统一批处理流处理——Flink批流一体实现原理

实现批处理的技术许许多多,从各种关系型数据库的sql处理,到大数据领域的MapReduce,Hive,Spark等等。这些都是处理有限数据流的经典方式。而Flink专注的是无限流处理,那么他是怎么做到批处理的呢?
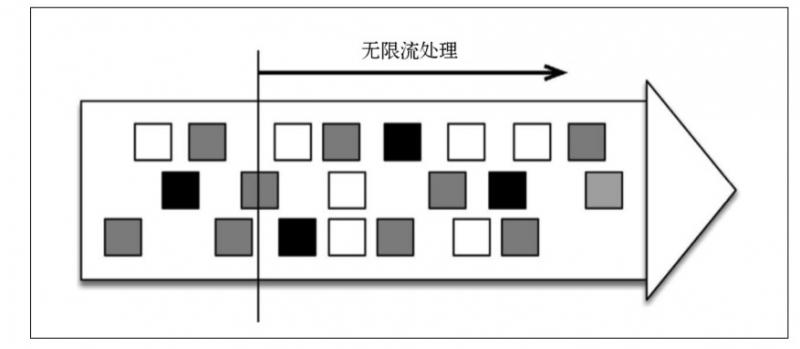
无限流处理:输入数据没有尽头;数据处理从当前或者过去的某一个时间 点开始,持续不停地进行
另一种处理形式叫作有限流处理,即从某一个时间点开始处理数据,然后在另一个时间点结束。输入数据可能本身是有限的(即输入数据集并不会随着时间增长),也可能出于分析的目的被人为地设定为有限集(即只分析某一个时间段内的事件)。
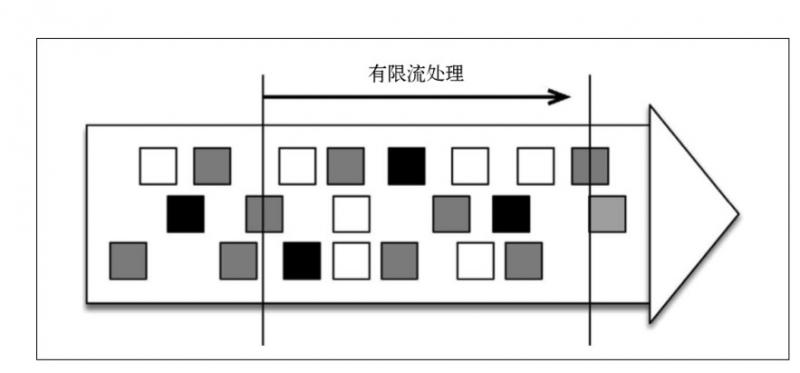
显然,有限流处理是无限流处理的一种特殊情况,它只不过在某个时间点停止而已。此外,如果计算结果不在执行过程中连续生成,而仅在末尾处生成一次,那就是批处理(分批处理数据)。
批处理是流处理的一种非常特殊的情况。在流处理中,我们为数据定义滑 动窗口或滚动窗口,并且在每次窗口滑动或滚动时生成结果。批处理则不同,我们定义一个全局窗口,所有的记录都属于同一个窗口。举例来说, 以下代码表示一个简单的Flink 程序,它负责每小时对某网站的访问者计数,并按照地区分组。
val counts = visits
.keyBy("region")
.timeWindow(Time.hours(1))
.sum("visits")
如果知道输入数据是有限的,则可以通过以下代码实现批处理。
val counts = visits
.keyBy("region")
.window(GlobalWindows.create)
.trigger(EndOfTimeTrigger.create)
.sum("visits")
Flink 的不寻常之处在于,它既可以将数据当作无限流来处理,也可以将它当作有限流来处理。Flink 的 DataSet API 就是专为批处理而生的,如下所示。
val counts = visits
.groupBy("region")
.sum("visits")
如果输入数据是有限的,那么以上代码的运行结果将与前一段代码的相同, 但是它对于习惯使用批处理器的程序员来说更友好。
Fink批处理模型
Flink 通过一个底层引擎同时支持流处理和批处理
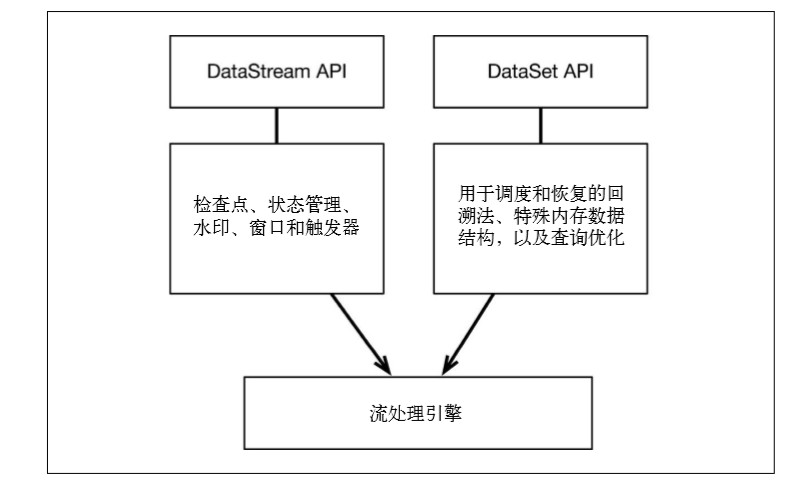
在流处理引擎之上,Flink 有以下机制:
检查点机制和状态机制:用于实现容错、有状态的处理;
水印机制:用于实现事件时钟;
窗口和触发器:用于限制计算范围,并定义呈现结果的时间。
在同一个流处理引擎之上,Flink 还存在另一套机制,用于实现高效的批处理。
- 用于调度和恢复的回溯法:由 Microsoft Dryad 引入,现在几乎用于所有批处理器;
- 用于散列和排序的特殊内存数据结构:可以在需要时,将一部分数据从内存溢出到硬盘上;
- 优化器:尽可能地缩短生成结果的时间。
两套机制分别对应各自的API(DataStream API 和 DataSet API);在创建 Flink 作业时,并不能通过将两者混合在一起来同时 利用 Flink 的所有功能。
在最新的版本中,Flink 支持两种关系型的 API,Table API 和 SQL。这两个 API 都是批处理和流处理统一的 API,这意味着在无边界的实时数据流和有边界的历史记录数据流上,关系型 API 会以相同的语义执行查询,并产生相同的结果。Table API 和 SQL 借助了 Apache Calcite 来进行查询的解析,校验以及优化。它们可以与 DataStream 和 DataSet API 无缝集成,并支持用户自定义的标量函数,聚合函数以及表值函数。
Table API / SQL 正在以流批统一的方式成为分析型用例的主要 API。
DataStream API 是数据驱动应用程序和数据管道的主要API。
从长远来看,DataStream API应该通过有界数据流完全包含DataSet API。
Flink批处理性能
MapReduce、Tez、Spark 和 Flink 在执行纯批处理任务时的性能比较。测试的批处理任务是 TeraSort 和分布式散列连接。
第一个任务是 TeraSort,即测量为 1TB 数据排序所用的时间。
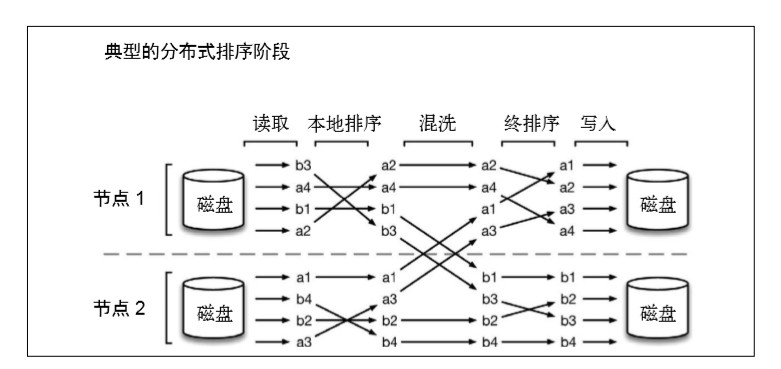
TeraSort 本质上是分布式排序问题,它由以下几个阶 段组成:
(1) 读取阶段:从 HDFS 文件中读取数据分区;
(2) 本地排序阶段:对上述分区进行部分排序;
(3) 混洗阶段:将数据按照 key 重新分布到处理节点上;
(4) 终排序阶段:生成排序输出;
(5) 写入阶段:将排序后的分区写入 HDFS 文件。
Hadoop 发行版包含对 TeraSort 的实现,同样的实现也可以用于 Tez,因为 Tez 可以执行通过MapReduce API 编写的程序。Spark 和 Flink 的 TeraSort 实现由 Dongwon Kim 提供.用来测量的集群由 42 台机器组成,每台机器 包含 12 个 CPU 内核、24GB 内存,以及 6 块硬盘。
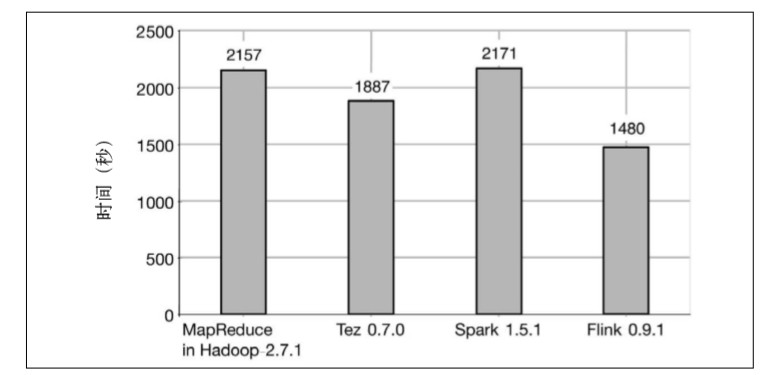
结果显示,Flink 的排序时间比其他所有系统都少。 MapReduce 用了2157 秒,Tez 用了1887 秒,Spark 用了2171 秒,Flink 则 只用了 1480 秒。
第二个任务是一个大数据集(240GB)和一个小数据集(256MB)之间的分布式散列连接。结果显示,Flink 仍然是速度最快的系统,它所用的时间分别是 Tez 和 Spark 的 1/2 和 1/4.
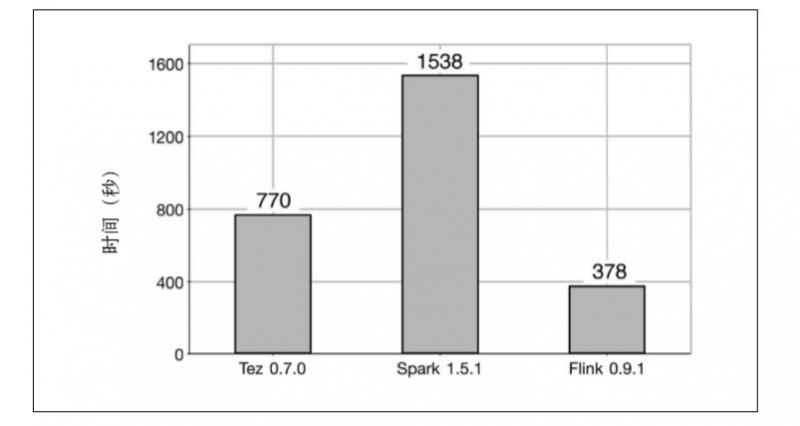
产生以上结果的总体原因是,Flink 的执行过程是基于流的,这意味着各个处理阶段有更多的重叠,并且混洗操作是流水线式的,因此磁盘访问操作更少。相反,MapReduce、Tez 和 Spark 是基于批的,这意味着数据在通过网络传输之前必须先被写入磁盘。该测试说明,在使用Flink 时,系统空闲时间和磁盘访问操作更少。
值得一提的是,性能测试结果中的原始数值可能会因集群设置、配置和软件版本而异。
因此,Flink 可以用同一个数据处理框架来处理无限数据流和有限数据流,并且不会牺牲性能。
更多Flink相关文章:
Flink,Storm,SparkStreaming性能对比
更多实时计算,Flink,Kafka的技术文章欢迎关注实时流式计算

统一批处理流处理——Flink批流一体实现原理的更多相关文章
- 《基于Apache Flink的流处理》读书笔记
前段时间详细地阅读了 <Apache Flink的流处理> 这本书,作者是 Fabian Hueske&Vasiliki Kalavri,国内崔星灿翻译的,这本书非常详细.全面得介 ...
- 阿里重磅开源全球首个批流一体机器学习平台Alink,Blink功能已全部贡献至Flink
11月28日,Flink Forward Asia 2019 在北京国家会议中心召开,阿里在会上发布Flink 1.10版本功能前瞻,同时宣布基于Flink的机器学习算法平台Alink正式开源,这也是 ...
- Flink 是如何统一批流引擎的
关注公众号:大数据技术派,回复"资料",领取1000G资料. 本文首发于我的个人博客:Flink 是如何统一批流引擎的 2015 年,Flink 的作者就写了 Apache Fli ...
- DataPipeline CTO陈肃:构建批流一体数据融合平台的一致性语义保证
文 | 陈肃 DataPipelineCTO 交流微信 | datapipeline2018 本文完整PPT获取 | 关注公众号后,后台回复“陈肃” 首先,本文将从数据融合角度,谈一下DataPipe ...
- 最佳实践:Pulsar 为批流处理提供融合存储
非常荣幸有机会和大家分享一下 Apache Pulsar 怎样为批流处理提供融合的存储.希望今天的分享对做大数据处理的同学能有帮助和启发. 这次分享,主要分为四个部分: 介绍与其他消息系统相比, Ap ...
- Apache 流框架 Flink,Spark Streaming,Storm对比分析(一)
本文由 网易云发布. 1.Flink架构及特性分析 Flink是个相当早的项目,开始于2008年,但只在最近才得到注意.Flink是原生的流处理系统,提供high level的API.Flink也提 ...
- Apache 流框架 Flink,Spark Streaming,Storm对比分析(二)
本文由 网易云发布. 本文内容接上一篇Apache 流框架 Flink,Spark Streaming,Storm对比分析(一) 2.Spark Streaming架构及特性分析 2.1 基本架构 ...
- Apache 流框架 Flink,Spark Streaming,Storm对比分析(1)
此文已由作者岳猛授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 1.Flink架构及特性分析 Flink是个相当早的项目,开始于2008年,但只在最近才得到注意.Flink是 ...
- Flink在流处理上常见的Source和sink操作
flink在流处理上的source和在批处理上的source基本一致.大致有4大类 1.基于本地集合的source(Collection-based-source) 2.基于文件的source(Fil ...
随机推荐
- Windows10下安装解压版MySQL教程
MySQL安装分为安装版和解压版,安装版主要是由一个exe程序式安装,有界面鼠标点击安装即可,小白建议使用安装版安装mysql,相比较与安装版,解压版安装更"纯净",没有多余的东西 ...
- html5+css+js简单了解
最近敲了敲HTML5的代码,感觉真的是很吸引人的东西,反正我是非常喜欢的,所以想写一点关于HTML的东xi首先呢我了解的不多,所以也是想写一点点我对它的认识.说起HTML5是打开Pycharm敲pyt ...
- 被公司的垃圾XG人事系统吓尿了
OA要尝试设置单点登录,拿现有的HR系统尝试,结果不知道HR系统的加密方式和验证地址,于是乎找HR厂商——厦门XG软件实施人员.结果那个技术人员支支吾吾不肯给我,搞得非常的烦. 真奇怪了,不开源的软件 ...
- Gradle task简单使用
还望支持个人博客站:http://www.enjoytoday.cn task是什么 task是gradle构建脚本的最小运行单元,我们通过在gradle脚本中创建task任务,以期完成某个特定的功能 ...
- 4.JavaCC处理中文字符
要使JavaCC能够处理中文首先需要将语法描述文件的options块的UNICODE_INPUT选项设置为true: options { STATIS = false; DEBUG_PARSER ...
- python 中文分词库 jieba库
jieba库概述: jieba是优秀的中文分词第三方库 中文文本需要通过分词获得单个的词语 jieba是优秀的中文分词第三方库,需要额外安装 jieba库分为精确模式.全模式.搜索引擎模式 原理 1. ...
- 编译安装 proxychains-ng proxychains4
下载 [root@localhost html]# git clone https://github.com/rofl0r/proxychains-ng.git 编译安装 [root@localhos ...
- 网络流(2)——用Ford-Fullkerson算法寻找最大流
寻找最大流 在大规模战争中,后勤补给是重中之重,为了尽最大可能满足前线的物资消耗,后勤部队必然要充分利用每条运输网,这正好可以用最大流模型解决.如何寻找一个复杂网络上的最大流呢? 直觉上的方案 一种直 ...
- fake_useragent.json
{ "browsers": { "chrome": [ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.3 ...
- 6.3 使用Spark SQL读写数据库
Spark SQL可以支持Parquet.JSON.Hive等数据源,并且可以通过JDBC连接外部数据源 一.通过JDBC连接数据库 1.准备工作 ubuntu安装mysql教程 在Linux中启动M ...