Join的表顺序
在今天的文章里,我想谈下SQL Server里一个非常有趣的话题:在表联接里,把表指定顺序的话是否有意义?每次我进行查询和性能调优的展示时,大家都会问我他们是否应该把联接中的表指定下顺序,是否会帮助查询优化器得出一个更好性能的执行计划。我们来看下这个重要又有趣的问题。
合并联接(Inner Joins)
假设在AdventureWorks数据库里,你要在Sales.SalesOrderHeader表和Sales.SalesOrderDetail表之间做一个内联接:
USE AdventureWorks
GO -- Returns for each SalesOrderHeader record all associated SalesOrderDetail records
-- SQL Server performs a Merge Join, because both tables are phyiscally sorted
-- by the column "SalesOrderID".
SELECT
h.SalesOrderID,
h.CustomerID,
d.SalesOrderDetailID,
d.ProductID,
d.LineTotal
FROM Sales.SalesOrderHeader h
JOIN Sales.SalesOrderDetail d
ON h.SalesOrderID = d.SalesOrderID
ORDER BY SalesOrderID
GO
当我们查看结果的执行计划时,我们可以看到查询优化器选择了合并联接(Inner Join)作为物理联接运算符,Sales.SalesOrderHeader表作为合并联接的外联接。在执行计划里表的顺序和我们在逻辑T-SQL查询里的顺序是一样的。
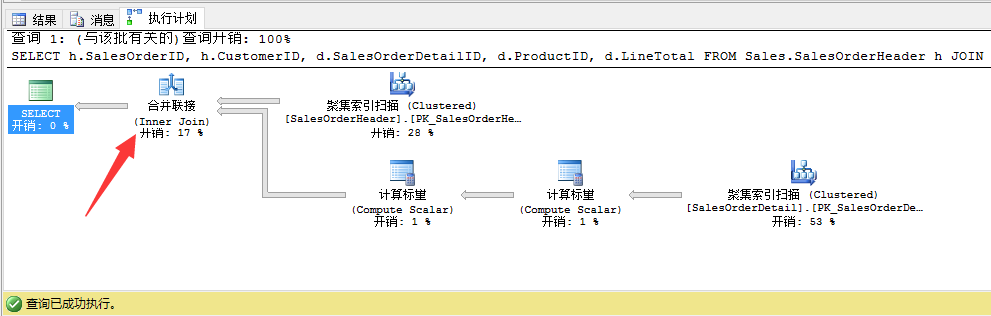
现在的问题是,当我们在逻辑T-SQL查询里交换下2个表的顺序,执行计划会发生什么?我们来试下:
-- The logical ordering of the tables during an Inner Join
-- doesn't matter. It's up to the Query Optimnizer to arrange
-- the tables in the best order.
-- This query produces the same execution plan as the previous one.
SELECT
h.SalesOrderID,
h.CustomerID,
d.SalesOrderDetailID,
d.ProductID,
d.LineTotal
FROM Sales.SalesOrderDetail d
JOIN Sales.SalesOrderHeader h
ON d.SalesOrderID = h.SalesOrderID
ORDER BY SalesOrderID
GO
但我们现在看结果的执行计划,我们发现很有意思:

在执行计划里没有任何改变!查询优化器选择了和刚才查询一样的物理执行计划。但为什么?答案非常简单:查询优化器总引用最小的表(基于我们的统计信息!)作为每个物理连接运算符(嵌套循环联接,合并联接,哈希匹配联接)的外联接表。因此在T-SQL查询里的表的逻辑顺序不会对查询优化器造成任何影响。按正确的顺序访问我们的表是查询优化器的职责。
在表A和表B之间的合并联接与表B和表A之间的合并联接是一样的。

外联接(Outer Join)
在外联接(left join,right join)里,表顺序会有啥影响?我们来看下面的查询,在Sales.Customer表和 Sales.SalesOrderHeader表之间进行左联接。
-- Execute the query with an Outer Join.
-- Now we are also getting back customers that haven't placed orders.
-- The left table is the preserving one, and missing rows from the right table are added with NULL values.
-- SQL Server performs a "Merge Join (Left Outer Join)" in the execution plan.
SELECT
c.CustomerID,
h.SalesOrderID
FROM Sales.Customer c
LEFT JOIN Sales.SalesOrderHeader h
ON c.CustomerID = h.CustomerID
GO
当我们查看结果执行计划时,我们会看到查询优化器已经隐藏了我们的表顺序。
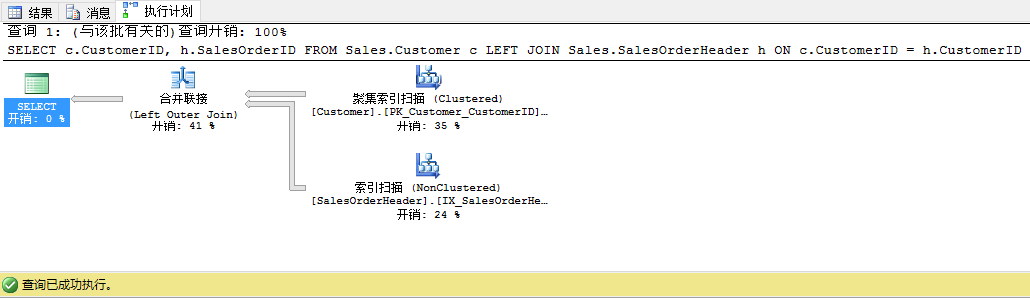
当然这次我们不能修改T-SQL语句里的表顺序,不然查询会返回错误的结果。但当我们在查询里切换下表会发生什么,不是左联接,我们用右联接。我们来试下:
-- You can rewrite the query from above with a Right Outer Join when you swap the order
-- of the tables. This time you get back the same result (32166 rows).
SELECT
c.CustomerID,
h.SalesOrderID
FROM Sales.SalesOrderHeader h
RIGHT JOIN Sales.Customer c
ON c.CustomerID = h.CustomerID
GO
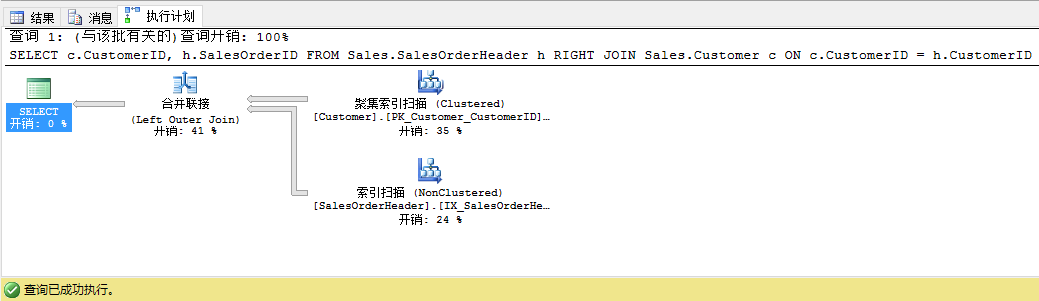
当我们看执行计划时,我们再次看到没有任何改变:查询优化器转化右联接为左联接,重排了下表还是返回正确的结果。查询优化器的目标是使用最小表作为物理联接运算符的外表。因此在外联接里表的顺序也不会影响查询优化器。只要我们的统计信息是正确的,查询优化器总会选择正确的顺序。
在表A和表B之间的左联接与表B和表A之间的右联接是一样的。
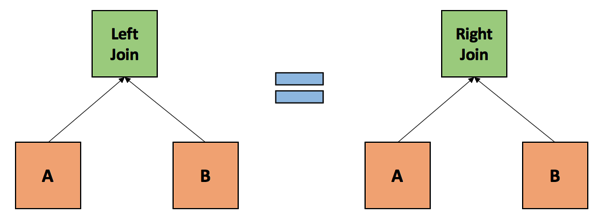
小结:
在这篇文章里我们讨论对于联接,表的顺序是否会影响执行计划。如我们所见,这完全由查询优化器来决定选择优化的表顺序——基于统计信息。在合并联接里表顺序完全不影响,使用外联接的话,SQL Server可以通过切换左联接/右联接来重排表,还是获得正确的结果。
参考文章:
http://www.sqlpassion.at/archive/2015/12/15/table-ordering-for-joins/
Join的表顺序的更多相关文章
- JOIN关联表中ON,WHERE后面跟条件的区别
select * from td left join (select case_id as sup_case_id , count(*) supervise_number from td_kcdc ...
- join多表连接和group by分组
join多表连接和group by分组 上一篇里面我们实现了单表查询和top N查询,这一篇我们来讲述如何实现多表连接和group by分组. 一.多表连接 多表连接的时间是数据库一个非常耗时的操作, ...
- 【Spark调优】大表join大表,少数key导致数据倾斜解决方案
[使用场景] 两个RDD进行join的时候,如果数据量都比较大,那么此时可以sample看下两个RDD中的key分布情况.如果出现数据倾斜,是因为其中某一个RDD中的少数几个key的数据量过大,而另一 ...
- MySQL JOIN 多表连接
除了常用的两个表连接之外,SQL(MySQL) JOIN 语法还支持多表连接.多表连接基本语法如下: 1 ... FROM table1 INNER|LEFT|RIGHT JOIN table2 ON ...
- 对于大量left join 的表查询,可以在关键的 连接节点字段上创建索引。
对于大量left join 的表查询,可以在关键的 连接节点字段上创建索引. 问题: 大量的left join 怎么优化 select a.id,a.num,b.num,b.pcs,c.num, c. ...
- left join 连表时,on后多条件无效问题
http://www.cnblogs.com/guixiaoming/p/6516261.html left join 连表时,on后多条件无效问题 最近开发素材库项目,各种关系复杂的表,一度6张表的 ...
- 【Spark调优】小表join大表数据倾斜解决方案
[使用场景] 对RDD使用join类操作,或者是在Spark SQL中使用join语句时,而且join操作中的一个RDD或表的数据量比较小(例如几百MB或者1~2GB),比较适用此方案. [解决方案] ...
- mybatis逆向工程,实现join多表查询,避免多表相同字段名的陷阱
mybatis逆向工程,实现join多表查询,避免多表相同字段名的陷阱 前言:使用 mybatis generator 生成表格对应的pojo.dao.mapper,以及对应的example的 ...
- 大数据开发实战:Hive优化实战3-大表join大表优化
5.大表join大表优化 如果Hive优化实战2中mapjoin中小表dim_seller很大呢?比如超过了1GB大小?这种就是大表join大表的问题.首先引入一个具体的问题场景,然后基于此介绍各自优 ...
随机推荐
- hibernate----component-entity (人-地址-学校)
package com.ij34.dao; import javax.persistence.*; @Entity @Table(name="school_inf") public ...
- XE8 FMX SpeedButton 大图标(改 Style)
自从 XE8 提供 ImageList 带来了很多便利,但 SpeedButton 的图标太小(不够大气),还好 FMX 提供了 Style 可供使用者自订图标大小及显示位置,请自行按图索骥,做一遍: ...
- 几个最常用的git命令
之前在Windows下一直用可视化的tortoise git,在Linux下最好是用命令行,以下是常用的git命令: git status:显示当前已修改的文件,新增的文件 git checkout ...
- Bootstrap Table表格一直加载(load)不了数据-解决办法
bootstrap-table是一个基于Bootstrap风格的强大的表格插件神器,官网:http://bootstrap-table.wenzhixin.net.cn/zh-cn/ 这里列出遇到的一 ...
- apache maven pom setting
<?xml version="1.0" encoding="UTF-8"?> <!-- Licensed to the Apache Soft ...
- mysql与oracle常用函数及数据类型对比
最近在转一个原来使用oracle,打算改为mysql的系统,有些常用的oracle函数的mysql实现顺便整理了下,主要是系统中涉及到的(其实原来是专门整理过一个详细doc的,只是每次找word麻烦) ...
- 一道js面试题
当然这道面试题并不一定就能在你面试的时候遇到,但是不怕一万就怕万一,会的多一些还是好的. 问:怎么判断一串字符中哪个字符出现的最多,最多几次或者这串字符分别有哪些,每个字符出现了几次.写你请出运算代 ...
- 用css计算选中的复选框有几个
上代码: <!DOCTYPE html> <html> <head> <meta charset='UTF-8'> <title>计数< ...
- jQuery als.js 跑马灯
ali.js是一款滚动插件,滚动的内容可包含文字和图片.它的API也很强大,包括滚动区域可见个数.每次滚动个数.滚动方向.是否循环滚动.是否自动滚动.滚动间隔时间.滚动动画速度.动画效果.滚动方向以及 ...
- Ampersand.js - 模块化的 JS 应用程序开发框架
Ampersand.js 是一个高度模块化,松耦合,用于构建先进的 JavaScript 应用程序的框架.通过良好定义的方法,结合了一系列微小的 CommonJS 模块.条理清晰,没有多余的冗余代码. ...