Kibana笔记
• 根据id查询
GET index_1/doc/1
• 全文检索
GET index_1/doc/_search
GET index_1/doc/_search
{
"query": {
"match_all": {
}
}
}
• 模糊查询
GET index_1/doc/_search?q=hello
• 插入、修改
POST /index_1/doc/1
{
"test":"hello haha",
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
• 聚合查询
• 开启对分词字段的聚合
PUT index_1/_mapping/doc/
{
"properties": {
"字段名": {
"type": "text",
"fielddata": true
}
}
}
正排索引
使用id找内容
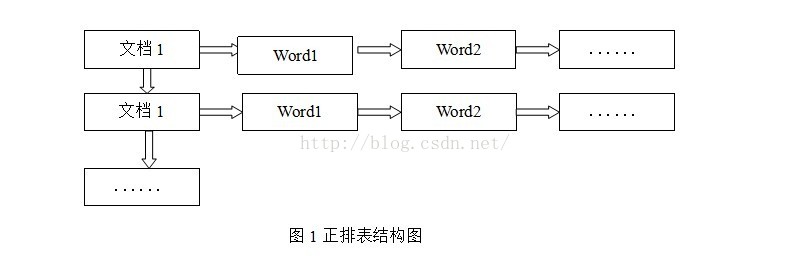
正排表是以文档的ID为关键字,表中记录文档中每个字的位置信息,查找时扫描表中每个文档中字的信息直到找出所有包含查询关键字的文档。
正排表结构如图1所示,这种组织方法在建立索引的时候结构比较简单,建立比较方便且易于维护;因为索引是基于文档建立的,若是有新的文档加入,直接为该文档建立一个新的索引块,挂接在原来索引文件的后面。若是有文档删除,则直接找到该文档号文档对应的索引信息,将其直接删除。但是在查询的时候需对所有的文档进行扫描以确保没有遗漏,这样就使得检索时间大大延长,检索效率低下。
尽管正排表的工作原理非常的简单,但是由于其检索效率太低,除非在特定情况下,否则实用性价值不大。
倒排索引
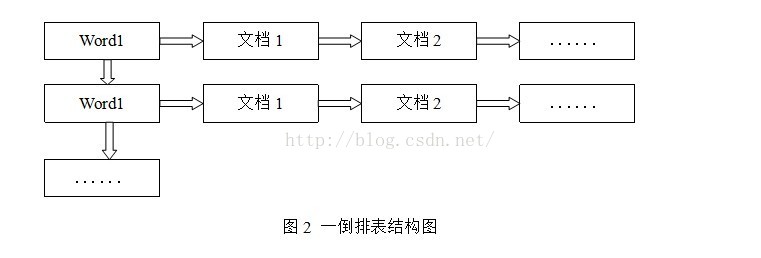
倒排表以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况。
由于每个字或词对应的文档数量在动态变化,所以倒排表的建立和维护都较为复杂,但是在查询的时候由于可以一次得到查询关键字所对应的所有文档,所以效率高于正排表。在全文检索中,检索的快速响应是一个最为关键的性能,而索引建立由于在后台进行,尽管效率相对低一些,但不会影响整个搜索引擎的效率。
倒排表的结构图如图2:
正排索引是从文档到关键字的映射(已知文档求关键字),倒排索引是从关键字到文档的映射(已知关键字求文档)。
Basics:
Stack:栈,先进后出
Queues:队列
Lists
Sorting排序:
Bubble Sort(冒泡排序)
Selection Sort(选择排序)
Insertion Sort(插入排序)
Merge Sort(归并排序)
Quick Sort(快排)
Kibana笔记的更多相关文章
- ELK学习笔记(一)安装Elasticsearch、Kibana、Logstash和X-Pack
最近在学习ELK的时候踩了不少的坑,特此写个笔记记录下学习过程. 日志主要包括系统日志.应用程序日志和安全日志.系统运维和开发人员可以通过日志了解服务器软硬件信息.检查配置过程中的错误及错误发生的原因 ...
- ELK学习笔记(二)-HelloWorld实例+Kibana介绍
这次我们通过一个最简单的HelloWolrd来了解一下ELK的使用. 进入logstash的config目录,创建stdin.conf 文件. input{ stdin{ } } output{ st ...
- ELK学习笔记之kibana关闭和进程查找
启动kibana : nohup ./kibana & 查看启动日志 : tail -f nohup kibana 使用 ps -ef|grep kibana 是查不到进程的,主要原因大概 ...
- Kibana学习笔记——安装和使用
1.首先下载Kibana https://www.elastic.co/downloads 2.解压 tar -zxvf kibana-6.2.1-linux-x86_64.tar.gz -C ~/s ...
- ElasticSearch + Logstash + Kibana 搭建笔记
ElasticSearch 安装 1.下载 ElasticSearch,本文使用的版本为 5.5.1. 2.配置 path.data: /data/es #数据路径 path.logs: /data/ ...
- ELK 学习笔记之 Kibana入门使用
Kibana入门使用: 第一次导入索引: 修改展示时间,不然查不到数据: 点Discover,查阅数据: 如果要添加新的index: 点击Visualize, 创建chart: 点击Dashboard ...
- ELK 学习笔记之 Kibana安装
Kibana安装: 安装地址: https://www.elastic.co/downloads/kibana 安装: tar -zxvf kibana-5.6.1-linux-x86_64.tar. ...
- kibana的query string syntax 笔记
kibana的query string syntax 并不是 Query String Query,只能说类似.kibana的 Lucene query string syntax(es的query ...
- ELK学习笔记之Elasticsearch和Kibana数据导出实战
0x00 问题引出 以下两个导出问题来自Elastic中文社区. 问题1.kibana怎么导出查询数据?问题2:elasticsearch数据导出就像数据库数据导出一样,elasticsearch可以 ...
随机推荐
- Swift3 Xcode8 Ios10 开发笔记
设置不同subView的层次: //将subView挪到最上边 self.view.bringSubviewToFront(subView) //将subView挪到最下边 self.view.sen ...
- 微信授权就是这个原理,Spring Cloud OAuth2 授权码模式
上一篇文章Spring Cloud OAuth2 实现单点登录介绍了使用 password 模式进行身份认证和单点登录.本篇介绍 Spring Cloud OAuth2 的另外一种授权模式-授权码模式 ...
- VS环境下基于C++的单链表实现
------------恢复内容开始------------ #include<iostream> using namespace::std; typedef int ElemType; ...
- 爬虫之CrawlSpider简单案例之读书网
项目名py文件下 class DsSpider(CrawlSpider): name = 'ds' allowed_domains = ['dushu.com'] start_urls = ['htt ...
- TCP/IP协议第一卷第二章
环回接口: 127全网段均被作为环回地址. 传给广播地址或多播地址的数据报复制一份给环回接口,然后传送到以太网上.这是因为广播传送和多播传送的定义包含自己本身. 任何传给该主机IP地址的数据均送到环回 ...
- [考试反思]1024csp-s模拟测试86:消耗
%%%两个没素质的和一个萌两小时AK 最近貌似总是可以比较快速的拿下T1,然后T2打到考试结束... T1是套路题没什么好说的. T2是一个比较蠢的博弈题,我花了很长时间干各种乱七八糟的事 什么打表啊 ...
- 关于GC(上):Apache的POI组件导致线上频繁FullGC问题排查及处理全过程
某线上应用在进行查询结果导出Excel时,大概率出现持续的FullGC.解决这个问题时,记录了一下整个的流程,也可以作为一般性的FullGC问题排查指导. 1. 生成dump文件 为了定位FullGC ...
- rpm 方式安装java
1.rpm下载地址 http://www.oracle.com/technetwork/java/javase/downloads/index.html 2.如果有安装openjdk 则卸载 #### ...
- 用Vsftpd服务传输文件(铺垫篇)
文件传输协议 文件传输协议(FTP,File Transfer Protocol),即能够让用户在互联网中上传.下载文件的文件协议,而FTP服务器就是支持FTP传输协议的主机,要想完成文件传输则需要F ...
- 1114作业 html
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...