cs231n---强化学习
介绍了基于价值函数和基于策略梯度的两种强化学习框架,并介绍了四种强化学习算法:Q-learning,DQN,REINFORCE,Actot-Critic
1 强化学习问题建模
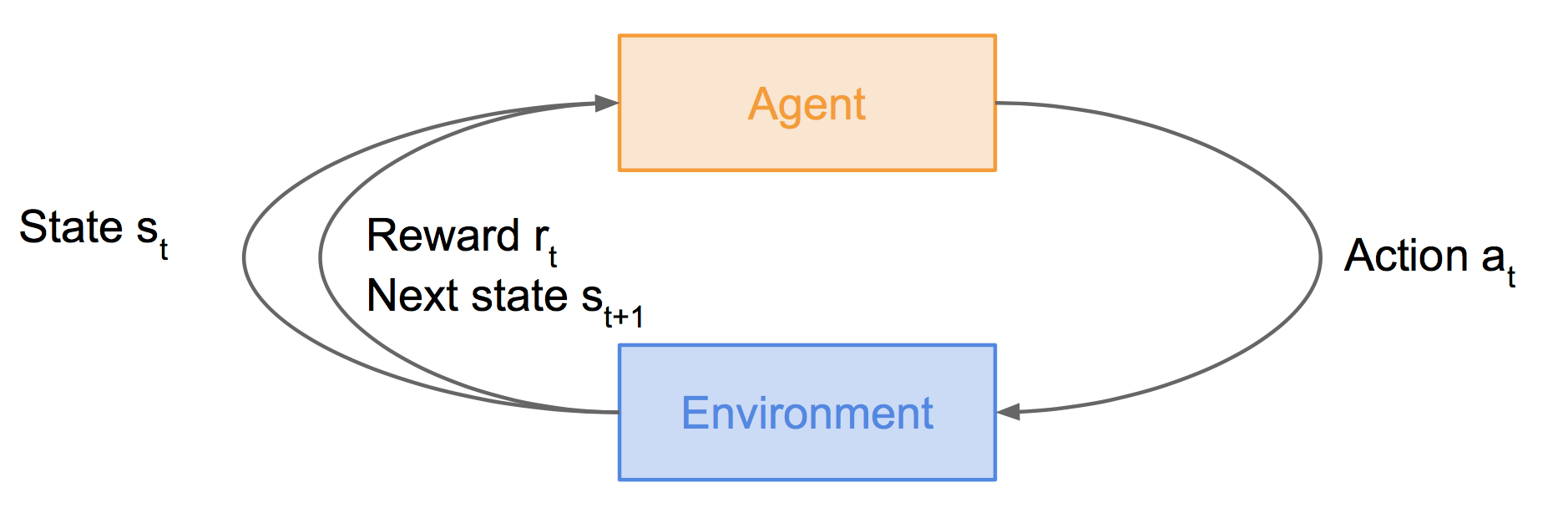
上图中,智能体agent处于状态st下,执行动作at后,会由于周围环境的作用进入下一个状态st+1,同时获得奖励rt。
马尔可夫决策过程MDP建模了上图过程:

我们定义策略Pi为一个从状态s到动作a的函数,表示在状态s下采取什么样的动作a。
而我们的目标是,找到一个最好的策略pi,使得整个过程中累计的奖励值最大:

比较正式的表达是:
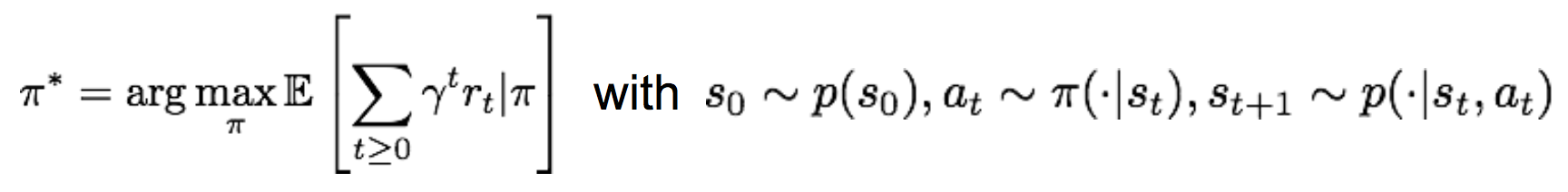
2 Q-learning算法
(1)价值函数与Q-价值函数
对于一个给定的策略pi,只要我们给定初始状态s0,就能产生序列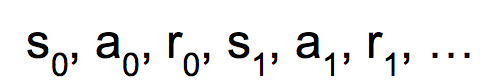
那么,只要给定一个策略pi,就能计算出在状态s下所产生的累积奖励的期望,也就是价值函数:
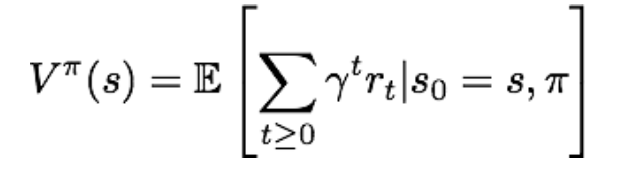
注意,价值函数评价了给定策略pi下状态s的价值,由策略pi和当前状态s所唯一确定。
类似的,Q-价值函数则评价了给定策略pi下,在状态s下采取动作a后,所能带来的累积奖励期望:
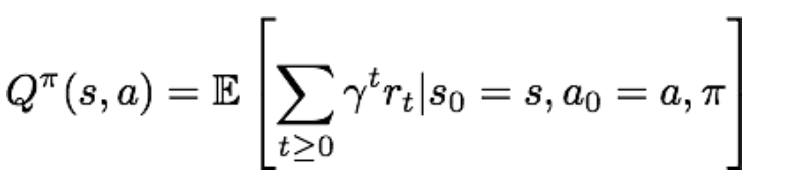
Q-价值函数由策略pi和当前状态s和当前动作a所唯一确定。
(2)贝尔曼方程
现在我们固定当前状态s和当前动作a,那么目标就是要选择最优策略pi,使得Q-value函数最大,这个最优的Q-value函数被记为Q*:
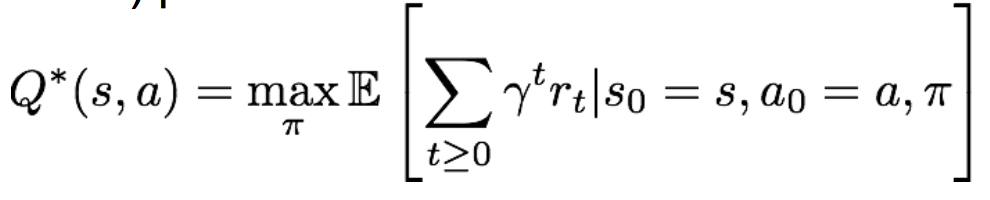
理解一下Q*,也就是在当前状态s下采取动作a后,所能达到的最大累积奖励期望。显然Q*仅与s和a有关。
而强化学习方法Q-learning的核心公式——贝尔曼方程,则给出了Q*的另一种表达形式:
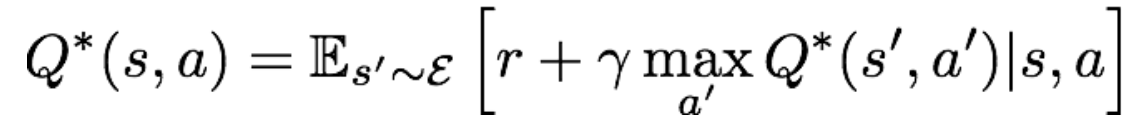
对公式的理解为:当我们在状态s下采取动作a后,环境会反馈给我们一个奖励r,以及下一时刻的状态s'。记下一时刻的动作为a',这样我们就能递归地使用Q*函数。
(3)Q-learning
现在让我们来看一种经典的强化学习算法,Q-learning。
Q-learning中,我们需要一张称为Q-table的查找表,该表第i行第j列的元素表示Q*(si, aj)的值。
然而我们并不知道Q*的具体形式以及值,我们只能一开始使用全0初始化Q-table,然后进行游戏,每执行一个动作后,使用贝尔曼方程去更新Q-table的值,理论研究表明当迭代次数足够多后,Q-table的值将会收敛为真实的Q*值。这也被称为值迭代算法:
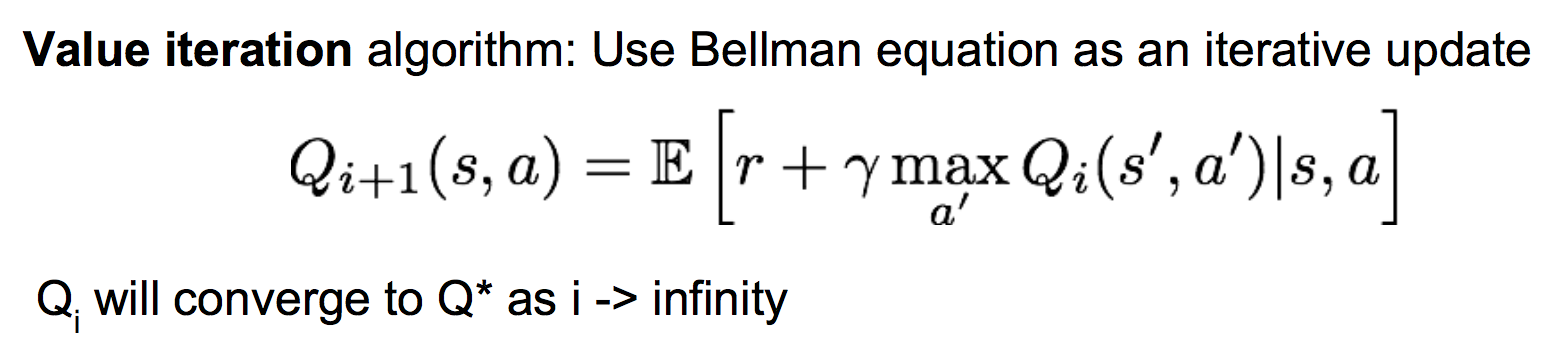
Qi和Qi+1分别表示更新前和更新后的Q-table。
Q-learning的完整算法过程为:

3 深度强化学习----Deep Q-learning
传统的Q-learning算法当遇到状态空间很大时(例如状态是一个游戏画面的所有像素),我们不可能用表Q-table来枚举出所有的状态及其对应的动作a的所有q值。而Q*这个函数是我们最终要学习的,并且它很复杂。很自然地,我们想到用一个神经网络来表示Q*,并且在游戏中去不断的学习它!
前向传播和反向传播表示为:
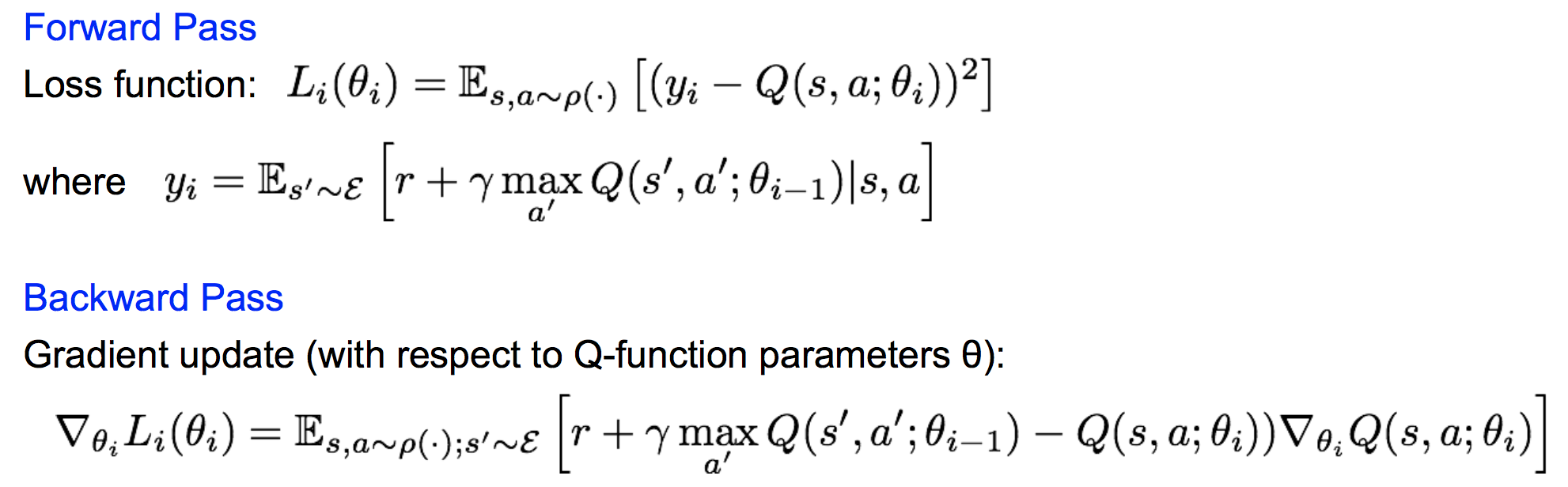
直接这样还不能有效的学习。原因有两点:

因此我们使用一个叫做Experience Replay的机制,每次将生成的(st, at, rt, st+1)元组放入一个表中,然后每次训练Q网络时,从该表中随机取一批mini batch进行训练。
完整的Deep Q-learning算法为:

注意这里我们每次有一定概率去随机的行动,这样做的目的是探索更大的状态空间。
4 策略梯度
(1)引入策略梯度
为什么要用策略梯度:基于价值函数的方法,当状态空间很大时,价值函数会很复杂以至于难以学习。而策略函数(已知当前状态下各个动作的条件概率分布)则会比较简单。因此我们这里会去学习一个策略网络,而不是价值网络。
策略网络的定义如下:
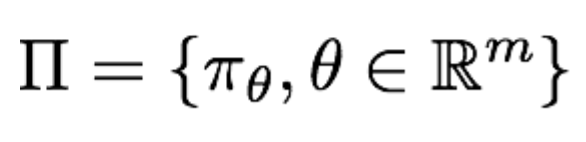
表示策略网络的参数为θ,所有参数的可能取值构成了所有可能的策略。
对一个给定的策略,其价值定义为:
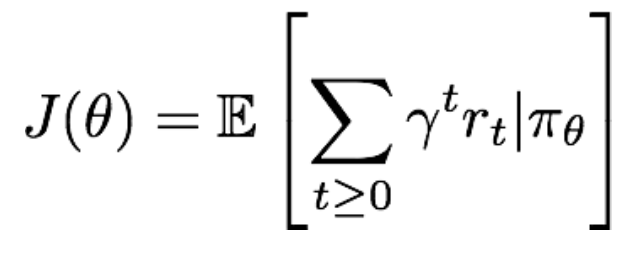
那么,我们要找到最优的参数θ,使得上面的J(θ)最大。即: 。显然要使用gradient ascent的方法,那么如何来计算策略参数的梯度呢?
。显然要使用gradient ascent的方法,那么如何来计算策略参数的梯度呢?
(2)REINFORCE 计算策略梯度
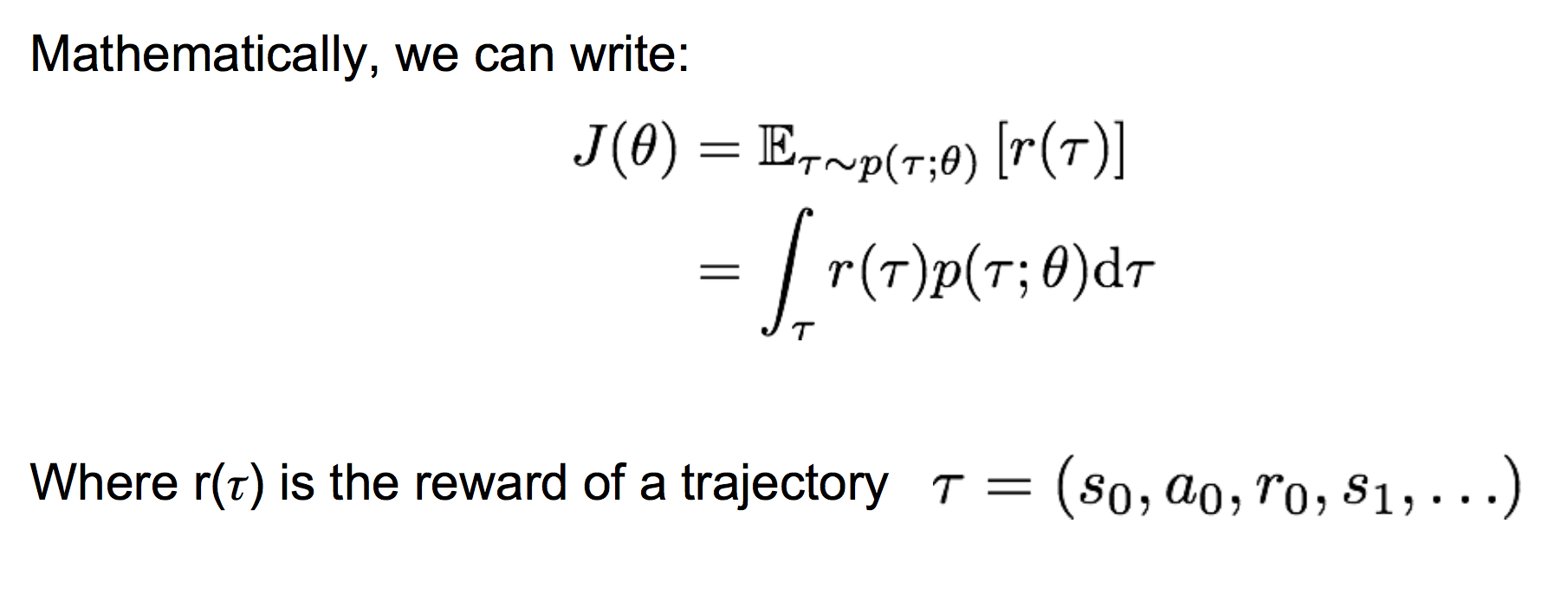
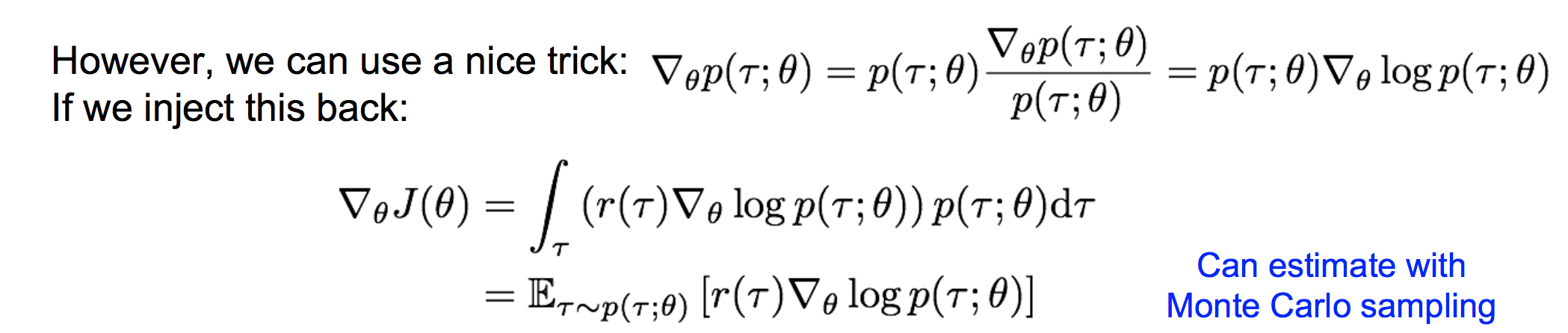

这样,我们就可以采样出若干个轨迹τ,来估计策略梯度。注意这里的估计是一个无偏估计。
(3)直观上理解策略梯度的表达式

注意看,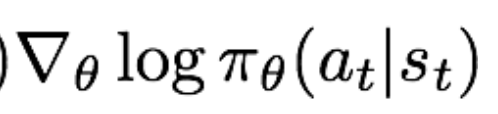 这一项表示当前的梯度方向是使得各个时间步的动作出现似然增大的梯度方向,前面再加一个权重r(τ)。则当r(τ)高时,对应于该轨迹的各个动作似然要相对增大,当r(τ)低时,对应于该轨迹的各个动作似然要相对减小。很符合我们的直观感受。
这一项表示当前的梯度方向是使得各个时间步的动作出现似然增大的梯度方向,前面再加一个权重r(τ)。则当r(τ)高时,对应于该轨迹的各个动作似然要相对增大,当r(τ)低时,对应于该轨迹的各个动作似然要相对减小。很符合我们的直观感受。
cs231n---强化学习的更多相关文章
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
- 深度强化学习资料(视频+PPT+PDF下载)
https://blog.csdn.net/Mbx8X9u/article/details/80780459 课程主页:http://rll.berkeley.edu/deeprlcourse/ 所有 ...
- 【整理】强化学习与MDP
[入门,来自wiki] 强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益.其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的 ...
- 强化学习之 免模型学习(model-free based learning)
强化学习之 免模型学习(model-free based learning) ------ 蒙特卡罗强化学习 与 时序查分学习 ------ 部分节选自周志华老师的教材<机器学习> 由于现 ...
- (译) 强化学习 第一部分:Q-Learning 以及相关探索
(译) 强化学习 第一部分:Q-Learning 以及相关探索 Q-Learning review: Q-Learning 的基础要点是:有一个关于环境状态S的表达式,这些状态中可能的动作 a,然后你 ...
- 强化学习读书笔记 - 02 - 多臂老O虎O机问题
# 强化学习读书笔记 - 02 - 多臂老O虎O机问题 学习笔记: [Reinforcement Learning: An Introduction, Richard S. Sutton and An ...
- 强化学习读书笔记 - 05 - 蒙特卡洛方法(Monte Carlo Methods)
强化学习读书笔记 - 05 - 蒙特卡洛方法(Monte Carlo Methods) 学习笔记: Reinforcement Learning: An Introduction, Richard S ...
- 强化学习读书笔记 - 06~07 - 时序差分学习(Temporal-Difference Learning)
强化学习读书笔记 - 06~07 - 时序差分学习(Temporal-Difference Learning) 学习笔记: Reinforcement Learning: An Introductio ...
- 强化学习之Q-learning ^_^
许久没有更新重新拾起,献于小白 这次介绍的是强化学习 Q-learning,Q-learning也是离线学习的一种 关于Q-learning的算法详情看 传送门 下文中我们会用openai gym来做 ...
- 强化学习 - Q-learning Sarsa 和 DQN 的理解
本文用于基本入门理解. 强化学习的基本理论 : R, S, A 这些就不说了. 先设想两个场景: 一. 1个 5x5 的 格子图, 里面有一个目标点, 2个死亡点二. 一个迷宫, 一个出发点, ...
随机推荐
- c++学习书籍推荐《C++编程思想第一卷》下载
百度云及其他网盘下载地址:点我 编辑推荐 <C++编程思想>(第1卷)(第2版)第1版荣获"软件开发"杂志评选的1996年度 图书震撼大奖,中文版自2000年推出以来, ...
- 上传文件不落地转Base64字符串
1. 问题描述 因需调用第三方公司的图像识别接口,入参是:证件类型.图像类型.图片base64字符串,采用http+json格式调用. 本来采用的方式是:前端对图片做base64处理,后端组装下直接调 ...
- 7.30考试password
先说地球人都看得出来的,该数列所有数都是p的斐波那契数列中所对应的数的次幂,所以一开始都以为是道水题,然而斐波那契数列增长很快,92以后就爆long long ,所以要另谋出路,于是乎向Ren_iva ...
- rabbitmq升级新版本后,需要新建用户。新版本默认禁止别的机器用guest用户访问。
rabbitmq升级新版本后,需要新建用户.新版本默认禁止别的机器用guest用户访问.
- NOIP2018普及T2暨洛谷P5016 龙虎斗
题目链接:https://www.luogu.org/problemnew/show/P5016 分析: 这是一道模拟题.看到题目,我们首先要把它细致的读明白,模拟题特别考察细节,往往会有想不到的坑点 ...
- SpringMvc返回JSON出现"$.result.currentLevel"
"$.result.currentLevel" 问题描述 使用SpringMvc返回一个json数据的时候,会在产生的结果中出现如下的问题:"$.result.curre ...
- 《VR入门系列教程》之2---VR头显
什么是虚拟现实? 虚拟现实的目标:让人们相信真实地处于一个虚拟世界中.要达到这个目标就得让人们的大脑(负责视觉和运动感知部分)欺骗他们.不同技术合在一起才可以创造这种幻觉,包括: 全立 ...
- 《VR入门系列教程》之14---面向大众的Unity3D
大众化的游戏引擎--Unity3D 并不是所有VR应用都是游戏,然而现在做VR开发的几乎都会用专业游戏引擎来做,因为游戏引擎既满足了一个引擎的要求又可以方便地制作出高品质的VR应用.一个游戏引 ...
- 如何简单易懂地描述REST接口编程
网上很多关于REST的介绍,看起来都是云里雾里的,就像在看论文一样,晦涩难懂, 这里有一个链接大概可以简单明了地描述:https://www.zhihu.com/question/28557115
- mount命令中offset参数的意义
mount命令中offset参数的意义 感觉好久没有来写东西了,最近一直忙个不停,今天也一样,总感觉时间不够用,唉,这里来临时总结一下工作中的一点小收获吧.今天要说的是我们常用的解压IM ...