win10上部署Hadoop-2.7.3——非Cygwin、非虚拟机
开始接触Hadoop,听人说一般都是在Lunix下部署Hadoop,但是本人Lunix不是很了解,所以Google以下如何在Win10下安装Hadoop(之后再在Lunix下弄),找到不少文章,以下是主要参考的文章:
1、Hadoop installation on windows without cygwin in 10 mints
3、Apache Hadoop for Windows Platform
这里是按照第一篇文章操作的。
一、安装jdk,地址为http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 具体的操作以及配置环境变量这里就不演示了,这里有一点需要注意的是默认会安装在C:\Program Files 下,开始我也是安装在这里,但是后来报错了,报什么“JAVA_HOME”的错误具体的记不清了。查了一下说是因为安装路径中有空格,晕了,所以安装在如下目录:

二、下载Hadoop,地址为 https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/ 这里选择的是hadoop-2.7.3.tar.gz
三、将其解压到某一文件夹,这里为D:\hadoop\hadoop-2.7.3
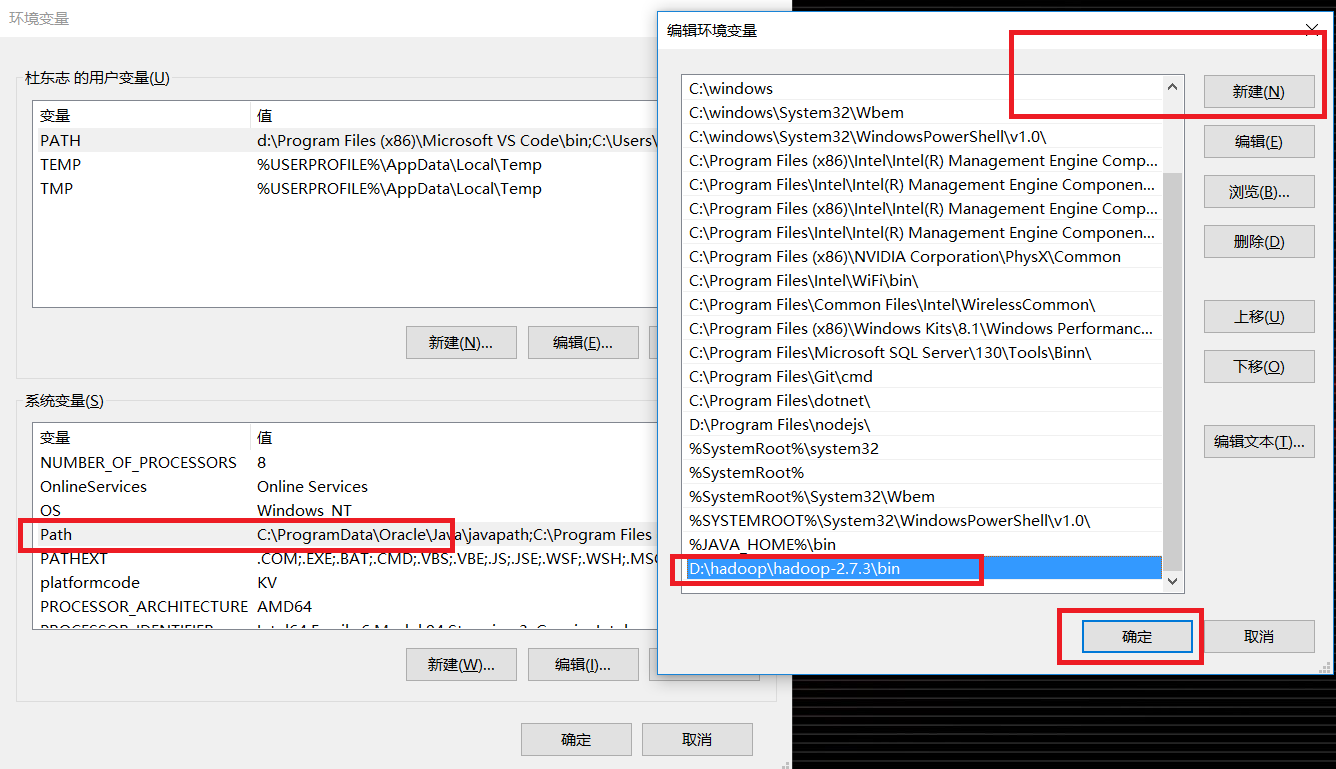
四、添加“HADOOP_HOME”环境变量,并添加到Path环境变量中,按照下图操作

五、修改Hadoop配置文件,在这之前你要先下载sardetushar_gitrepo_download ,之后解压,删掉D:\hadoop\hadoop-2.7.3目录下的bin、etc文件夹,用刚刚解压的替换。
1、D:\hadoop\hadoop-2.7.3\etc\hadoop\core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
2、D:\hadoop\hadoop-2.7.3\etc\hadoop\mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
3、D:\hadoop\hadoop-2.7.3\etc\hadoop\hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoop/data/datanode</value>
</property>
</configuration>
这个配置这里要感谢一下这篇帖子:http://stackoverflow.com/questions/34871814/failed-to-start-namenode-in-hadoop 按照第一篇教程配置会出错的!!!
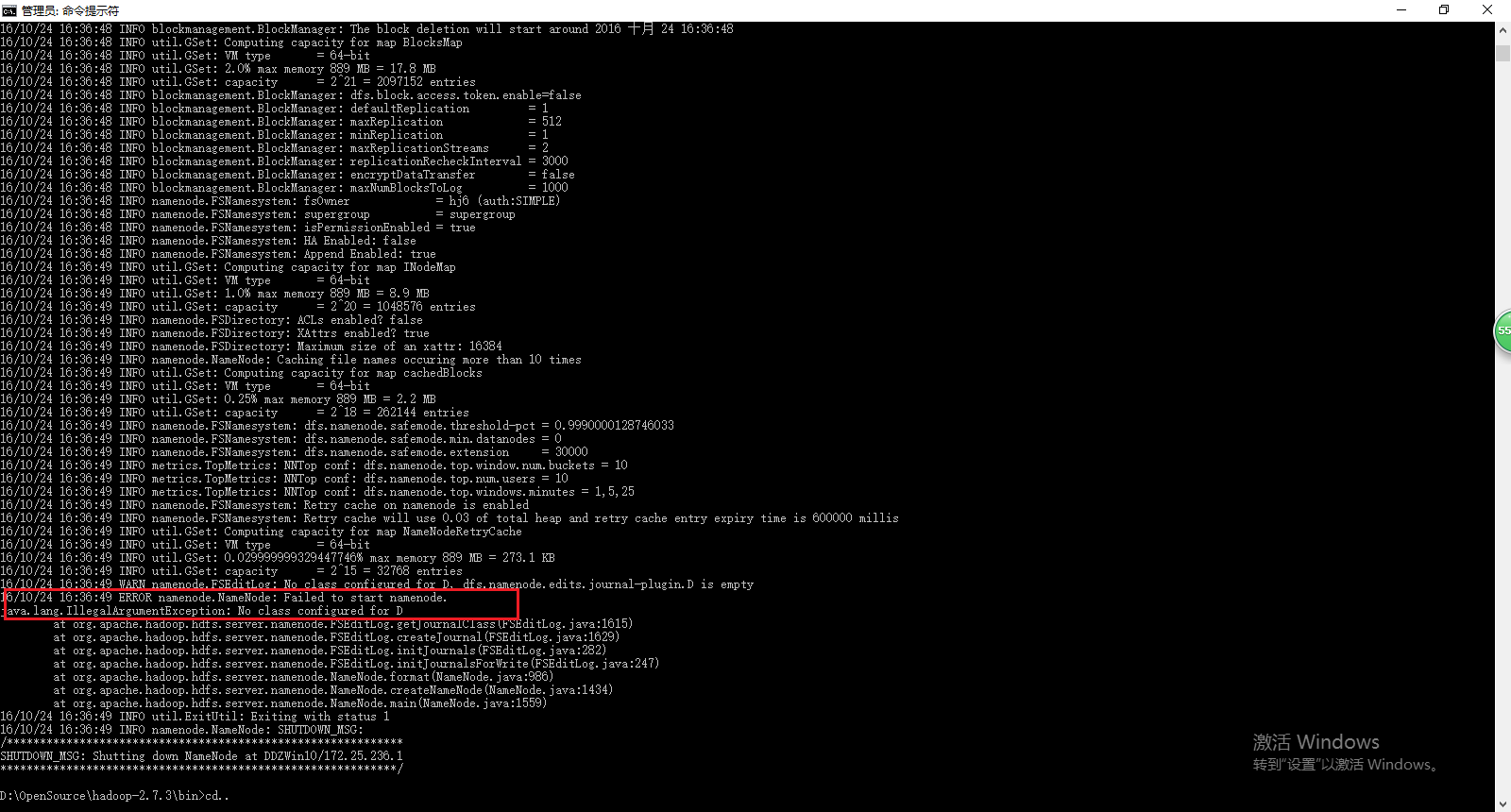
如果你的路径形如d:/hadoop/data/namenode 就会出现上图错误,如果路径是在E:,那么上图中的异常就会是E
4、D:\hadoop\hadoop-2.7.3\etc\hadoop\yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
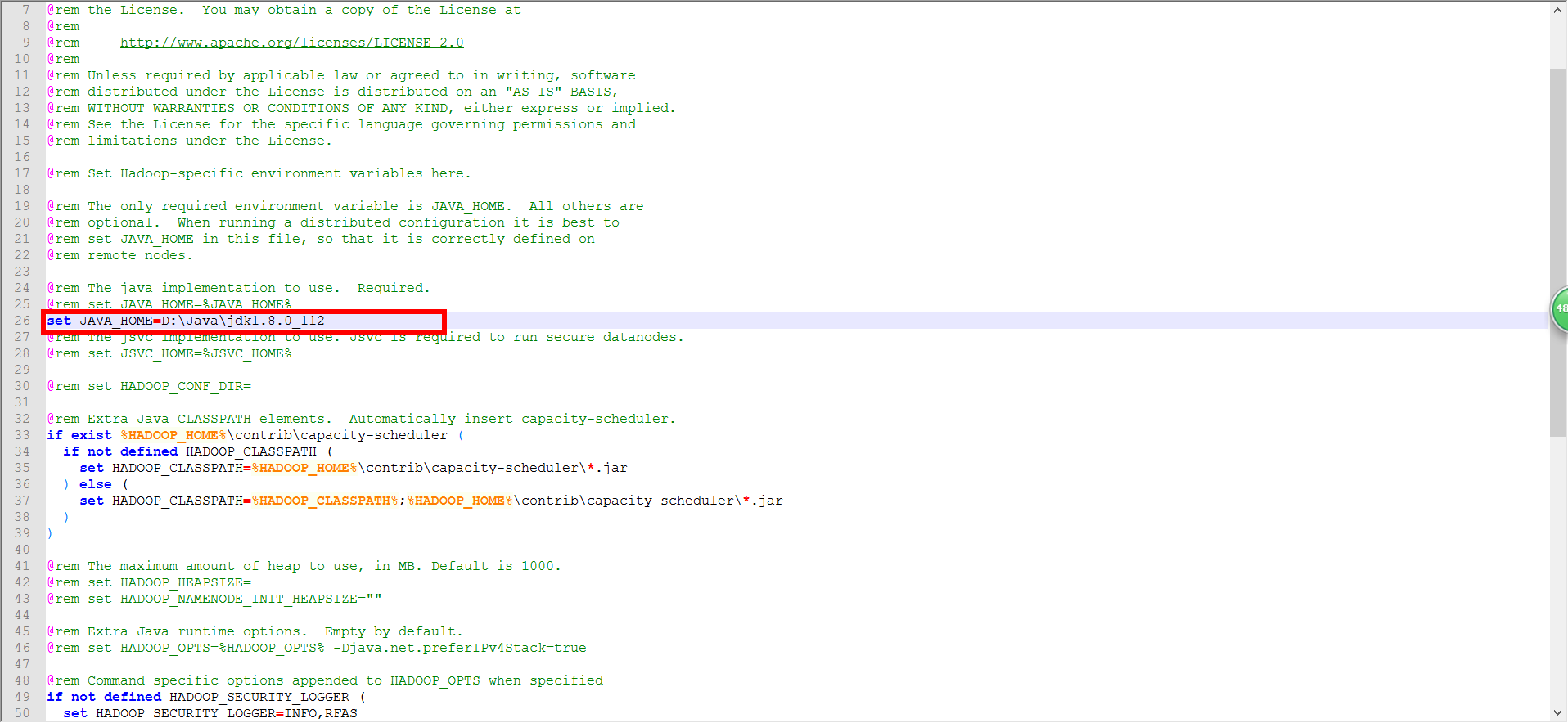
5、D:\hadoop\hadoop-2.7.3\etc\hadoop\hadoop-env.cmd (修改JDK的安装路径)
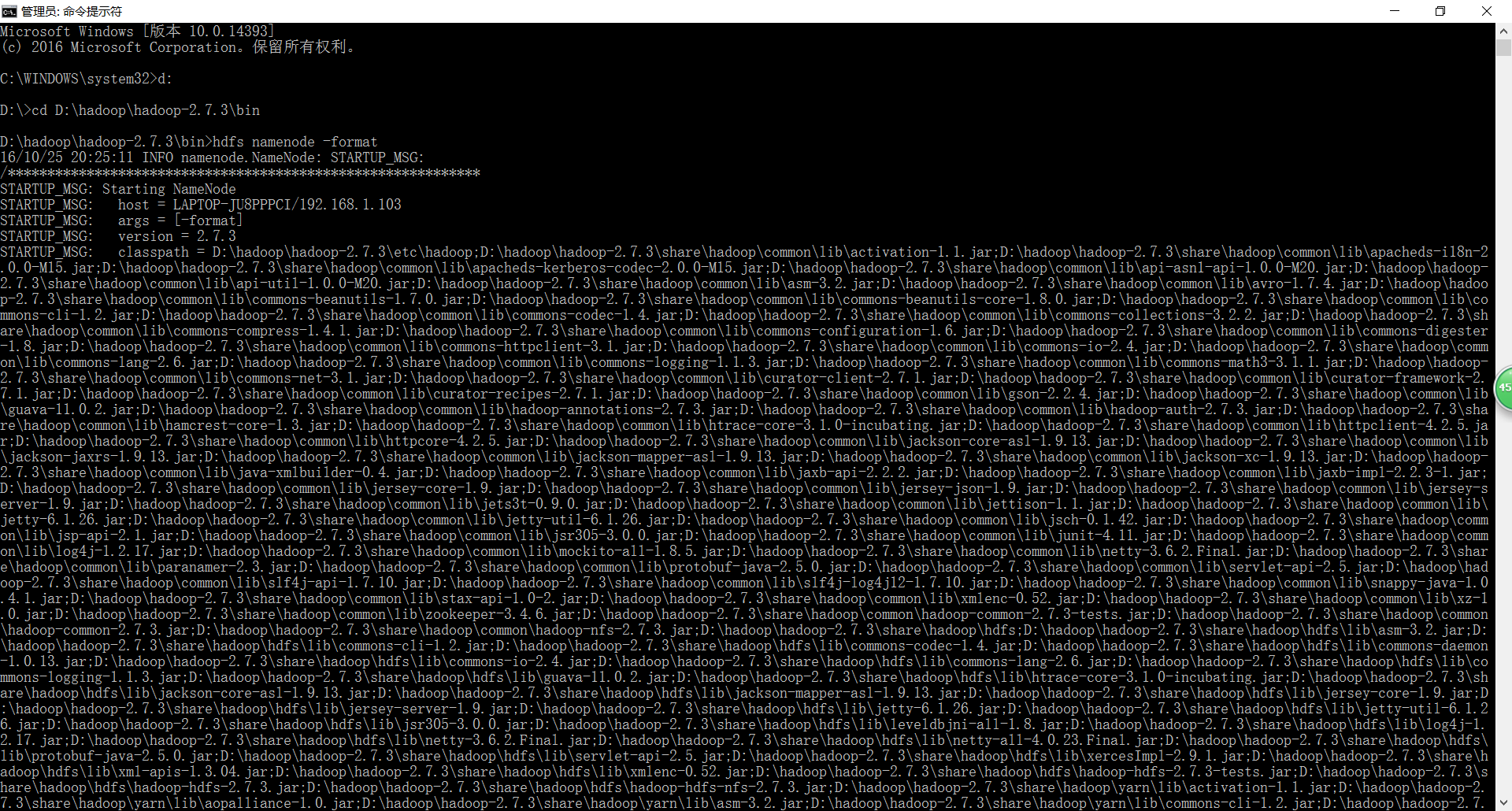
六、格式化HDFS文件系统,hdfs namenode -format 如下图,
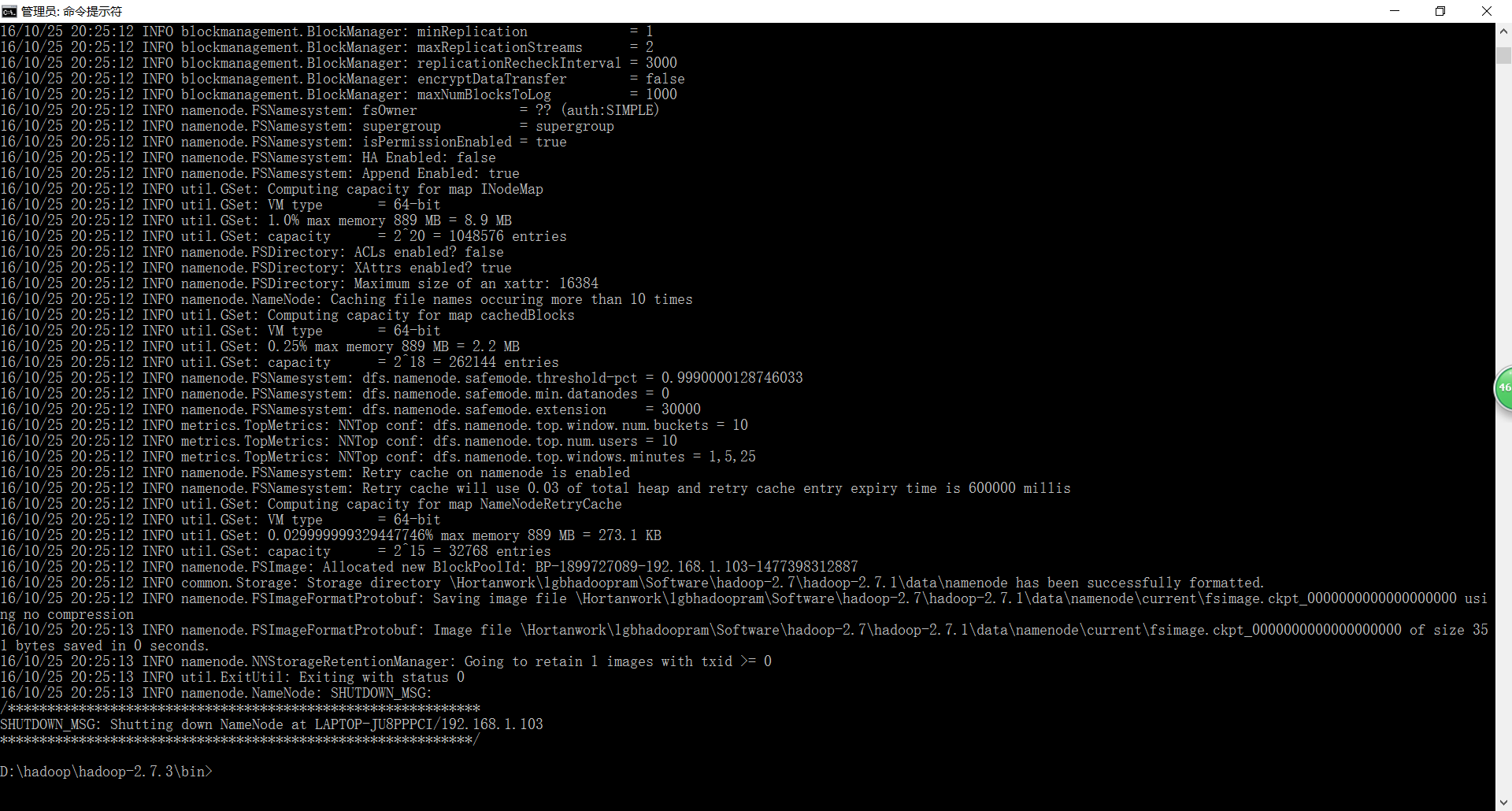
如果这一步没有什么异常基本没有问题了。
七、在命令行(管理员)将目录指向D:\hadoop\hadoop-2.7.3\sbin,键入“start-all”
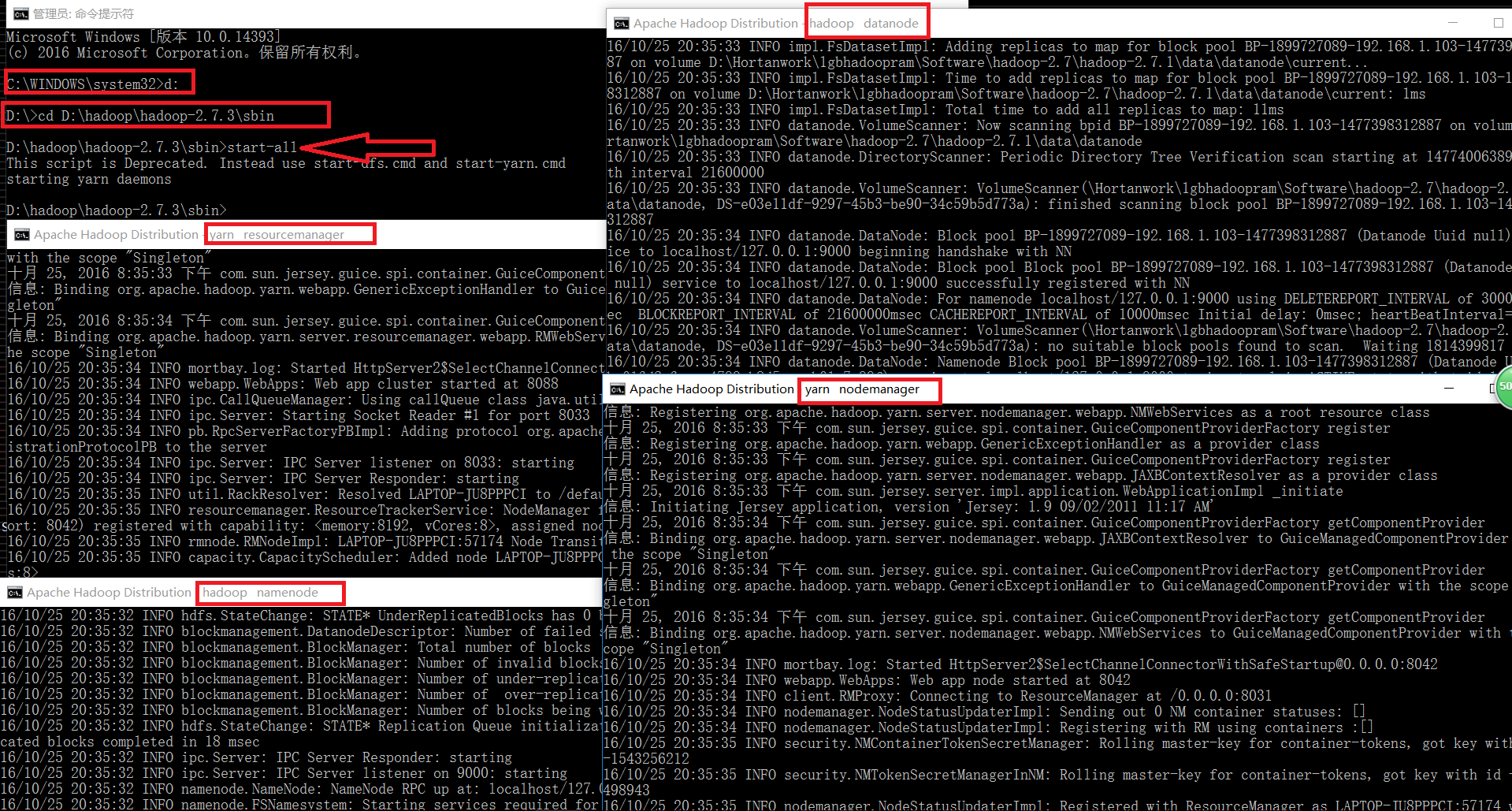
Namenode、Datanode、YARN resourcemanager、YARN nodemanager四个进程启动成功,再看一下网站截图:
localhost:8088

localhost:50070

最后我们可以使用“stop-all”停止Hadoop

至此,Hadoop部署已经结束。第一次接触还是挺兴奋的!
win10上部署Hadoop-2.7.3——非Cygwin、非虚拟机的更多相关文章
- Win10上部署Apollo配置中心
基于Docker在Win10上部署Apollo配置中心 https://www.jianshu.com/p/a1215056ce75 http://nobodyiam.com/2016/07/09/i ...
- windows上部署hadoop(单机版)
在window系统开发程序时,远程linux服务器上的hadoop速度很慢,影响开发效率,能不能在本地搭建hadoop环境的?答案肯定的,且看下文如何在window上部署hadoop: (源文地址:h ...
- Linux suse x86_64 环境上部署Hadoop启动失败原因分析
一.问题症状: 在安装hadoop的时候报类似如下的错误: # A fatal error has beendetected by the Java Runtime Environment: # # ...
- 在ubuntu上部署hadoop时出现的问题
1. 配置ssh登录 不须要改动/etc/ssh/sshd_config 2. 新建hadoop用户时,home以下没有hadoop文件夹 用以下命令创建 useradd -m hadoop 3. n ...
- 【大数据系列】win10上安装hadoop开发环境
为了方便采用了Cygwin模拟linux环境的方法 一.安装JDK以及下载hadoop hadoop官网下载hadoop http://hadoop.apache.org/releases.html ...
- 在Docker Swarm上部署Apache Storm:第1部分
[编者按]本文来自 Baqend Tech Blog,描述了如何在 Docker Swarm,而不是在虚拟机上部署和调配Apache Storm集群.文章系国内 ITOM 管理平台 OneAPM 编译 ...
- 基于Kubernetes在AWS上部署Kafka时遇到的一些问题
作者:Jack47 转载请保留作者和原文出处 欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 交代一下背景:我们的后台系统是一套使用Kafka消息队列的数据处理管线 ...
- 虚拟机评估——如何确定一个CPU核上部署的虚拟机数量?
最近研究虚拟化技术,不可避免遇到一个问题:如何评估物理主机上虚拟主机的容量?下面这篇文章的思路有一定的启发性,转发一下. 如何确定一个CPU核上部署的虚拟机数量? 摘要:本文说明一个CPU核上部署虚拟 ...
- 应用服务器上部署自己的 blog 和 wiki 组件。
协作性应用程序 这就是 Web 2.0 的全部,尽管该术语出现才几乎一年的时间,但现在好像只有烹饪杂志还没有加入到讨论 Web 2.0 未来出路的行列中.自从出现了里程碑式的文章 "What ...
随机推荐
- .NET Core中间件的注册和管道的构建(2)---- 用UseMiddleware扩展方法注册中间件类
.NET Core中间件的注册和管道的构建(2)---- 用UseMiddleware扩展方法注册中间件类 0x00 为什么要引入扩展方法 有的中间件功能比较简单,有的则比较复杂,并且依赖其它组件.除 ...
- 干货分享:SQLSERVER使用裸设备
干货分享:SQLSERVER使用裸设备 这篇文章也适合ORACLE DBA和MYSQL DBA 阅读 裸设备适用于Linux和Windows 在ORACLE和MYSQL里也是支持裸设备的!! 介绍 大 ...
- Base64编码
Base64编码 写在前面 今天在做一个Android app时遇到了一个问题:Android端采用ASE对称加密的数据在JavaWeb(jre1.8.0_7)后台解密时,居然解密失败了!经过测试后发 ...
- Android混合开发之WebViewJavascriptBridge实现JS与java安全交互
前言: 为了加快开发效率,目前公司一些功能使用H5开发,这里难免会用到Js与Java函数互相调用的问题,这个Android是提供了原生支持的,不过存在安全隐患,今天我们来学习一种安全方式来满足Js与j ...
- C#多线程之基础篇3
在上一篇C#多线程之基础篇2中,我们主要讲述了确定线程的状态.线程优先级.前台线程和后台线程以及向线程传递参数的知识,在这一篇中我们将讲述如何使用C#的lock关键字锁定线程.使用Monitor锁定线 ...
- node模块加载层级优化
模块加载痛点 大家也或多或少的了解node模块的加载机制,最为粗浅的表述就是依次从当前目录向上级查询node_modules目录,若发现依赖则加载.但是随着应用规模的加大,目录层级越来越深,若是在某个 ...
- 使用mybatis-generator在自动生成Model类和Mapper文件
使用mybatis-generator插件可以很轻松的实现mybatis的逆向工程,即,能通过表结构自动生成对应的java类及mapper文件,可以大大提高工作效率,并且它提供了很多自定义的设置可以应 ...
- obj.style.z-index的正确写法
obj.style.z-index的正确写法 今天发现obj.style.z-index在js里面报错,后来才知道在js里应该把含"-"的字符写成驼峰式,例如obj.style.z ...
- 茂名石化BPM应用实践 ——业务协同及服务共享平台建设和应用
一.茂名石化简介 茂名石化隶属于中国石油化工集团公司,创建于1955年,是国家"一五"期间156项重点项目之一.经过50多年的发展,茂名石化已成为我国生产规模最大的炼油化工企业之一 ...
- git命令行操作
从本地上传代码到仓库(假设已经建好仓库): 1.初始化: git init 2.将所有文件加入缓存区: git add * 3.提交当前工作空间的修改内容: git commit -m 'commit ...