Spark踩坑记:共享变量
收录待用,修改转载已取得腾讯云授权
前言
前面总结的几篇spark踩坑博文中,我总结了自己在使用spark过程当中踩过的一些坑和经验。我们知道Spark是多机器集群部署的,分为Driver/Master/Worker,Master负责资源调度,Worker是不同的运算节点,由Master统一调度。
而Driver是我们提交Spark程序的节点,并且所有的reduce类型的操作都会汇总到Driver节点进行整合。节点之间会将map/reduce等操作函数传递一个独立副本到每一个节点,这些变量也会复制到每台机器上,而节点之间的运算是相互独立的,变量的更新并不会传递回Driver程序。
那么有个问题,如果我们想在节点之间共享一份变量,比如一份公共的配置项,该怎么办呢?Spark为我们提供了两种特定的共享变量,来完成节点间变量的共享。 本文首先简单的介绍spark以及spark streaming中累加器和广播变量的使用方式,然后重点介绍一下如何更新广播变量。
累加器
顾名思义,累加器是一种只能通过关联操作进行“加”操作的变量,因此它能够高效的应用于并行操作中。它们能够用来实现counters和sums。Spark原生支持数值类型的累加器,开发者可以自己添加支持的类型,在2.0.0之前的版本中,通过继承AccumulatorParam来实现,而2.0.0之后的版本需要继承AccumulatorV2来实现自定义类型的累加器。
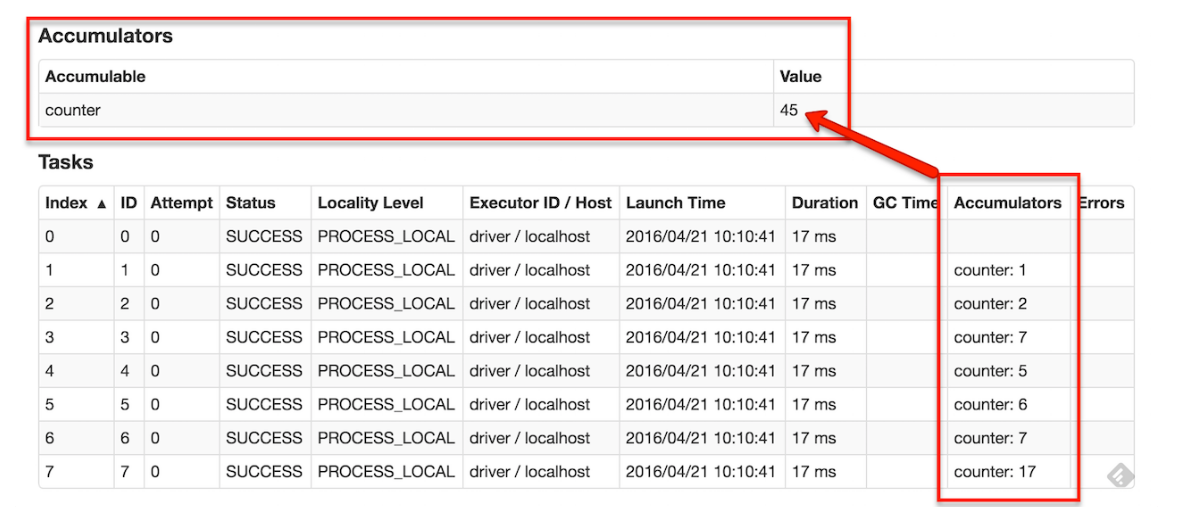
如果创建了一个具名的累加器,它可以在spark的UI中显示。这对于理解运行阶段(running stages)的过程有很重要的作用。如下图:
在2.0.0之前版本中,累加器的声明使用方式如下:
scala> val accum = sc.accumulator(0, "My Accumulator")
accum: spark.Accumulator[Int] = 0
scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum += x)
...
10/09/29 18:41:08 INFO SparkContext: Tasks finished in 0.317106 s
scala> accum.value
res2: Int = 10
累加器的声明在2.0.0发生了变化,到2.1.0也有所变化,具体可以参考官方文档,我们这里以2.1.0为例将代码贴一下:
scala> val accum = sc.longAccumulator("My Accumulator")
accum: org.apache.spark.util.LongAccumulator = LongAccumulator(id: 0, name: Some(My Accumulator), value: 0)
scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum.add(x))
10/09/29 18:41:08 INFO SparkContext: Tasks finished in 0.317106 s
scala> accum.value
res2: Long = 10
广播变量
累加器比较简单直观,如果我们需要在spark中进行一些全局统计就可以使用它。但是有时候仅仅一个累加器并不能满足我们的需求,比如数据库中一份公共配置表格,需要同步给各个节点进行查询。OK先来简单介绍下spark中的广播变量:
广播变量允许程序员缓存一个只读的变量在每台机器上面,而不是每个任务保存一份拷贝。例如,利用广播变量,我们能够以一种更有效率的方式将一个大数据量输入集合的副本分配给每个节点。Spark也尝试着利用有效的广播算法去分配广播变量,以减少通信的成本。
一个广播变量可以通过调用SparkContext.broadcast(v)方法从一个初始变量v中创建。广播变量是v的一个包装变量,它的值可以通过value方法访问,下面的代码说明了这个过程:
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0)
scala> broadcastVar.value
res0: Array[Int] = Array(1, 2, 3)
从上文我们可以看出广播变量的声明很简单,调用broadcast就能搞定,并且scala中一切可序列化的对象都是可以进行广播的,这就给了我们很大的想象空间,可以利用广播变量将一些经常访问的大变量进行广播,而不是每个任务保存一份,这样可以减少资源上的浪费。
更新广播变量(rebroadcast)
广播变量可以用来更新一些大的配置变量,比如数据库中的一张表格,那么有这样一个问题,如果数据库当中的配置表格进行了更新,我们需要重新广播变量该怎么做呢。上文对广播变量的说明中,我们知道广播变量是只读的,也就是说广播出去的变量没法再修改,那么我们应该怎么解决这个问题呢?
答案是利用spark中的unpersist函数
Spark automatically monitors cache usage on each node and drops out old data partitions in a least-recently-used (LRU) fashion. If you would like to manually remove an RDD instead of waiting for it to fall out of the cache, use the RDD.unpersist() method.
上文是从spark官方文档摘抄出来的,我们可以看出,正常来说每个节点的数据是不需要我们操心的,spark会自动按照LRU规则将老数据删除,如果需要手动删除可以调用unpersist函数。
那么更新广播变量的基本思路:将老的广播变量删除(unpersist),然后重新广播一遍新的广播变量,为此简单包装了一个用于广播和更新广播变量的wraper类,如下:
import java.io.{ ObjectInputStream, ObjectOutputStream }
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.streaming.StreamingContext
import scala.reflect.ClassTag
// This wrapper lets us update brodcast variables within DStreams' foreachRDD
// without running into serialization issues
case class BroadcastWrapper[T: ClassTag](
@transient private val ssc: StreamingContext,
@transient private val _v: T) {
@transient private var v = ssc.sparkContext.broadcast(_v)
def update(newValue: T, blocking: Boolean = false): Unit = {
// 删除RDD是否需要锁定
v.unpersist(blocking)
v = ssc.sparkContext.broadcast(newValue)
}
def value: T = v.value
private def writeObject(out: ObjectOutputStream): Unit = {
out.writeObject(v)
}
private def readObject(in: ObjectInputStream): Unit = {
v = in.readObject().asInstanceOf[Broadcast[T]]
}
}
利用该wrapper更新广播变量,大致的处理逻辑如下:
// 定义
val yourBroadcast = BroadcastWrapper[yourType](ssc, yourValue)
yourStream.transform(rdd => {
//定期更新广播变量
if (System.currentTimeMillis - someTime > Conf.updateFreq) {
yourBroadcast.update(newValue, true)
}
// do something else
})
总结
spark中的共享变量是我们能够在全局做出一些操作,比如record总数的统计更新,一些大变量配置项的广播等等。而对于广播变量,我们也可以监控数据库中的变化,做到定时的重新广播新的数据表配置情况,另外我使用上述方式,在每天千万级的数据实时流统计中表现稳定,所以有相似问题的同学也可以进行尝试,有任何问题,欢迎随时骚扰沟通v
广告下我们项目:专注于游戏舆情的挖掘分析,欢迎大家来踩踩
参考文献
Spark Programming Guide2.1.0
Spark Programming Guide1.6.3
共享变量
How can I update a broadcast variable in spark streaming?
原文链接:https://www.qcloud.com/community/article/407582
Spark踩坑记:共享变量的更多相关文章
- Spark踩坑记——共享变量
[TOC] 前言 Spark踩坑记--初试 Spark踩坑记--数据库(Hbase+Mysql) Spark踩坑记--Spark Streaming+kafka应用及调优 在前面总结的几篇spark踩 ...
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark踩坑记——数据库(Hbase+Mysql)
[TOC] 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库,去统计或者改变一些值.最近一个实时消费者处理任务,在使用spark streami ...
- Spark踩坑记——从RDD看集群调度
[TOC] 前言 在Spark的使用中,性能的调优配置过程中,查阅了很多资料,之前自己总结过两篇小博文Spark踩坑记--初试和Spark踩坑记--数据库(Hbase+Mysql),第一篇概况的归纳了 ...
- [转]Spark 踩坑记:数据库(Hbase+Mysql)
https://cloud.tencent.com/developer/article/1004820 Spark 踩坑记:数据库(Hbase+Mysql) 前言 在使用Spark Streaming ...
- Spark踩坑记——数据库(Hbase+Mysql)转
转自:http://www.cnblogs.com/xlturing/p/spark.html 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库 ...
- Spark踩坑记:Spark Streaming+kafka应用及调优
前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark streaming从k ...
- Spark踩坑记——初试
[TOC] Spark简介 整体认识 Apache Spark是一个围绕速度.易用性和复杂分析构建的大数据处理框架.最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apach ...
- 【踩坑记】从HybridApp到ReactNative
前言 随着移动互联网的兴起,Webapp开始大行其道.大概在15年下半年的时候我接触到了HybridApp.因为当时还没毕业嘛,所以并不清楚自己未来的方向,所以就投入了HybridApp的怀抱. Hy ...
随机推荐
- C# 非模式窗体show()和模式窗体showdialog()的区别
对话框不是模式就是无模式的.模式对话框,在可以继续操作应用程序的其他部分之前,必须被关闭(隐藏或卸载).例如,如果一个对话框,在可以切换到其它窗 体或对话框之前要求先单击"确定"或 ...
- luoguP4696 [CEOI2011]Matching KMP+树状数组
可以非常轻易的将题意转化为有多少子串满足排名相同 注意到$KMP$算法只会在当前字符串的某尾添加和删除字符 因此,如果添加和删除后面的字符对于前面的字符没有影响时,我们可以用$KMP$来模糊匹配 对于 ...
- 20162325 金立清 S2 W11 C20
20162325 2017-2018-2 <程序设计与数据结构>第11周学习总结 教材关键概念摘要 在哈希方法中,元素保存在哈希表中,其在表中的位置由哈希函数确定. 两个元素或关键字映射到 ...
- SQL SERVER 2008 多边形问题的解决
报错内容: 在执行用户定义例程或聚合 "geometry" 期间出现 .NET Framework 错误: System.ArgumentException: 24144: 由于该 ...
- 协议栈中使用crc校验函数
CRC校验介绍:循环冗余校验码,原理是多项式除法 ZigBee协议栈:能够使zigbee节点相互之间组网,数据传输,数据获取,数据显示 思路以及步骤: 1.因为IAR的程序是用c写的,所以上网查找如何 ...
- Mysql的学习随笔day2
关于输入中文的问题,各种更改完utf8后仍然乱码. 最后找到一种可行的方法:在insert之前,输入 set names 'gbk' 约束保证数据的完整性和一致性.约束分为表级约束和列级约束,前者可以 ...
- SGU 403 Scientific Problem
403. Scientific Problem Time limit per test: 0.25 second(s)Memory limit: 65536 kilobytes input: stan ...
- Git_自定义Git
在安装Git一节中,我们已经配置了user.name和user.email,实际上,Git还有很多可配置项. 比如,让Git显示颜色,会让命令输出看起来更醒目: $ git config --glob ...
- PID DC/DC Converter Controller Using a PICmicro Microcontroller
http://www.microchip.com/stellent/idcplg?IdcService=SS_GET_PAGE&nodeId=1824&appnote=en011794 ...
- IntelliJ IDEA 学习(五)类注释和自定义方法注释
intellj idea的强大之处就不多说了,相信每个用过它的人都会体会到,但是我们经常会感觉他很复杂,尤其刚从eclipse转过来的童鞋,相信刚开始的那段经历都是不堪回首的 如何实现 ...