Storm 系列(二)—— Storm 核心概念详解
一、Storm核心概念
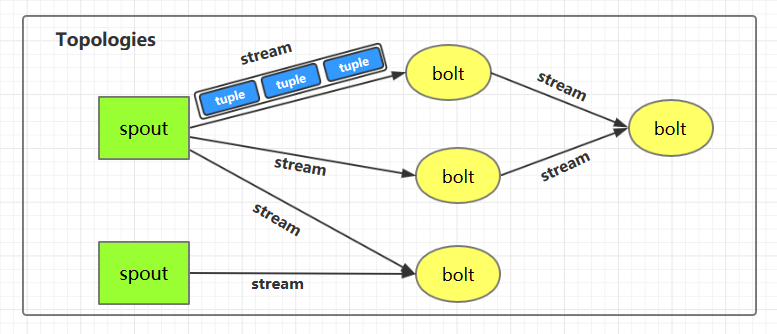
1.1 Topologies(拓扑)
一个完整的 Storm 流处理程序被称为 Storm topology(拓扑)。它是一个是由 Spouts 和 Bolts 通过 Stream 连接起来的有向无环图,Storm 会保持每个提交到集群的 topology 持续地运行,从而处理源源不断的数据流,直到你将主动其杀死 (kill) 为止。
1.2 Streams(流)
Stream 是 Storm 中的核心概念。一个 Stream 是一个无界的、以分布式方式并行创建和处理的 Tuple 序列。Tuple 可以包含大多数基本类型以及自定义类型的数据。简单来说,Tuple 就是流数据的实际载体,而 Stream 就是一系列 Tuple。
1.3 Spouts
Spouts 是流数据的源头,一个 Spout 可以向不止一个 Streams 中发送数据。Spout 通常分为可靠和不可靠两种:可靠的 Spout 能够在失败时重新发送 Tuple, 不可靠的 Spout 一旦把 Tuple 发送出去就置之不理了。
1.4 Bolts
Bolts 是流数据的处理单元,它可以从一个或者多个 Streams 中接收数据,处理完成后再发射到新的 Streams 中。Bolts 可以执行过滤 (filtering),聚合 (aggregations),连接 (joins) 等操作,并能与文件系统或数据库进行交互。
1.5 Stream groupings(分组策略)
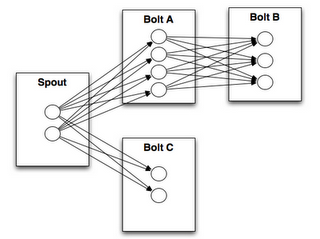
spouts 和 bolts 在集群上执行任务时,是由多个 Task 并行执行 (如上图,每一个圆圈代表一个 Task)。当一个 Tuple 需要从 Bolt A 发送给 Bolt B 执行的时候,程序如何知道应该发送给 Bolt B 的哪一个 Task 执行呢?
这是由 Stream groupings 分组策略来决定的,Storm 中一共有如下 8 个内置的 Stream Grouping。当然你也可以通过实现 CustomStreamGrouping 接口来实现自定义 Stream 分组策略。
Shuffle grouping
Tuples 随机的分发到每个 Bolt 的每个 Task 上,每个 Bolt 获取到等量的 Tuples。
Fields grouping
Streams 通过 grouping 指定的字段 (field) 来分组。假设通过
user-id字段进行分区,那么具有相同user-id的 Tuples 就会发送到同一个 Task。Partial Key grouping
Streams 通过 grouping 中指定的字段 (field) 来分组,与
Fields Grouping相似。但是对于两个下游的 Bolt 来说是负载均衡的,可以在输入数据不平均的情况下提供更好的优化。All grouping
Streams 会被所有的 Bolt 的 Tasks 进行复制。由于存在数据重复处理,所以需要谨慎使用。
Global grouping
整个 Streams 会进入 Bolt 的其中一个 Task,通常会进入 id 最小的 Task。
None grouping
当前 None grouping 和 Shuffle grouping 等价,都是进行随机分发。
Direct grouping
Direct grouping 只能被用于 direct streams 。使用这种方式需要由 Tuple 的生产者直接指定由哪个 Task 进行处理。
Local or shuffle grouping
如果目标 Bolt 有 Tasks 和当前 Bolt 的 Tasks 处在同一个 Worker 进程中,那么则优先将 Tuple Shuffled 到处于同一个进程的目标 Bolt 的 Tasks 上,这样可以最大限度地减少网络传输。否则,就和普通的
Shuffle Grouping行为一致。
二、Storm架构详解
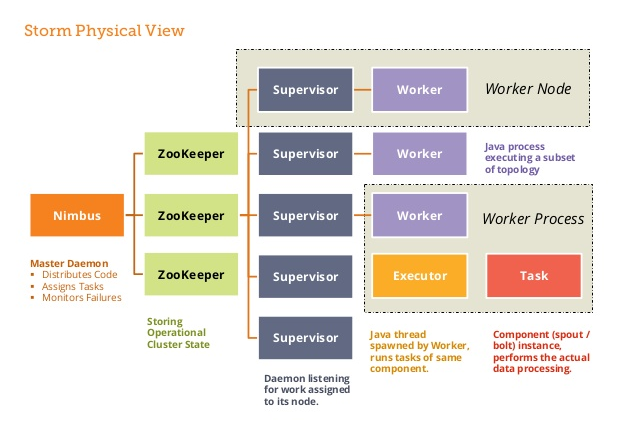
2.1 Nimbus进程
也叫做 Master Node,是 Storm 集群工作的全局指挥官。主要功能如下:
- 通过 Thrift 接口,监听并接收 Client 提交的 Topology;
- 根据集群 Workers 的资源情况,将 Client 提交的 Topology 进行任务分配,分配结果写入 Zookeeper;
- 通过 Thrift 接口,监听 Supervisor 的下载 Topology 代码的请求,并提供下载 ;
- 通过 Thrift 接口,监听 UI 对统计信息的读取,从 Zookeeper 上读取统计信息,返回给 UI;
- 若进程退出后,立即在本机重启,则不影响集群运行。
2.2 Supervisor进程
也叫做 Worker Node , 是 Storm 集群的资源管理者,按需启动 Worker 进程。主要功能如下:
- 定时从 Zookeeper 检查是否有新 Topology 代码未下载到本地 ,并定时删除旧 Topology 代码 ;
- 根据 Nimbus 的任务分配计划,在本机按需启动 1 个或多个 Worker 进程,并监控所有的 Worker 进程的情况;
- 若进程退出,立即在本机重启,则不影响集群运行。
2.3 zookeeper的作用
Nimbus 和 Supervisor 进程都被设计为快速失败(遇到任何意外情况时进程自毁)和无状态(所有状态保存在 Zookeeper 或磁盘上)。 这样设计的好处就是如果它们的进程被意外销毁,那么在重新启动后,就只需要从 Zookeeper 上获取之前的状态数据即可,并不会造成任何数据丢失。
2.4 Worker进程
Storm 集群的任务构造者 ,构造 Spoult 或 Bolt 的 Task 实例,启动 Executor 线程。主要功能如下:
- 根据 Zookeeper 上分配的 Task,在本进程中启动 1 个或多个 Executor 线程,将构造好的 Task 实例交给 Executor 去运行;
- 向 Zookeeper 写入心跳 ;
- 维持传输队列,发送 Tuple 到其他的 Worker ;
- 若进程退出,立即在本机重启,则不影响集群运行。
2.5 Executor线程
Storm 集群的任务执行者 ,循环执行 Task 代码。主要功能如下:
- 执行 1 个或多个 Task;
- 执行 Acker 机制,负责发送 Task 处理状态给对应 Spout 所在的 worker。
2.6 并行度

1 个 Worker 进程执行的是 1 个 Topology 的子集,不会出现 1 个 Worker 为多个 Topology 服务的情况,因此 1 个运行中的 Topology 就是由集群中多台物理机上的多个 Worker 进程组成的。1 个 Worker 进程会启动 1 个或多个 Executor 线程来执行 1 个 Topology 的 Component(组件,即 Spout 或 Bolt)。
Executor 是 1 个被 Worker 进程启动的单独线程。每个 Executor 会运行 1 个 Component 中的一个或者多个 Task。
Task 是组成 Component 的代码单元。Topology 启动后,1 个 Component 的 Task 数目是固定不变的,但该 Component 使用的 Executor 线程数可以动态调整(例如:1 个 Executor 线程可以执行该 Component 的 1 个或多个 Task 实例)。这意味着,对于 1 个 Component 来说,#threads<=#tasks(线程数小于等于 Task 数目)这样的情况是存在的。默认情况下 Task 的数目等于 Executor 线程数,即 1 个 Executor 线程只运行 1 个 Task。
总结如下:
- 一个运行中的 Topology 由集群中的多个 Worker 进程组成的;
- 在默认情况下,每个 Worker 进程默认启动一个 Executor 线程;
- 在默认情况下,每个 Executor 默认启动一个 Task 线程;
- Task 是组成 Component 的代码单元。
参考资料
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
Storm 系列(二)—— Storm 核心概念详解的更多相关文章
- Velocity魔法堂系列二:VTL语法详解
一.前言 Velocity作为历史悠久的模板引擎不单单可以替代JSP作为Java Web的服务端网页模板引擎,而且可以作为普通文本的模板引擎来增强服务端程序文本处理能力.而且Velocity被移植到不 ...
- Zookeeper系列二:分布式架构详解、分布式技术详解、分布式事务
一.分布式架构详解 1.分布式发展历程 1.1 单点集中式 特点:App.DB.FileServer都部署在一台机器上.并且访问请求量较少 1.2 应用服务和数据服务拆分 特点:App.DB.Fi ...
- Storm 学习之路(二)—— Storm核心概念详解
一.Storm核心概念 1.1 Topologies(拓扑) 一个完整的Storm流处理程序被称为Storm topology(拓扑).它是一个是由Spouts 和Bolts通过Stream连接起来的 ...
- ZooKeeper 系列(一)—— ZooKeeper核心概念详解
一.Zookeeper简介 二.Zookeeper设计目标 三.核心概念 3.1 集群角色 3.2 会话 3.3 数据节点 3.4 节点 ...
- Solr系列二:solr-部署详解(solr两种部署模式介绍、独立服务器模式详解、SolrCloud分布式集群模式详解)
一.solr两种部署模式介绍 Standalone Server 独立服务器模式:适用于数据规模不大的场景 SolrCloud 分布式集群模式:适用于数据规模大,高可靠.高可用.高并发的场景 二.独 ...
- Maven系列二setting.xml 配置详解
文件存放位置 全局配置: ${M2_HOME}/conf/settings.xml 用户配置: ${user.home}/.m2/settings.xml note:用户配置优先于全局配置.${use ...
- Maven 专题(六):Maven核心概念详解(二)
5 仓库 5.1 分类 [1]本地仓库:为当前本机电脑上的所有 Maven 工程服务.[2]远程仓库: (1)私服:架设在当前局域网环境下,为当前局域网范围内的所有 Maven 工程服务 ...
- Maven 专题(五):Maven核心概念详解(一)
**Maven 的核心程序中仅仅定义了抽象的生命周期,而具体的操作则是由 Maven 的插件来完成的.**可是 Maven 的插件并不包含在 Maven 的核心程序中,在首次使用时需要联网下载. 下载 ...
- Java 虚拟机系列二:垃圾收集机制详解,动图帮你理解
前言 上篇文章已经给大家介绍了 JVM 的架构和运行时数据区 (内存区域),本篇文章将给大家介绍 JVM 的重点内容--垃圾收集.众所周知,相比 C / C++ 等语言,Java 可以省去手动管理内存 ...
随机推荐
- @GetMapping、@PostMapping和@RequestMapping的区别
@GetMapping 用于将Http Get 请求映射到特定处理程序方法的注释.具体来说就是:@GetMapping是一个作为快捷方式的组合注释 @RequestMapping(method = R ...
- git pull 出现non-fast-forward的错误
1.git pull origin daily_liu_0909:liu_0909 出现non-fast-forward的错误,证明您的本地库跟远程库的提交记录不一致,即 你的本地库版本需要更新2.g ...
- java用最少循环求两个数组的交集、差集、并集
import java.util.ArrayList; import java.util.Arrays; import java.util.HashSet; import java.util.List ...
- Spring 整合 ibatis
是的,真的是那个不好用的ibatis,不是好用的mybatis. 由于工作需要用到ibatis需要自己搭建环境,遇到了不少的坑,做一下记录. 一.环境配置 Maven JDK1.6 (非常重要,使用S ...
- 并查集_HDU 1232_畅通工程
某省调查城镇交通状况,得到现有城镇道路统计表,表中列出了每条道路直接连通的城镇.省政府“畅通工程”的目标是使全省任何两个城镇间都可以实现交通(但不一定有直接的道路相连,只要互相间接通过道路可达即可). ...
- 第四次作业;创建raid5,源码编译安装;磁盘配额
创建raid5 格式化 ext4 创建物理卷: 创建卷组: 创建逻辑卷: 格式化 ext4 挂载 开机自启动 创建raid配置文件 源码编译安装: 创建本地yum仓库 umount /dev/sr0 ...
- 【Java例题】4.3 3. 使用Gauss消元法求解n元一次方程组的根,
3. 使用Gauss消元法求解n元一次方程组的根,举例,三元一次方程组:0.729x1+0.81x2+0.9x3=0.6867x1+x2+x3=0.83381.331x1+1.21x2+1.1x3=1 ...
- Selenium+java - 截图操作
写在前面 自动化测试过程中,运行失败截图可以很好的帮我们定位问题,因此,截图操作也是我们自动化测试中的一个重要环节. 截图方法 1.通过截图类TakeScreenshout实现截图 特点:截取浏览器窗 ...
- css实现左边高度自适应右边高度
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- python3 how to creat alphabet
Python: How To Generate a List Of Letters In The Alphabet Method 1# First we need to figure out the ...