分析了京东内衣销售记录,告诉你妹子们的真Size!
>今天闲暇之余写了一个爬虫例子。通过爬虫去爬取京东的用户评价,通过分析爬取的数据能得到很多结果,比如,哪一种颜色的胸罩最受女性欢迎,以及中国女性的平均size(仅供参考哦~)
打开开发者工具-network,在用户评价页面我们发现浏览器有这样一个请求
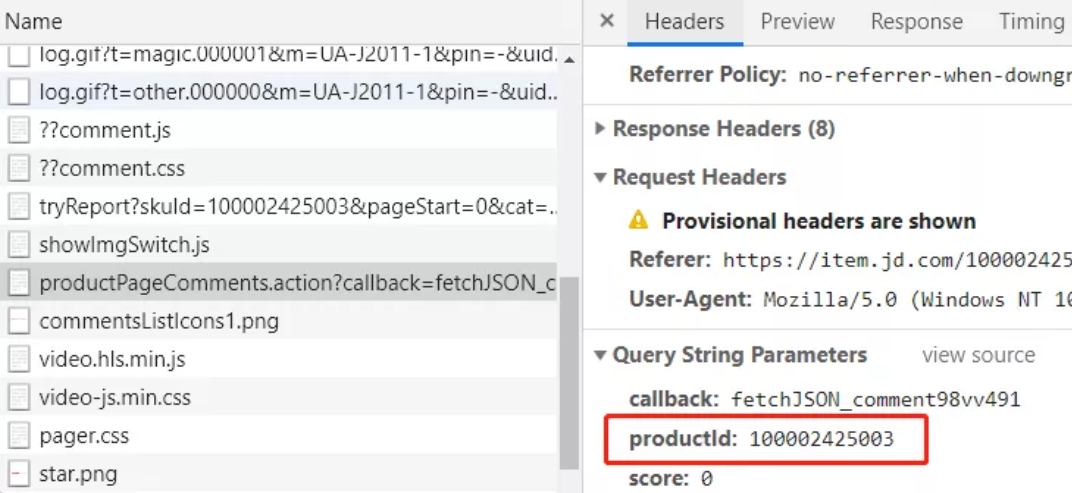
通过分析我们发现主要用的参数有三个productId,page,pageSize。后两个为分页参数,productId是每个商品的id,通过这个id去获取商品的评价记录,所以我们只需要知道每个商品的productId就轻而易举的获取评价了。再来分析搜索页面的网页源代码

通过分析我们发现每个商品都在li标签中,而li标签又有一个data-pid属性,这个对应的值就是商品的productId了。
大概了解了整个流程,就可以开始我们的爬虫工作了。
---
首先我们需要在搜索页面获取商品的id,为下面爬取用户评价提供productId。key_word为搜索的关键字,这里就是【胸罩】
```python
import requests
import re
"""
查询商品id
"""
def find_product_id(key_word):
jd_url = 'https://search.jd.com/Search'
product_ids = []
# 爬前3页的商品
for i in range(1,4):
param = {'keyword': key_word, 'enc': 'utf-8', 'page': i}
response = requests.get(jd_url, params=param)
# 商品id
ids = re.findall('data-pid="(.*?)"', response.text, re.S)
product_ids += ids
return product_ids
```
将前三页的商品id放入列表中,接下来我们就可以爬取评价了
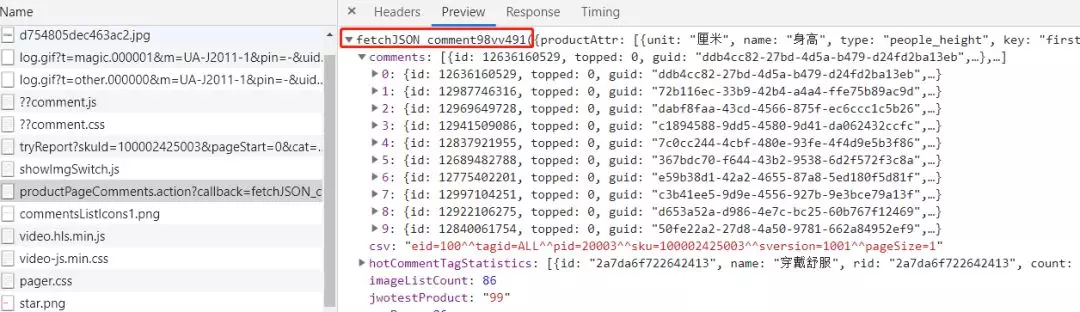
我们通过分析preview发现获取用户评价这个请求响应的格式是一个字符串后面拼接了一个json(如下图),所以我们只要将无用的字符删除掉,就可以获取到我们想要的json对象了。
而在json对象中的comments的内容就是我们最终想要的评价记录
```python
"""
获取评论内容
"""
def get_comment_message(product_id):
urls = ['https://sclub.jd.com/comment/productPageComments.action?' \
'callback=fetchJSON_comment98vv53282&' \
'productId={}' \
'&score=0&sortType=5&' \
'page={}' \
'&pageSize=10&isShadowSku=0&rid=0&fold=1'.format(product_id, page) for page in range(1, 11)]
for url in urls:
response = requests.get(url)
html = response.text
# 删除无用字符
html = html.replace('fetchJSON_comment98vv53282(', '').replace(');', '')
data = json.loads(html)
comments = data['comments']
t = threading.Thread(target=save_mongo, args=(comments,))
t.start()
```
在这个方法中只获取了前10页的评价的url,放到urls这个列表中。通过循环获取不同页面的评价记录,这时启动了一个线程用来将留言数据存到到MongoDB中。
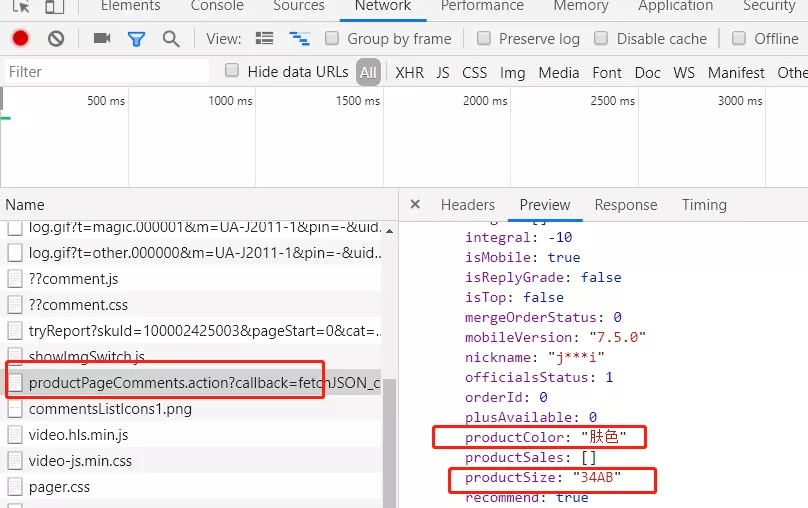
我们继续分析评价记录这个接口发现我们想要的两条数据
- productColor:产品颜色
- productSize:产品尺寸
```python
# mongo服务
client = pymongo.MongoClient('mongodb://127.0.0.1:27017/')
# jd数据库
db = client.jd
# product表,没有自动创建
product_db = db.product
# 保存mongo
def save_mongo(comments):
for comment in comments:
product_data = {}
# 颜色
# flush_data清洗数据的方法
product_data['product_color'] = flush_data(comment['productColor'])
# size
product_data['product_size'] = flush_data(comment['productSize'])
# 评论内容
product_data['comment_content'] = comment['content']
# create_time
product_data['create_time'] = comment['creationTime']
# 插入mongo
product_db.insert(product_data)
```
因为每种商品的颜色、尺寸描述上有差异,为了方面统计,我们进行了简单的数据清洗。这段代码非常的不Pythonic。不过只是一个小demo,大家无视即可。
```python
def flush_data(data):
if '肤' in data:
return '肤色'
if '黑' in data:
return '黑色'
if '紫' in data:
return '紫色'
if '粉' in data:
return '粉色'
if '蓝' in data:
return '蓝色'
if '白' in data:
return '白色'
if '灰' in data:
return '灰色'
if '槟' in data:
return '香槟色'
if '琥' in data:
return '琥珀色'
if '红' in data:
return '红色'
if '紫' in data:
return '紫色'
if 'A' in data:
return 'A'
if 'B' in data:
return 'B'
if 'C' in data:
return 'C'
if 'D' in data:
return 'D'
```
这几个模块的功能编写完毕,下面只需要将他们联系起来
```python
# 创建一个线程锁
lock = threading.Lock()
# 获取评论线程
def spider_jd(ids):
while ids:
# 加锁
lock.acquire()
# 取出第一个元素
id = ids[0]
# 将取出的元素从列表中删除,避免重复加载
del ids[0]
# 释放锁
lock.release()
# 获取评论内容
get_comment_message(id)
product_ids = find_product_id('胸罩')
for i in (1, 5):
# 增加一个获取评论的线程
t = threading.Thread(target=spider_jd, args=(product_ids,))
# 启动线程
t.start()
```
上面代码加锁的原因是为了防止重复消费共享变量
运行之后的查看MongoDB:
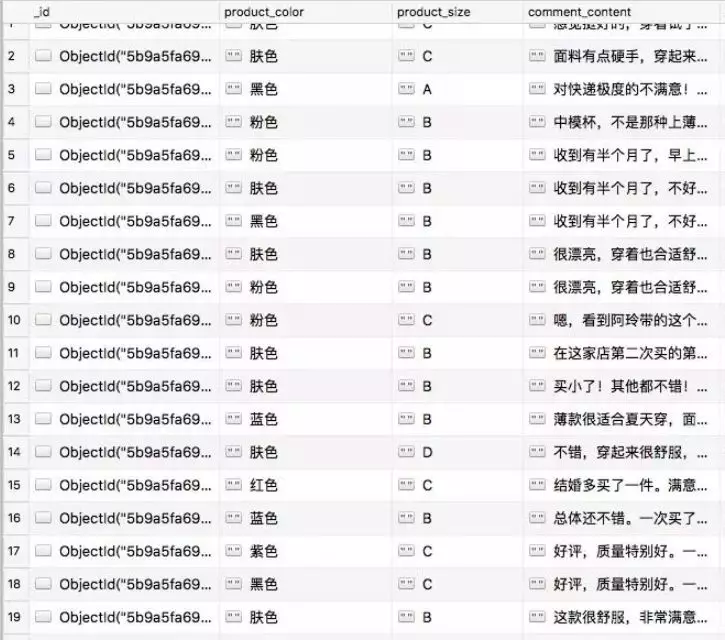
得到结果之后,为了能更直观的表现数据,我们可以用matplotlib库进行图表化展示
```python
import pymongo
from pylab import *
client = pymongo.MongoClient('mongodb://127.0.0.1:27017/')
# jd数据库
db = client.jd
# product表,没有自动创建
product_db = db.product
# 统计以下几个颜色
color_arr = ['肤色', '黑色', '紫色', '粉色', '蓝色', '白色', '灰色', '香槟色', '红色']
color_num_arr = []
for i in color_arr:
num = product_db.count({'product_color': i})
color_num_arr.append(num)
# 显示的颜色
color_arr = ['bisque', 'black', 'purple', 'pink', 'blue', 'white', 'gray', 'peru', 'red']
#labeldistance,文本的位置离远点有多远,1.1指1.1倍半径的位置
#autopct,圆里面的文本格式,%3.1f%%表示小数有三位,整数有一位的浮点数
#shadow,饼是否有阴影
#startangle,起始角度,0,表示从0开始逆时针转,为第一块。一般选择从90度开始比较好看
#pctdistance,百分比的text离圆心的距离
#patches, l_texts, p_texts,为了得到饼图的返回值,p_texts饼图内部文本的,l_texts饼图外label的文本
patches,l_text,p_text = plt.pie(sizes, labels=labels, colors=colors,
labeldistance=1.1, autopct='%3.1f%%', shadow=False,
startangle=90, pctdistance=0.6)
#改变文本的大小
#方法是把每一个text遍历。调用set_size方法设置它的属性
for t in l_text:
t.set_size=(30)
for t in p_text:
t.set_size=(20)
# 设置x,y轴刻度一致,这样饼图才能是圆的
plt.axis('equal')
plt.title("内衣颜色比例图", fontproperties="SimHei") #
plt.legend()
plt.show()
```
运行代码,我们发现肤色的最受欢迎 其次是黑色 (钢铁直男表示不知道是不是真的...)
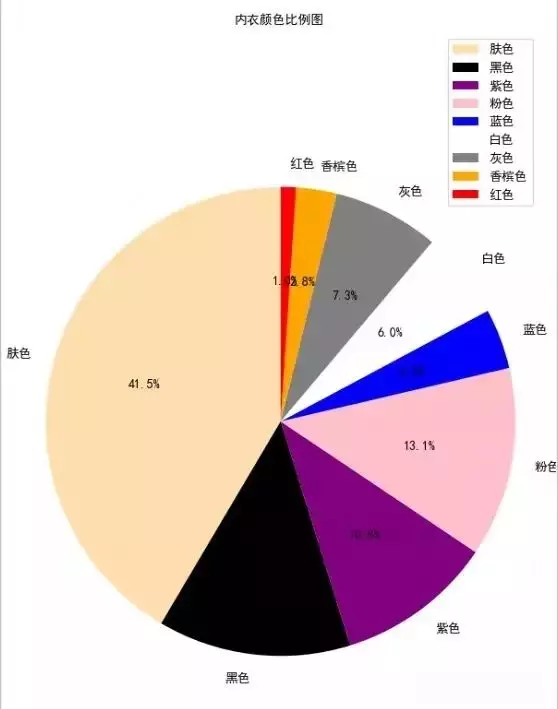
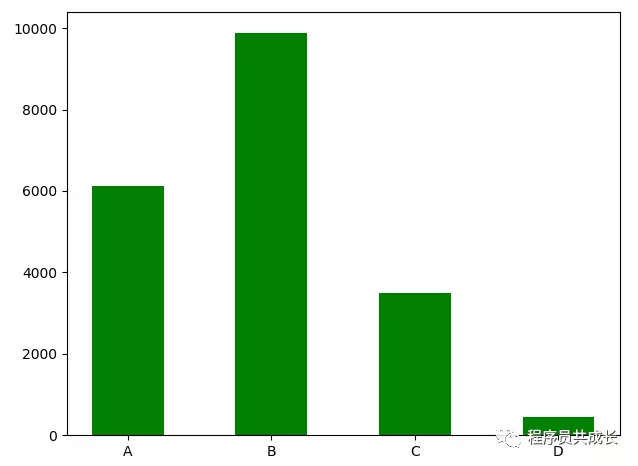
接下来我们再来统计一下size 的分布图,这里用柱状图进行显示
```python
index=["A","B","C","D"]
client = pymongo.MongoClient('mongodb://127.0.0.1:27017/')
db = client.jd
product_db = db.product
value = []
for i in index:
num = product_db.count({'product_size': i})
value.append(num)
plt.bar(left=index, height=value, color="green", width=0.5)
plt.show()
```
运行后我们发现 B size的女性更多一些
---
最后,欢迎大家关注我的公众号(python3xxx)。每天都会推送不一样的Python干货。

分析了京东内衣销售记录,告诉你妹子们的真Size!的更多相关文章
- 分析jQuery源码时记录的一点感悟
分析jQuery源码时记录的一点感悟 1. 链式写法 这是jQuery语法上的最大特色,也许该改改POJO里的set方法,和其他的非get方法什么的,可以把多行代码合并,减去每次 ...
- 图书馆管理系统程序+全套开发文档(系统计划书,系统使用说明,测试报告,UML分析与设计,工作记录)
图书馆管理系统程序+全套开发文档(系统计划书,系统使用说明,测试报告,UML分析与设计,工作记录): https://download.csdn.net/download/qq_39932172/11 ...
- 用 Python 分析网易严选 Bra 销售信息,告诉你她们真实的 Size
今天通过爬虫数据进行分析,一起来看看网易严选商品评论的获取和分析. 声明:这是一篇超级严肃的技术文章,请本着学习交流的态度阅读,谢谢! ! 网易商品评论爬取 分析网页 评论分析 进入到网易严选 ...
- UML作业第三次:分析《书店图书销售管理系统》
分析图书销售管理系统 一.概览 PlantUML类图语法学习小结 <书店图书销售管理>的类图元素 绘制类图脚本程序 绘制的类图 二.PlantUML类图语法 1.类之间的关系绘制 示例: ...
- ELK实时日志分析平台环境部署--完整记录
在日常运维工作中,对于系统和业务日志的处理尤为重要.今天,在这里分享一下自己部署的ELK(+Redis)-开源实时日志分析平台的记录过程(仅依据本人的实际操作为例说明,如有误述,敬请指出)~ ==== ...
- ELK实时日志分析平台环境部署--完整记录(转)
在日常运维工作中,对于系统和业务日志的处理尤为重要.今天,在这里分享一下自己部署的ELK(+Redis)-开源实时日志分析平台的记录过程(仅依据本人的实际操作为例说明,如有误述,敬请指出)~ ==== ...
- SQL Server求解最近多少销售记录的销售额占比总销售额的指定比例
看园中SQL Server大V潇潇隐者的博文,发现一边文就是描述了如标题描述的问题. 具体的问题描述我通过潇潇隐者的博文的截图来阐释: 注意:如果以上截取有所侵权,也请作者告知,再次感谢. 当 ...
- ruby 分析日志,提取特定记录
读取日志中的每一行,分析后存入hash,然后做累加 adx_openx=Hash.new(0) File.open('watch.log.2016-08-24-21').each do |line| ...
- 《linux 网络日志分析与流量监控》记录
mac中有个本机连接vpn的日志,/private/var/log/ppp.log 消除日志(echo "" >/private/var/log/ppp.log ) li ...
随机推荐
- 解决SpringBoot多模块发布时99%的问题?SpringBoot发布的8个原则和4个问题的解决方案
如果使用 SpringBoot 多模块发布到外部 Tomcat,可能会遇到各种各样的问题.本文归纳了以下 8 个原则和发布时经常出现的 4 个问题的解决方案,掌握了这些原则和解决方案,几乎可以解决绝大 ...
- Storm 学习之路(九)—— Storm集成Kafka
一.整合说明 Storm官方对Kafka的整合分为两个版本,官方说明文档分别如下: Storm Kafka Integration : 主要是针对0.8.x版本的Kafka提供整合支持: Storm ...
- HBase 学习之路(三)—— HBase基本环境搭建
一.安装前置条件说明 1.1 JDK版本说明 HBase 需要依赖JDK环境,同时HBase 2.0+ 以上版本不再支持JDK 1.7 ,需要安装JDK 1.8+ .JDK 安装方式见本仓库: Lin ...
- 【设计模式】行为型07备忘录模式(Memento Pattern)
参考地址:http://www.runoob.com/design-pattern/memento-pattern.html 对原文总结调整,以及修改代码以更清晰的展示: 备忘录模式(快照模式): ...
- PATA 1065 A+B and C (64bit)
1065. A+B and C (64bit) (20) 时间限制 100 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 HOU, Qiming G ...
- Django迁移数据库报错
Django迁移数据库报错 table "xxx" already exists错误 django在migrate时报错django migrate error: table 'x ...
- 生产力工具:shell 与 Bash 脚本
生产力工具:shell 与 Bash 脚本 作者:吴甜甜 个人博客网站: wutiantian.github.io 注意:本文只是我个人总结的学习笔记,不适合0基础人士观看. 参考内容: 王顶老师 l ...
- 委托在Smobiler自定义控件中运用
委托(Delegate) C# 中的委托(Delegate)类似于 C 或 C++ 中函数的指针.委托(Delegate) 是存有对某个方法的引用的一种引用类型变量.可以将方法当作另一个方法的参数来进 ...
- linuxprobe培训第1节课笔记2019年7月5日
报了老刘的RHCE培训,这是老刘上课笔记简略版. 老刘在课上介绍了开源共享精神和大胡子(Richard M. Stallman—GNU创始人).linux发展史(Linus Benedict Torv ...
- TCP/IP协议与OSI体系结构总结
什么是TCP/IP协议?TCP/IP协议不是一个简单的TCP和IP协议,而是个协议族的统称,是网络通信的一套协议集合. TCP/IP协议与OSI七层模型在模块分布上具有一定的区别,OSI参考模型通信协 ...