Scrapy爬虫及案例剖析

由于互联网的极速发展,所有现在的信息处于大量堆积的状态,我们既要向外界获取大量数据,又要在大量数据中过滤无用的数据。针对我们有益的数据需要我们进行指定抓取,从而出现了现在的爬虫技术,通过爬虫技术我们可以快速获取我们需要的数据。但是在这爬虫过程中,信息拥有方会对爬虫进行反爬处理,我们就需要对这些困难进行逐个击破。
刚好前段时间做了爬虫相关的工作,这里就记录下一些相关的心得。
本文案例代码地址 https://github.com/yangtao9502/ytaoCrawl
这里我是使用的 Scrapy 框架进行爬虫,开发环境相关版本号:
Scrapy : 1.5.1
lxml : 4.2.5.0
libxml2 : 2.9.8
cssselect : 1.0.3
parsel : 1.5.1
w3lib : 1.20.0
Twisted : 18.9.0
Python : 3.7.1 (default, Dec 10 2018, 22:54:23) [MSC v.1915 64 bit (AMD64)]
pyOpenSSL : 18.0.0 (OpenSSL 1.1.1a 20 Nov 2018)
cryptography : 2.4.2
Platform : Windows-10-10.0.15063-SP0本地开发环境建议使用 Anaconda 安装相关环境,否则可能出现各种依赖包的冲突,相信遇到过的都深有体会,在你配置相关环境的时候就失去爬虫的兴趣。
本文提取页面数据主要使用 Xpath ,所以在进行文中案例操作前,先了解 Xpath 的基本使用。
创建 Scrapy 项目
scrapy 创建项目很简单,直接一条命令搞定,接下来我们创建 ytaoCrawl 项目:
scrapy startproject ytaoCrawl注意,项目名称必须以字母开头,并且只包含字母、数字和下划线。
创建成功后界面显示:

初始化项目的文件有:
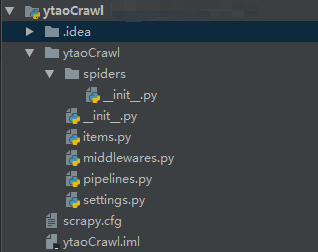
其中各个文件的用途:
- spider 目录用于存放爬虫文件。
- items.py 文件最为对象,将爬虫数据保存在该对象中。
- middlewares.py 文件为中间件处理器,比如请求和响应的转换都在里面实现。
- pipelines.py 文件为数据管道,用于数据抓取后输送。
- settings.py 文件为配置文件,爬虫中的一些配置可在该文件中设置。
- scrapy.cfg 文件为爬虫部署的配置文件。
了解几个默认生成的文件后再看下面的 scrapy 结构原理图,相对好理解。
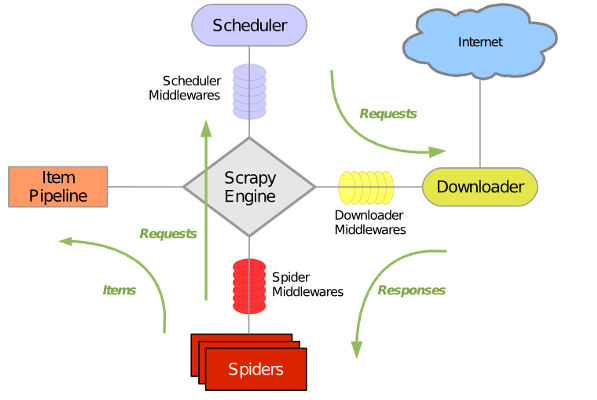
这样我们的一个 scrapy 爬虫项目就此创建完成。
创建 Spider
我们先创建一个 python 文件 ytaoSpider,该类必须继承 scrapy.Spider 类。接下来我们就以爬取北京 58 租房信息为例进行分析。
#!/usr/bin/python3
# -*- coding: utf-8 -*-
#
# @Author : YangTao
# @blog : https://ytao.top
#
import scrapy
class YtaoSpider(scrapy.Spider):
# 定义爬虫名称
name = "crawldemo"
# 允许爬取的域名,但不包含 start_urls 中的链接
allowed_domains = ["58.com"]
# 起始爬取链接
start_urls = [
"https://bj.58.com/chuzu/?PGTID=0d100000-0038-e441-0c8a-adeb346199d8&ClickID=2"
]
def download(self, response, fName):
with open(fName + ".html", 'wb') as f:
f.write(response.body)
# response 是返回抓取后的对象
def parse(self, response):
# 下载北京租房页面到本地,便于分析
self.download(response, "北京租房")通过执行命令启动爬虫,指定爬虫名字:
scrapy crawl crawldemo当我们有多个爬虫时,可以通过 scrapy list 获取所有的爬虫名。
开发过程中当然也可以用 mian 函数在编辑器中启动:
if __name__ == '__main__':
name = YtaoSpider.name
cmd = 'scrapy crawl {0} '.format(name)
cmdline.execute(cmd.split())这时将在我们启动的目录中下载生成我们爬取的页面。
翻页爬取
上面我们只爬取到了第一页,但是我们实际抓取数据过程中,必定会涉及到分页,所以观察到该网站的分页是将最后一页有展示出来(58最多只展示前七十页的数据),如图。
从下图观察到分页的 html 部分代码。
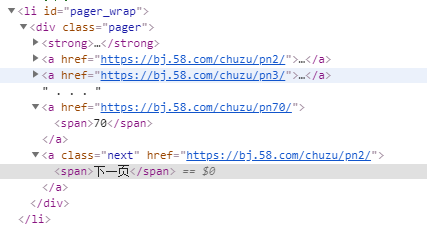
接下来通过 Xpath 和正则匹配获取最后一页的页码。
def pageNum(self, response):
# 获取分页的 html 代码块
page_ele = response.xpath("//li[@id='pager_wrap']/div[@class='pager']")
# 通过正则获取含有页码数字的文本
num_eles = re.findall(r">\d+<", page_ele.extract()[0].strip())
# 找出最大的一个
count = 0
for num_ele in num_eles:
num_ele = str(num_ele).replace(">", "").replace("<", "")
num = int(num_ele)
if num > count:
count = num
return count通过对租房链接进行分析,可以看出不同页码的链接为https://bj.58.com/chuzu/pn+num 这里的num代表页码,我们进行不同的页码抓取时,只需更换页码即可,parse 函数可更改为:
# 爬虫链接,不含页码
target_url = "https://bj.58.com/chuzu/pn"
def parse(self, response):
print("url: ", response.url)
num = self.pageNum(response)
# 开始页面本来就是第一页,所以在遍历页面时,过滤掉第一页
p = 1
while p < num:
p += 1
try:
# 拼接下一页链接
url = self.target_url + str(p)
# 进行抓取下一页
yield Request(url, callback=self.parse)
except BaseException as e:
logging.error(e)
print("爬取数据异常:", url)执行后,打印出的信息如图:
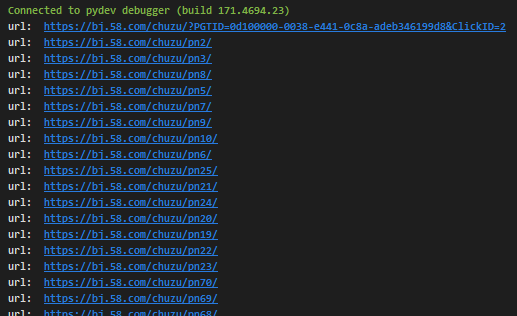
因为爬虫是异步抓取,所以我们的打印出来的并非有序数据。
上面所介绍的是通过获取最后一页的页码进行遍历抓取,但是有些网站没有最后一页的页码,这时我们可以通过下一页来判断当前页是否为最后一页,如果不是,就获取下一页所携带的链接进行爬取。
获取数据
这里我们就获取标题,面积,位置,小区,及价格信息,我们需要先在 item 中创建这些字段,闲话少说,上代码。
# 避免取xpath解析数据时索引越界
def xpath_extract(self, selector, index):
if len(selector.extract()) > index:
return selector.extract()[index].strip()
return ""
def setData(self, response):
items = []
houses = response.xpath("//ul[@class='house-list']/li[@class='house-cell']")
for house in houses:
item = YtaocrawlItem()
# 标题
item["title"] = self.xpath_extract(house.xpath("div[@class='des']/h2/a/text()"), 0)
# 面积
item["room"] = self.xpath_extract(house.xpath("div[@class='des']/p[@class='room']/text()"), 0)
# 位置
item["position"] = self.xpath_extract(house.xpath("div[@class='des']/p[@class='infor']/a/text()"), 0)
# 小区
item["quarters"] = self.xpath_extract(house.xpath("div[@class='des']/p[@class='infor']/a/text()"), 1)
money = self.xpath_extract(house.xpath("div[@class='list-li-right']/div[@class='money']/b/text()"), 0)
unit = self.xpath_extract(house.xpath("div[@class='list-li-right']/div[@class='money']/text()"), 1)
# 价格
item["price"] = money+unit
items.append(item)
return items
def parse(self, response):
items = self.setData(response)
for item in items:
yield item
# 接着上面的翻页操作 .....至此,我们以获取我们想要的数据,通过打印 parse 中的 item 可看到结果。
数据入库
我们已抓取到页面的数据,接下来就是将数据入库,这里我们以 MySQL 存储为例,数据量大的情况,建议使用使用其它存储产品。
首先我们先在 settings.py 配置文件中设置 ITEM_PIPELINES 属性,指定 Pipeline 处理类。
ITEM_PIPELINES = {
# 值越小,优先级调用越高
'ytaoCrawl.pipelines.YtaocrawlPipeline': 300,
}在 YtaocrawlPipeline 类中处理数据持久化,这里 MySQL 封装工具类 mysqlUtils 代码可在 github 中查看。
通过再 YtaoSpider#parse 中使用 yield 将数据传输到 YtaocrawlPipeline#process_item 中进行处理。
class YtaocrawlPipeline(object):
def process_item(self, item, spider):
table = "crawl"
item["id"] = str(uuid.uuid1())
# 如果当前爬取信息的链接在库中有存在,那么就删除旧的再保存新的
list = select(str.format("select * from {0} WHERE url = '{1}'", table, item["url"]))
if len(list) > 0:
for o in list:
delete_by_id(o[0], table)
insert(item, table)
return item在数据库中,可以看到成功抓取到数据并入库。

反爬机制应对
既然有数据爬虫的需求,那么就一定有反扒措施,就当前爬虫案例进行一下分析。
字体加密
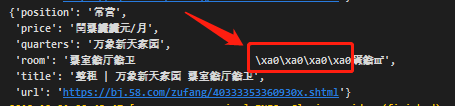
通过上面数据库数据的图,可以看到该数据中存在乱码,通过查看数据乱码规律,可以定位在数字进行了加密。

同时,通过打印数据可以看到\xa0字符,这个(代表空白符)在 ASCII 字符 0x20~0x7e 范围,可知是转换为了 ASCII 编码。
因为知道是字体加密,所以在下载的页面查看font-family字体时,发现有如下图所示代码:
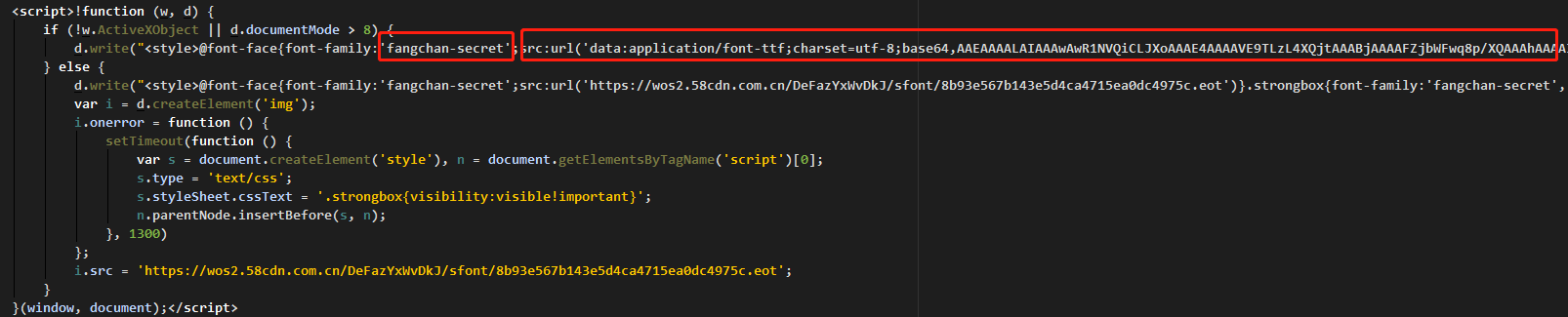
看到这个fangchan-secret字体比较可疑了,它是在js中动态生成的字体,且以 base64 存储,将以下字体进行解码操作。
if __name__ == '__main__':
secret = "AAEAAAALAIAAAwAwR1NVQiCLJXoAAAE4AAAAVE9TLzL4XQjtAAABjAAAAFZjbWFwq8p/XQAAAhAAAAIuZ2x5ZuWIN0cAAARYAAADdGhlYWQXlvp9AAAA4AAAADZoaGVhCtADIwAAALwAAAAkaG10eC7qAAAAAAHkAAAALGxvY2ED7gSyAAAEQAAAABhtYXhwARgANgAAARgAAAAgbmFtZTd6VP8AAAfMAAACanBvc3QFRAYqAAAKOAAAAEUAAQAABmb+ZgAABLEAAAAABGgAAQAAAAAAAAAAAAAAAAAAAAsAAQAAAAEAAOOjpKBfDzz1AAsIAAAAAADaB9e2AAAAANoH17YAAP/mBGgGLgAAAAgAAgAAAAAAAAABAAAACwAqAAMAAAAAAAIAAAAKAAoAAAD/AAAAAAAAAAEAAAAKADAAPgACREZMVAAObGF0bgAaAAQAAAAAAAAAAQAAAAQAAAAAAAAAAQAAAAFsaWdhAAgAAAABAAAAAQAEAAQAAAABAAgAAQAGAAAAAQAAAAEERAGQAAUAAAUTBZkAAAEeBRMFmQAAA9cAZAIQAAACAAUDAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFBmRWQAQJR2n6UGZv5mALgGZgGaAAAAAQAAAAAAAAAAAAAEsQAABLEAAASxAAAEsQAABLEAAASxAAAEsQAABLEAAASxAAAEsQAAAAAABQAAAAMAAAAsAAAABAAAAaYAAQAAAAAAoAADAAEAAAAsAAMACgAAAaYABAB0AAAAFAAQAAMABJR2lY+ZPJpLnjqeo59kn5Kfpf//AACUdpWPmTyaS546nqOfZJ+Sn6T//wAAAAAAAAAAAAAAAAAAAAAAAAABABQAFAAUABQAFAAUABQAFAAUAAAACAAGAAQAAgAKAAMACQABAAcABQAAAQYAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADAAAAAAAiAAAAAAAAAAKAACUdgAAlHYAAAAIAACVjwAAlY8AAAAGAACZPAAAmTwAAAAEAACaSwAAmksAAAACAACeOgAAnjoAAAAKAACeowAAnqMAAAADAACfZAAAn2QAAAAJAACfkgAAn5IAAAABAACfpAAAn6QAAAAHAACfpQAAn6UAAAAFAAAAAAAAACgAPgBmAJoAvgDoASQBOAF+AboAAgAA/+YEWQYnAAoAEgAAExAAISAREAAjIgATECEgERAhIFsBEAECAez+6/rs/v3IATkBNP7S/sEC6AGaAaX85v54/mEBigGB/ZcCcwKJAAABAAAAAAQ1Bi4ACQAAKQE1IREFNSURIQQ1/IgBW/6cAicBWqkEmGe0oPp7AAEAAAAABCYGJwAXAAApATUBPgE1NCYjIgc1NjMyFhUUAgcBFSEEGPxSAcK6fpSMz7y389Hym9j+nwLGqgHButl0hI2wx43iv5D+69b+pwQAAQAA/+YEGQYnACEAABMWMzI2NRAhIzUzIBE0ISIHNTYzMhYVEAUVHgEVFAAjIiePn8igu/5bgXsBdf7jo5CYy8bw/sqow/7T+tyHAQN7nYQBJqIBFP9uuVjPpf7QVwQSyZbR/wBSAAACAAAAAARoBg0ACgASAAABIxEjESE1ATMRMyERNDcjBgcBBGjGvv0uAq3jxv58BAQOLf4zAZL+bgGSfwP8/CACiUVaJlH9TwABAAD/5gQhBg0AGAAANxYzMjYQJiMiBxEhFSERNjMyBBUUACEiJ7GcqaDEx71bmgL6/bxXLPUBEv7a/v3Zbu5mswEppA4DE63+SgX42uH+6kAAAAACAAD/5gRbBicAFgAiAAABJiMiAgMzNjMyEhUUACMiABEQACEyFwEUFjMyNjU0JiMiBgP6eYTJ9AIFbvHJ8P7r1+z+8wFhASClXv1Qo4eAoJeLhKQFRj7+ov7R1f762eP+3AFxAVMBmgHjLfwBmdq8lKCytAAAAAABAAAAAARNBg0ABgAACQEjASE1IQRN/aLLAkD8+gPvBcn6NwVgrQAAAwAA/+YESgYnABUAHwApAAABJDU0JDMyFhUQBRUEERQEIyIkNRAlATQmIyIGFRQXNgEEFRQWMzI2NTQBtv7rAQTKufD+3wFT/un6zf7+AUwBnIJvaJLz+P78/uGoh4OkAy+B9avXyqD+/osEev7aweXitAEohwF7aHh9YcJlZ/7qdNhwkI9r4QAAAAACAAD/5gRGBicAFwAjAAA3FjMyEhEGJwYjIgA1NAAzMgAREAAhIicTFBYzMjY1NCYjIga5gJTQ5QICZvHD/wABGN/nAQT+sP7Xo3FxoI16pqWHfaTSSgFIAS4CAsIBDNbkASX+lf6l/lP+MjUEHJy3p3en274AAAAAABAAxgABAAAAAAABAA8AAAABAAAAAAACAAcADwABAAAAAAADAA8AFgABAAAAAAAEAA8AJQABAAAAAAAFAAsANAABAAAAAAAGAA8APwABAAAAAAAKACsATgABAAAAAAALABMAeQADAAEECQABAB4AjAADAAEECQACAA4AqgADAAEECQADAB4AuAADAAEECQAEAB4A1gADAAEECQAFABYA9AADAAEECQAGAB4BCgADAAEECQAKAFYBKAADAAEECQALACYBfmZhbmdjaGFuLXNlY3JldFJlZ3VsYXJmYW5nY2hhbi1zZWNyZXRmYW5nY2hhbi1zZWNyZXRWZXJzaW9uIDEuMGZhbmdjaGFuLXNlY3JldEdlbmVyYXRlZCBieSBzdmcydHRmIGZyb20gRm9udGVsbG8gcHJvamVjdC5odHRwOi8vZm9udGVsbG8uY29tAGYAYQBuAGcAYwBoAGEAbgAtAHMAZQBjAHIAZQB0AFIAZQBnAHUAbABhAHIAZgBhAG4AZwBjAGgAYQBuAC0AcwBlAGMAcgBlAHQAZgBhAG4AZwBjAGgAYQBuAC0AcwBlAGMAcgBlAHQAVgBlAHIAcwBpAG8AbgAgADEALgAwAGYAYQBuAGcAYwBoAGEAbgAtAHMAZQBjAHIAZQB0AEcAZQBuAGUAcgBhAHQAZQBkACAAYgB5ACAAcwB2AGcAMgB0AHQAZgAgAGYAcgBvAG0AIABGAG8AbgB0AGUAbABsAG8AIABwAHIAbwBqAGUAYwB0AC4AaAB0AHQAcAA6AC8ALwBmAG8AbgB0AGUAbABsAG8ALgBjAG8AbQAAAAIAAAAAAAAAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACwECAQMBBAEFAQYBBwEIAQkBCgELAQwAAAAAAAAAAAAAAAAAAAAA"
# 将字体文件编码转换为 UTF-8 编码的字节对象
bytes = secret.encode(encoding='UTF-8')
# base64位解码
decodebytes = base64.decodebytes(bytes)
# 利用 decodebytes 初始化 BytesIO,然后使用 TTFont 解析字体库
font = TTFont(BytesIO(decodebytes))
# 字体的映射关系
font_map = font['cmap'].tables[0].ttFont.tables['cmap'].tables[0].cmap
print(font_map)通过将 fontTools 库的 TTFont 将字体进行解析,都到如下字体映射结果:
{
38006: 'glyph00007',
38287: 'glyph00005',
39228: 'glyph00006',
39499: 'glyph00003',
40506: 'glyph00010',
40611: 'glyph00001',
40804: 'glyph00009',
40850: 'glyph00004',
40868: 'glyph00002',
40869: 'glyph00008'
}刚好十个映射,对应的 0~9 的数量,但是查找相应规律,1~9 后,出现了个 10,那么这里对应的数字到底是一个怎么样的规律呢?还有上面映射对应的 key 不是16进制的 ASCII 码,而是一个纯数字,是不是可能是十进制的码呢?
接下来验证我们的设想,将页面上获取的十六进制的码转换成十进制的码,然后去匹配映射中的数据,发现映射的值的非零数字部分刚好比页面上对应的数字字符大 1 ,可知,真正的值需要我们在映射值中减 1。
代码整理后
def decrypt(self, response, code):
secret = re.findall("charset=utf-8;base64,(.*?)'\)", response.text)[0]
code = self.secretfont(code, secret)
return code
def secretfont(self, code, secret):
# 将字体文件编码转换为 UTF-8 编码的字节对象
bytes = secret.encode(encoding='UTF-8')
# base64位解码
decodebytes = base64.decodebytes(bytes)
# 利用 decodebytes 初始化 BytesIO,然后使用 TTFont 解析字体库
font = TTFont(BytesIO(decodebytes))
# 字体的映射关系
font_map = font['cmap'].tables[0].ttFont.tables['cmap'].tables[0].cmap
chars = []
for char in code:
# 将每个字符转换成十进制的 ASCII 码
decode = ord(char)
# 如果映射关系中存在 ASCII 的 key,那么这个字符就有对应的字体
if decode in font_map:
# 获取映射的值
val = font_map[decode]
# 根据规律,获取数字部分,再减1得到真正的值
char = int(re.findall("\d+", val)[0]) - 1
chars.append(char)
return "".join(map(lambda s:str(s), chars))现在,我们将所有爬取的数据进行解密处理,再查看数据:
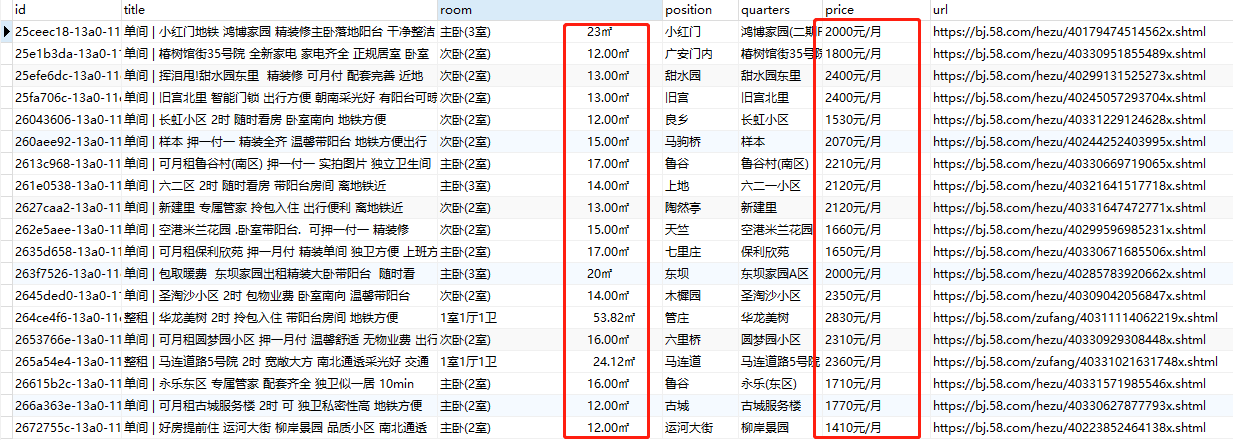
上图中,进行解密后,完美解决数据乱码!
验证码和封禁IP
验证码一般分为两类,一类是刚开始进入时,必须输入验证码的,一类是频繁请求后,需要验证码验证再继续接下来的请求。
对于第一种来说,就必须破解它的验证码才能继续,第二种来说,除了破解验证码,还可以使用代理进行绕过验证。
对于封禁IP的反爬,同样可使用代理进行绕过。比如还是使用上面的网址爬虫,当它们识别到我可能是爬虫时,就会使用验证码进行拦截,如下图:
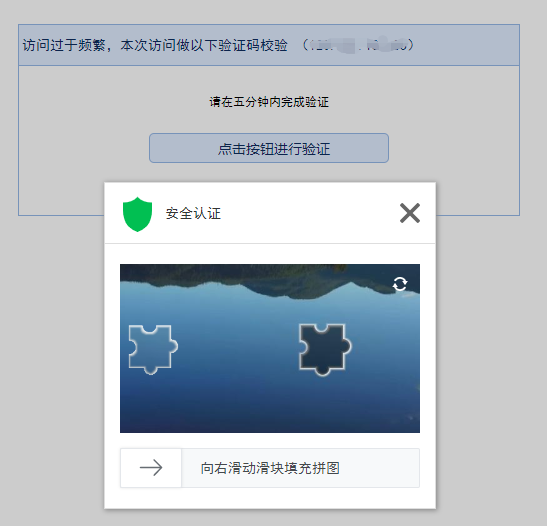
接下来,我们使用随机 User-Agent 和代理IP进行绕行。
先设置 settings.USER_AGENT,注意PC端和移动端不要混合设置的 User-Agent,否则你会爬取数据会异常,因为不同端的页面不同:
USER_AGENT = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.10 Safari/537.36",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
# ......
] 在请求中设置随机 User-Agent 中间件
class RandomUserAgentMiddleware(object):
def __init__(self, agents):
self.agent = agents
@classmethod
def from_crawler(cls, crawler):
return cls(
agents=crawler.settings.get('USER_AGENT')
)
def process_request(self, request, spider):
# 随机获取设置中的一个 User-Agent
request.headers.setdefault('User-Agent', random.choice(self.agent))设置动态IP中间件
class ProxyIPMiddleware(object):
def __init__(self, ip=''):
self.ip = ip
def process_request(self, request, spider):
# 如果当前的地址重定向到了验证码地址,就使用代理ip进行重新请求
if self.ban_url(request.url):
# 获取被重定向的地址
redirect_urls = request.meta.get("redirect_urls")[0]
# 将当前重定向到验证码的地址改为原始请求地址
request._set_url(redirect_urls)
# 设置动态代理,这里在线上一般使用接口动态生成代理
request.meta["proxy"] = "http://%s" % (self.proxy_ip())
def ban_url(self, url):
# settings中设置的验证码或被禁止的页面链接,当遇到该链接时,爬虫会进行绕行重爬
dic = settings.BAN_URLS
# 验证当前请求地址是否为验证码地址
for d in dic:
if url.find(d) != -1:
return True
return False
# 代理动态生成的 ip:port
def proxy_ip(self):
# 模拟动态生成代理地址
ips = [
"127.0.0.1:8888",
"127.0.0.1:8889",
]
return random.choice(ips);
def process_response(self, request, response, spider):
# 如果不是成功响应,则重新爬虫
if response.status != 200:
logging.error("失败响应: "+ str(response.status))
return request
return response最后在 settings 配置文件中开启这些中间件。
DOWNLOADER_MIDDLEWARES = {
'ytaoCrawl.middlewares.RandomUserAgentMiddleware': 500,
'ytaoCrawl.middlewares.ProxyIPMiddleware': 501,
'ytaoCrawl.middlewares.YtaocrawlDownloaderMiddleware': 543,
}现在为止,设置随机 User-Agent 和动态IP绕行已完成。
部署
使用 scrapyd 部署爬虫项目,可以对爬虫进行远程管理,如启动,关闭,日志调用等等。
部署前,我们得先安装 scrapyd ,使用命令:
pip install scrapyd安装成功后,可以看到该版本为 1.2.1。

部署后,我们还需要一个客户端进行访问,这里就需要一个 scrapyd-client 客户端:
pip install scrapyd-client修改 scrapy.cfg 文件
[settings]
default = ytaoCrawl.settings
[deploy:localytao]
url = http://localhost:6800/
project = ytaoCrawl
# deploy 可批量部署启动 scrapyd:
scrapyd如果是 Windows,要先在X:\xx\Scripts下创建scrapyd-deploy.bat文件
@echo off
"X:\xx\python.exe" "X:\xx\Scripts\scrapyd-deploy" %1 %2项目部署到 Scrapyd 服务上:
scrapyd-deploy localytao -p ytaoCrawl远程启动
curl http://localhost:6800/schedule.json -d project=ytaoCrawl -d spider=ytaoSpider
执行启动后,可以在http://localhost:6800/中查看爬虫执行状态,以及日志
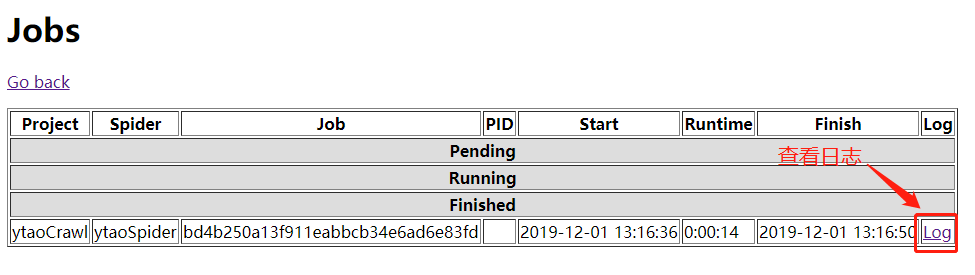
除了启动可远程调用外,同时 Scrapyd 还提供了较丰富的 API:
- 服务中爬虫状态查询
curl http://localhost:6800/daemonstatus.json - 取消爬虫
curl http://localhost:6800/cancel.json -d project=projectName -d job=jobId - 展示项目
curl http://localhost:6800/listprojects.json - 删除项目
curl http://localhost:6800/delproject.json -d project=projectName - 展示爬虫
curl http://localhost:6800/listspiders.json?project=projectName - 获取项目所有版本号
curl http://localhost:6800/listversions.json?project=projectName - 删除项目版本号
curl http://localhost:6800/delversion.json -d project=projectName -d version=versionName
更多详情 https://scrapyd.readthedocs.io/en/stable/api.html
总结
本文篇幅有限,剖析过程中不能面面俱到,有些网站的反爬比较棘手的,只要我们一一分析,都能找到破解的办法,还有眼睛看到的数据并不一定是你拿到的数据,比如有些网站的html渲染都是动态的,就需要我们去处理好这些信息。当你走进crawler的世界,你就会发现,其实挺有意思的。最后,希望大家不要面向监狱爬虫,数据千万条,遵纪守法第一条。
Scrapy爬虫及案例剖析的更多相关文章
- scrapy爬虫简单案例(简单易懂 适合新手)
爬取所有的电影名字,类型,时间等信息 1.准备工作 爬取的网页 https://www.ddoutv.com/f/27-1.html 创建项目 win + R 打开cmd输入 scrapy start ...
- 爬虫系列2:scrapy项目入门案例分析
本文从一个基础案例入手,较为详细的分析了scrapy项目的建设过程(在官方文档的基础上做了调整).主要内容如下: 0.准备工作 1.scrapy项目结构 2.编写spider 3.编写item.py ...
- Python爬虫——Scrapy整合Selenium案例分析(BOSS直聘)
概述 本文主要介绍scrapy架构图.组建.工作流程,以及结合selenium boss直聘爬虫案例分析 架构图 组件 Scrapy 引擎(Engine) 引擎负责控制数据流在系统中所有组件中流动,并 ...
- scrapy爬虫具体案例步骤详细分析
scrapy爬虫具体案例详细分析 scrapy,它是一个整合了的爬虫框架, 有着非常健全的管理系统. 而且它也是分布式爬虫, 它的管理体系非常复杂. 但是特别高效.用途广泛,主要用于数据挖掘.检测以及 ...
- scrapy爬虫具体案例详细分析
scrapy爬虫具体案例详细分析 scrapy,它是一个整合了的爬虫框架, 有着非常健全的管理系统. 而且它也是分布式爬虫, 它的管理体系非常复杂. 但是特别高效.用途广泛,主要用于数据挖掘.检测以及 ...
- scrapy爬虫,cmd中执行日志中显示了爬取的内容,但是运行时隐藏日志后(运行命令后添加--nolog),就没有输出结果了
cmd下执行scrapy爬虫程序,不报错也没有输出,解决方案 想要执行parse能够在cmd看到parse函数的执行结果: 解决方法: settings.py 中设置 ROBOTSTXT_OBEY ...
- scrapy爬虫结果插入mysql数据库
1.通过工具创建数据库scrapy
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- Linux搭建Scrapy爬虫集成开发环境
安装Python 下载地址:http://www.python.org/, Python 有 Python 2 和 Python 3 两个版本, 语法有些区别,ubuntu上自带了python2.7. ...
随机推荐
- 爬虫之scrapy简单案例之猫眼
在爬虫py文件下 class TopSpider(scrapy.Spider): name = 'top' allowed_domains = ['maoyan.com'] start_urls = ...
- TCP/IP协议第一卷第三章 IP首部分析
IP介绍 IP是TCP/IP协议族中最为核心的协议.所有的TCP.UDP.ICMP.IGMP数据都以IP数据报格式传输. IP提供不可靠.无连接的数据报传送服务. 不可靠(unreliable)它不能 ...
- scss新手使用指南
还在用死的css写样式吗?那可太麻烦了,各种长串选择器不说,还有各种继承权重有时候还有可能不生效 我的小程序项目也结束了,是时候总结一下scss语法了,毕竟用起来更加方便而且还能精简一点代码,好处多多 ...
- 使用vue-cookies操作cookie
1.前言 在vue中如果想要操作cookie,除了使用之前我们自己封装好的操作cookie的方法之外,我们还可以使用vue-cookies插件,这是一个简单的Vue.js插件,专门用于在vue中处理浏 ...
- [ZJOI2013]K大数查询——整体二分
题目描述 有N个位置,M个操作.操作有两种,每次操作如果是: 1 a b c:表示在第a个位置到第b个位置,每个位置加上一个数c 2 a b c:表示询问从第a个位置到第b个位置,第C大的数是多少. ...
- NOIP模拟14-16
最近事情有些多,先咕了! 鸽了,时间太久远了,写了话坑太大,太费时间了!
- Net Core Identity 身份验证:注册、登录和注销 (简单示例)
一.前言 一般我们自己的系统都会用自己设置的一套身份验证授权的代码,这次用net core的identity来完成简单的注册.登录和注销. 二.数据库 首先就是创建上下文,我这里简单的建了Users和 ...
- Vue 项目添加单元测试发现的问题及解决
用 Jest 测试单文件组件 1.安装 Jest 和 Vue Test Utils npm install --save-dev jest @vue/test-utils 2.配置 package.j ...
- layaair和egret的区别
egret缺点1 编译速度非常慢 2 就是强类型转换非常的麻烦 3 只能用ts 所以只能用他们的IDE 不能用sublime layaair唯一不足的就是 insepct太垃圾 占用游戏界面 所以建议 ...
- Spring源码解析之@Configuration
@Configuration简介 用于标识一个类为配置类,与xml配置效果类似 用法简介 public class TestApplication { public static void main( ...