com 一.前言 rsync 命令是一个远程数据同步工具,可通过 LAN/WAN 快速同步多台主机间的文件,可以理解为 remote sync(远程同步) ...
- [原创] 为Visio添加公式编辑器工具栏按钮
前言 作为理工科的学生,在写论文时,难免会在示意图中添加一些公式来说明研究内容.常用的画图工具就是 Visio .而常用的公式编辑器就是 Mathtype .对于 Word 这种软件,Mathtype ...