cs231n---强化学习
介绍了基于价值函数和基于策略梯度的两种强化学习框架,并介绍了四种强化学习算法:Q-learning,DQN,REINFORCE,Actot-Critic
1 强化学习问题建模
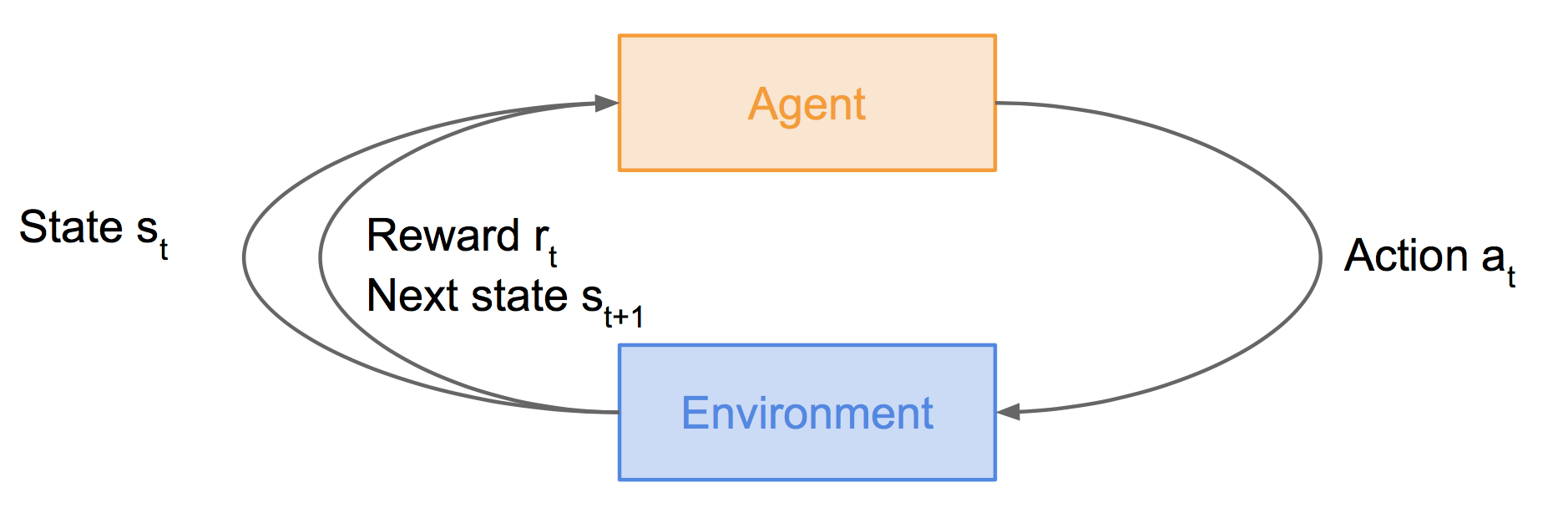
上图中,智能体agent处于状态st下,执行动作at后,会由于周围环境的作用进入下一个状态st+1,同时获得奖励rt。
马尔可夫决策过程MDP建模了上图过程:

我们定义策略Pi为一个从状态s到动作a的函数,表示在状态s下采取什么样的动作a。
而我们的目标是,找到一个最好的策略pi,使得整个过程中累计的奖励值最大:

比较正式的表达是:
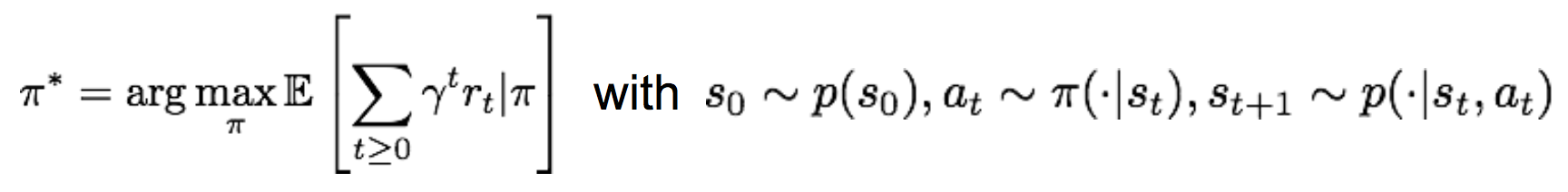
2 Q-learning算法
(1)价值函数与Q-价值函数
对于一个给定的策略pi,只要我们给定初始状态s0,就能产生序列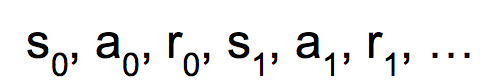
那么,只要给定一个策略pi,就能计算出在状态s下所产生的累积奖励的期望,也就是价值函数:
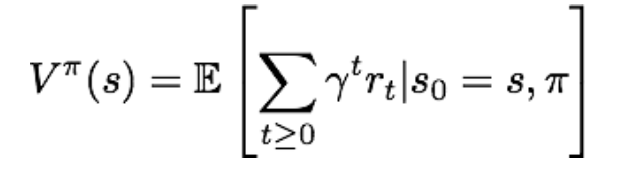
注意,价值函数评价了给定策略pi下状态s的价值,由策略pi和当前状态s所唯一确定。
类似的,Q-价值函数则评价了给定策略pi下,在状态s下采取动作a后,所能带来的累积奖励期望:
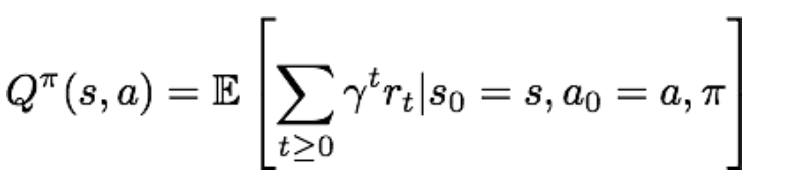
Q-价值函数由策略pi和当前状态s和当前动作a所唯一确定。
(2)贝尔曼方程
现在我们固定当前状态s和当前动作a,那么目标就是要选择最优策略pi,使得Q-value函数最大,这个最优的Q-value函数被记为Q*:
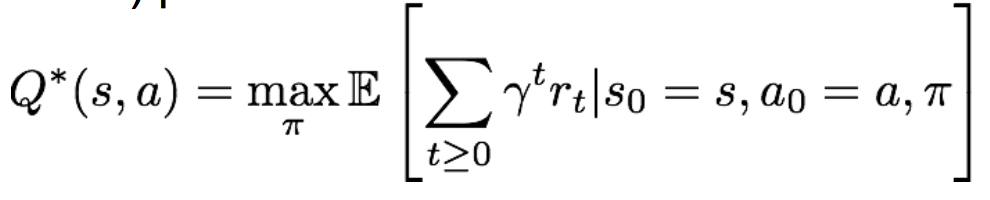
理解一下Q*,也就是在当前状态s下采取动作a后,所能达到的最大累积奖励期望。显然Q*仅与s和a有关。
而强化学习方法Q-learning的核心公式——贝尔曼方程,则给出了Q*的另一种表达形式:
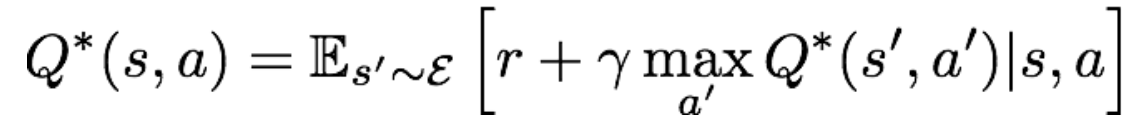
对公式的理解为:当我们在状态s下采取动作a后,环境会反馈给我们一个奖励r,以及下一时刻的状态s'。记下一时刻的动作为a',这样我们就能递归地使用Q*函数。
(3)Q-learning
现在让我们来看一种经典的强化学习算法,Q-learning。
Q-learning中,我们需要一张称为Q-table的查找表,该表第i行第j列的元素表示Q*(si, aj)的值。
然而我们并不知道Q*的具体形式以及值,我们只能一开始使用全0初始化Q-table,然后进行游戏,每执行一个动作后,使用贝尔曼方程去更新Q-table的值,理论研究表明当迭代次数足够多后,Q-table的值将会收敛为真实的Q*值。这也被称为值迭代算法:
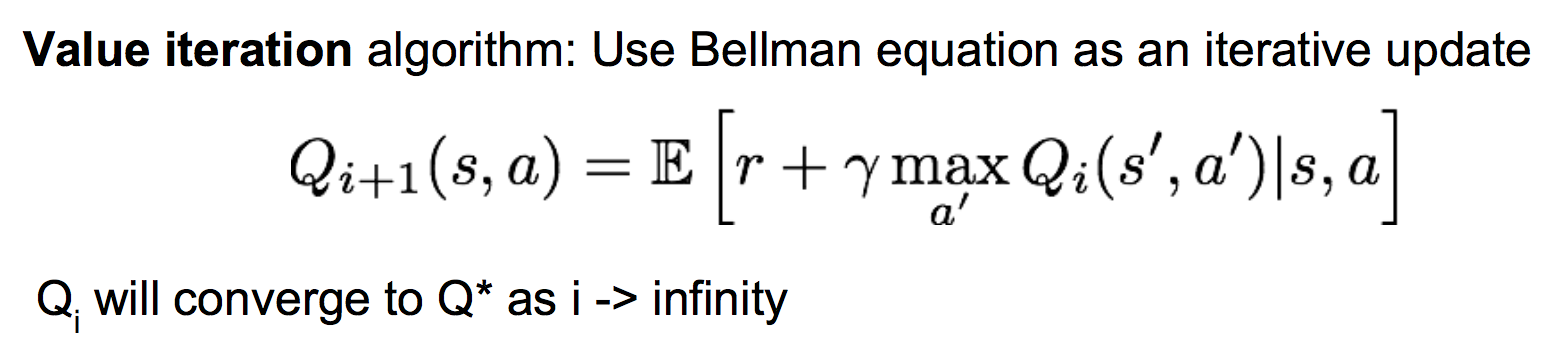
Qi和Qi+1分别表示更新前和更新后的Q-table。
Q-learning的完整算法过程为:

3 深度强化学习----Deep Q-learning
传统的Q-learning算法当遇到状态空间很大时(例如状态是一个游戏画面的所有像素),我们不可能用表Q-table来枚举出所有的状态及其对应的动作a的所有q值。而Q*这个函数是我们最终要学习的,并且它很复杂。很自然地,我们想到用一个神经网络来表示Q*,并且在游戏中去不断的学习它!
前向传播和反向传播表示为:
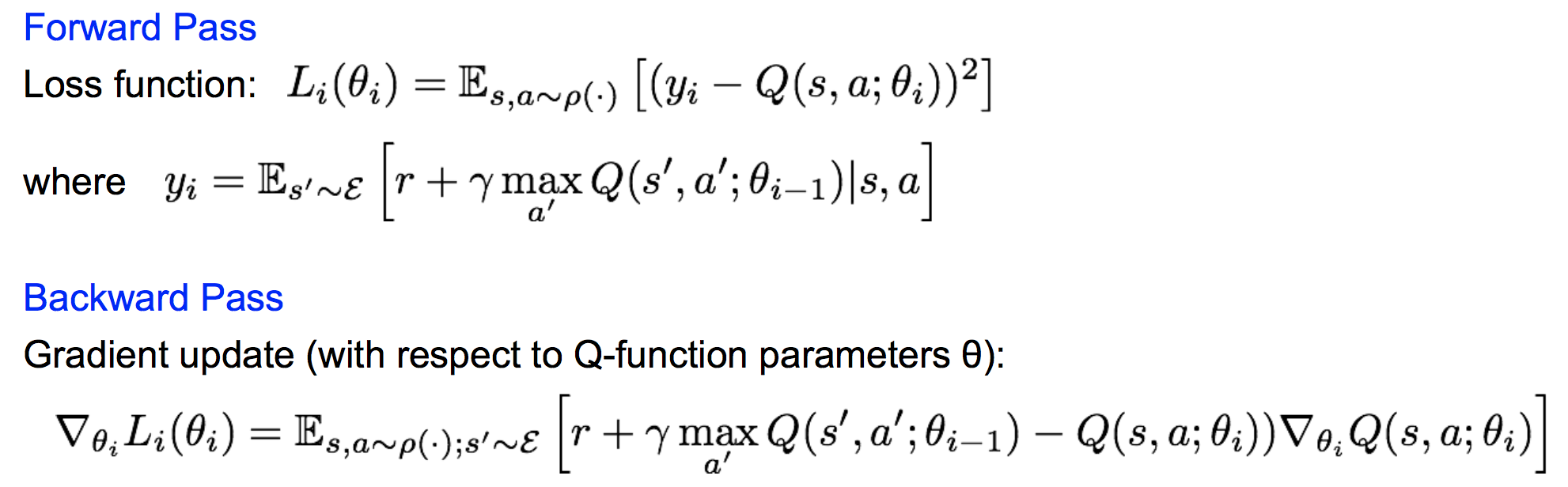
直接这样还不能有效的学习。原因有两点:

因此我们使用一个叫做Experience Replay的机制,每次将生成的(st, at, rt, st+1)元组放入一个表中,然后每次训练Q网络时,从该表中随机取一批mini batch进行训练。
完整的Deep Q-learning算法为:

注意这里我们每次有一定概率去随机的行动,这样做的目的是探索更大的状态空间。
4 策略梯度
(1)引入策略梯度
为什么要用策略梯度:基于价值函数的方法,当状态空间很大时,价值函数会很复杂以至于难以学习。而策略函数(已知当前状态下各个动作的条件概率分布)则会比较简单。因此我们这里会去学习一个策略网络,而不是价值网络。
策略网络的定义如下:
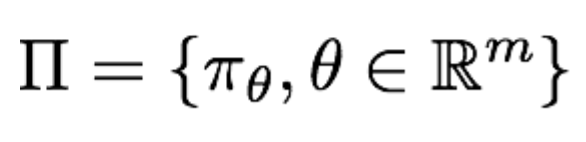
表示策略网络的参数为θ,所有参数的可能取值构成了所有可能的策略。
对一个给定的策略,其价值定义为:
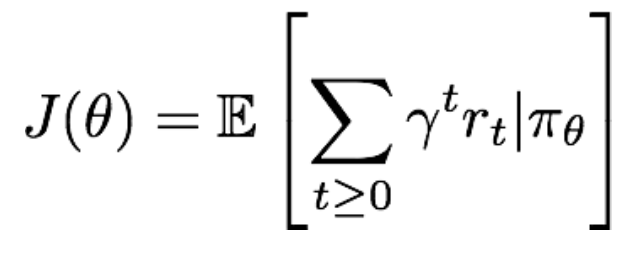
那么,我们要找到最优的参数θ,使得上面的J(θ)最大。即: 。显然要使用gradient ascent的方法,那么如何来计算策略参数的梯度呢?
。显然要使用gradient ascent的方法,那么如何来计算策略参数的梯度呢?
(2)REINFORCE 计算策略梯度
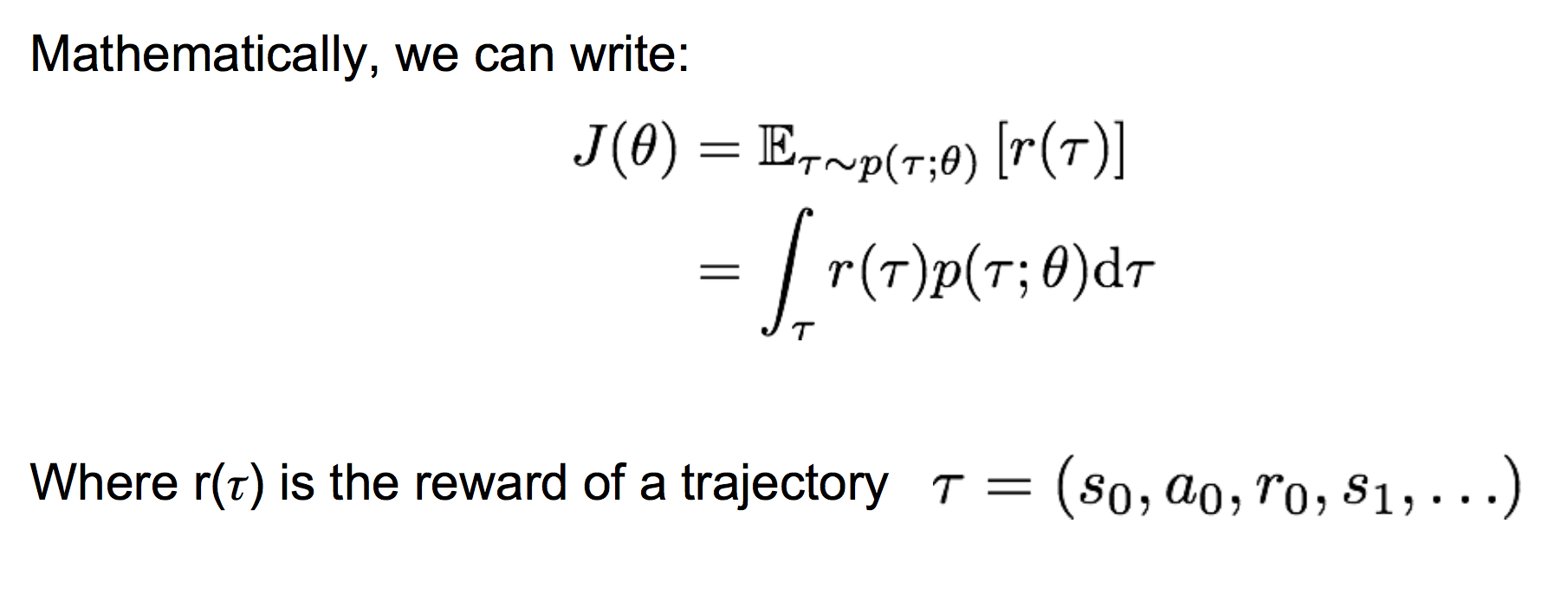
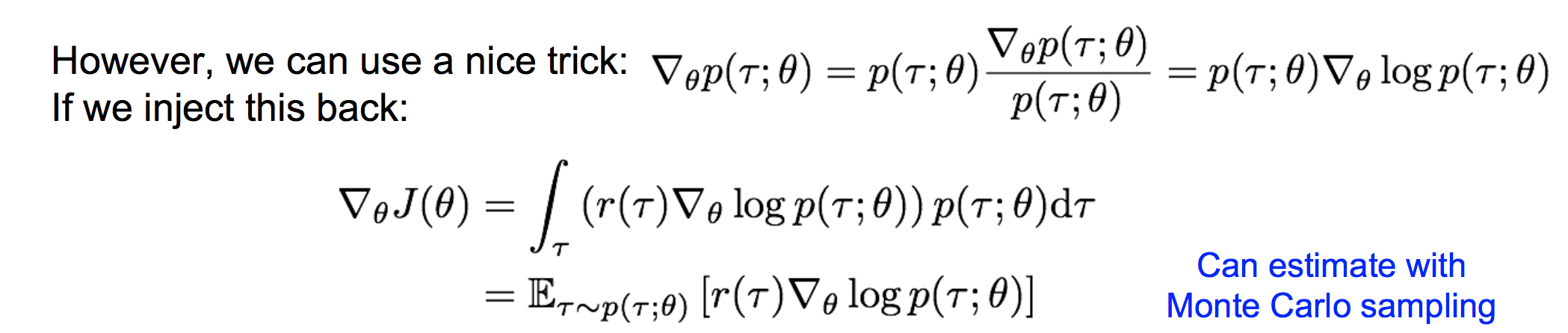

这样,我们就可以采样出若干个轨迹τ,来估计策略梯度。注意这里的估计是一个无偏估计。
(3)直观上理解策略梯度的表达式

注意看,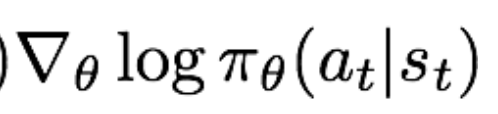 这一项表示当前的梯度方向是使得各个时间步的动作出现似然增大的梯度方向,前面再加一个权重r(τ)。则当r(τ)高时,对应于该轨迹的各个动作似然要相对增大,当r(τ)低时,对应于该轨迹的各个动作似然要相对减小。很符合我们的直观感受。
这一项表示当前的梯度方向是使得各个时间步的动作出现似然增大的梯度方向,前面再加一个权重r(τ)。则当r(τ)高时,对应于该轨迹的各个动作似然要相对增大,当r(τ)低时,对应于该轨迹的各个动作似然要相对减小。很符合我们的直观感受。
cs231n---强化学习的更多相关文章
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
- 深度强化学习资料(视频+PPT+PDF下载)
https://blog.csdn.net/Mbx8X9u/article/details/80780459 课程主页:http://rll.berkeley.edu/deeprlcourse/ 所有 ...
- 【整理】强化学习与MDP
[入门,来自wiki] 强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益.其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的 ...
- 强化学习之 免模型学习(model-free based learning)
强化学习之 免模型学习(model-free based learning) ------ 蒙特卡罗强化学习 与 时序查分学习 ------ 部分节选自周志华老师的教材<机器学习> 由于现 ...
- (译) 强化学习 第一部分:Q-Learning 以及相关探索
(译) 强化学习 第一部分:Q-Learning 以及相关探索 Q-Learning review: Q-Learning 的基础要点是:有一个关于环境状态S的表达式,这些状态中可能的动作 a,然后你 ...
- 强化学习读书笔记 - 02 - 多臂老O虎O机问题
# 强化学习读书笔记 - 02 - 多臂老O虎O机问题 学习笔记: [Reinforcement Learning: An Introduction, Richard S. Sutton and An ...
- 强化学习读书笔记 - 05 - 蒙特卡洛方法(Monte Carlo Methods)
强化学习读书笔记 - 05 - 蒙特卡洛方法(Monte Carlo Methods) 学习笔记: Reinforcement Learning: An Introduction, Richard S ...
- 强化学习读书笔记 - 06~07 - 时序差分学习(Temporal-Difference Learning)
强化学习读书笔记 - 06~07 - 时序差分学习(Temporal-Difference Learning) 学习笔记: Reinforcement Learning: An Introductio ...
- 强化学习之Q-learning ^_^
许久没有更新重新拾起,献于小白 这次介绍的是强化学习 Q-learning,Q-learning也是离线学习的一种 关于Q-learning的算法详情看 传送门 下文中我们会用openai gym来做 ...
- 强化学习 - Q-learning Sarsa 和 DQN 的理解
本文用于基本入门理解. 强化学习的基本理论 : R, S, A 这些就不说了. 先设想两个场景: 一. 1个 5x5 的 格子图, 里面有一个目标点, 2个死亡点二. 一个迷宫, 一个出发点, ...
随机推荐
- Java项目案例之--封装的实例
Java项目案例之---封装的实例 有一个专业类,有一个专业对象,专业名称:计算机科学与技术,专业编号:J001,专业年限:4,对年限添加约束,如果输入小于0,则默认为0,否则显示输入的值 有一个学生 ...
- 基于lua-nginx-module(openresty)的WEB应用防火墙
独乐乐,不如众乐乐,分享给大家一篇WEB应用防火墙的文章,基于Lua+ Nginx实现.以下是ngx_lua_waf的作者全文输出. Github地址:https://github.com/loves ...
- 修改Windows10的host文件。
一.Windows10中host地址. c:\windows\system32\drivers\etc\hosts 其他系统中的位置. Windows操作系统(Windows XP/7/8/10): ...
- nu.xom:Attribute
Attribute: 机翻 Attribute copy():生成一份当前Attribute的拷贝,但是它没有依附任何Element Node getChild(int position) :因为At ...
- 个人永久性免费-Excel催化剂功能第96波-地图数据挖宝之全国天气查询(区域最细可到区县,最长预报4天)
天气预报的信息,是很普通的大家习以为常的信息,但如果不进行采集,在日常数据分析过程中,就少了非常重要的一个分析维度,如果人手采集整理,工作量巨大.此篇给广大数据分析工作者再次减负,只需简单一键,即可批 ...
- 《C# 语言学习笔记》——委托
委托是一种可以把引用存储为函数的类型. 委托的声明非常类似于函数,但不带函数体,且要使用delegate关键字.委托的声明制定了一个返回类型和一个参数列表. 在定义了委托后,就可以声明该委托类型的变量 ...
- C++里long的字节数
标准规定long的大小不小于int也就是说sizeof(long)>=sizeof(int). Numerical type sizes in C (bits) Platforms \ T ...
- Java、Java SE、Java Web和Java EE的区别
刚接触Java对这些概念上的东西有点模糊,查了很多资料,想把它分享出来,要是哪里不对请大家指正(^_^) 1.Java 毫无疑问这就是门语言和C.C++.C#一样没什么好说的. 2.Java SE和J ...
- 小白学python-day06-
今天是day06,以下是学习内容总结: 但行努力,莫问前程. --------------------------------------------------------------------- ...
- ThinkPHP5.0 模板
ThinkPHP5.0 模板 模板渲染 默认的视图目录是默认的模块下的view目录 渲染规则:调用 \think\View 类fetch方法 // [模板文件目录]/当前控制器名(小写+下划线)/当前 ...