INNODB自增主键的一些问题 vs mysql获得自增字段下一个值
今天发现 批量插入下,自增主键不连续了。。。。。。。
InnoDB AUTO_INCREMENT Lock Modes
This section describes the behavior of AUTO_INCREMENT lock modes used to generate auto-increment values, and how each lock mode affects replication. Auto-increment lock modes are configured at startup using the innodb_autoinc_lock_mode configuration
来自
https://dev.mysql.com/doc/refman/5.7/en/innodb-auto-increment-handling.html
背景:
自增长是一个很常见的数据属性,在MySQL中大家都很愿意让自增长属性的字段当一个主键。特别是InnoDB,因为InnoDB的聚集索引的特性,使用自增长属性的字段当主键性能更好,这里要说明下自增主键需要注意的几个事项。
问题一:表锁
在MySQL5.1.22之前,InnoDB自增值是通过其本身的自增长计数器来获取值,该实现方式是通过表锁机制来完成的(AUTO-INC LOCKING)。锁不是在每次事务完成后释放,而是在完成对自增长值插入的SQL语句后释放,要等待其释放才能进行后续操作。比如说当表里有一个auto_increment字段的时候,innoDB会在内存里保存一个计数器用来记录auto_increment的值,当插入一个新行数据时,就会用一个表锁来锁住这个计数器,直到插入结束。如果大量的并发插入,表锁会引起SQL堵塞。
在5.1.22之后,InnoDB为了解决自增主键锁表的问题,引入了参数innodb_autoinc_lock_mode,该实现方式是通过轻量级互斥量的增长机制完成的。它是专门用来在使用auto_increment的情况下调整锁策略的,目前有三种选择:
插入类型说明:
INSERT-LIKE:指所有的插入语句,比如 INSERT、REPLACE、INSERT…SELECT、REPLACE…SELECT,LOAD DATA等
Simple inserts:指在插入前就能确定插入行数的语句,包括INSERT、REPLACE,不包含INSERT…ON DUPLICATE KEY UPDATE这类语句。
Bulk inserts:指在插入前不能确定得到插入行的语句。如INSERT…SELECT,REPLACE…SELECT,LOAD DATA.
Mixed-mode inserts:指其中一部分是自增长的,有一部分是确定的。
0:通过表锁的方式进行,也就是所有类型的insert都用AUTO-inc locking。
1:默认值,对于simple insert 自增长值的产生使用互斥量对内存中的计数器进行累加操作,对于bulk insert 则还是使用表锁的方式进行。
2:对所有的insert-like 自增长值的产生使用互斥量机制完成,性能最高,并发插入可能导致自增值不连续,可能会导致Statement 的 Replication 出现不一致,使用该模式,需要用 Row Replication的模式。
在mysql5.1.22之前,mysql的INSERT-LIKE语句会在执行整个语句的过程中使用一个AUTO-INC锁将表锁住,直到整个语句结束(而不是事务结束)。因此在使用INSERT…SELECT、INSERT…values(…),values(…)时,LOAD DATA等耗费时间较长的操作时,会将整个表锁住,而阻塞其他的insert-like,update等语句。推荐使用程序将这些语句分成多条语句,一一插入,减少单一时间的锁表时间。
解决:
通过参数innodb_autoinc_lock_mode =1/2解决,并用simple inserts 模式插入。
问题二:自增主键不连续
5.1.22后 默认:innodb_autoinc_lock_mode = 1
直接通过分析语句,获得要插入的数量,然后一次性分配足够的auto_increment id,只会将整个分配的过程锁住。

root@localhost : test 04:23:28>show variables like 'innodb_autoinc_lock_mode';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| innodb_autoinc_lock_mode | 1 |
+--------------------------+-------+
1 row in set (0.00 sec) root@localhost : test 04:23:31>create table tmp_auto_inc(id int auto_increment primary key,talkid int)engine = innodb default charset gbk;
Query OK, 0 rows affected (0.16 sec) root@localhost : test 04:23:35>insert into tmp_auto_inc(talkid) select talkId from talk_dialog limit 10;
Query OK, 10 rows affected (0.00 sec)
Records: 10 Duplicates: 0 Warnings: 0 root@localhost : test 04:23:39>show create table tmp_auto_inc\G;
*************************** 1. row ***************************
Table: tmp_auto_inc
Create Table: CREATE TABLE `tmp_auto_inc` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`talkid` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=16 DEFAULT CHARSET=gbk
1 row in set (0.00 sec)
插入10条记录,但表的AUTO_INCREMENT=16,再插入一条的时候,表的自增id已经是不连续了。
原因:
参数innodb_autoinc_lock_mode = 1时,每次会“预申请”多余的id(handler.cc:compute_next_insert_id),而insert执行完成后,会特别将这些预留的id空出,就是特意将预申请后的当前最大id回写到表中(dict0dict.c:dict_table_autoinc_update_if_greater)。
这个预留的策略是“不够时多申请几个”, 实际执行中是分步申请。至于申请几个,是由当时“已经插入了几条数据N”决定的。当auto_increment_offset=1时,预申请的个数是 N-1。
所以会发现:插入只有1行时,你看不到这个现象,并不预申请。而当有N>1行时,则需要。多申请的数目为N-1,因此执行后的自增值为:1+N+(N-1)。测试中为10行,则:1+10+9 =20,和 16不一致?原因是:当插入8行的时候,表的AUTO_INCREMENT已经是16了,所以插入10行时,id已经在第8行时预留了,所以直接使用,自增值仍为16。所以当插入8行的时候,多申请了7个id,即:9,10,11,12,13,14,15。按照例子中的方法插入8~15行,表的AUTO_INCREMENT始终是16
验证:
插入16行:猜测 预申请的id:1+16+(16-1)= 32,即:AUTO_INCREMENT=32
root@localhost : test 04:55:45>create table tmp_auto_inc(id int auto_increment primary key,talkid int)engine = innodb default charset gbk;
Query OK, 0 rows affected (0.17 sec) root@localhost : test 04:55:48>insert into tmp_auto_inc(talkid) select talkId from sns_talk_dialog limit 16;
Query OK, 16 rows affected (0.00 sec)
Records: 16 Duplicates: 0 Warnings: 0 root@localhost : test 04:55:50>show create table tmp_auto_inc\G;
*************************** 1. row ***************************
Table: tmp_auto_inc
Create Table: CREATE TABLE `tmp_auto_inc` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`talkid` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=32 DEFAULT CHARSET=gbk
1 row in set (0.00 sec)
和猜测的一样,自增id到了32。所以当插入16行的时候,多申请了17,18,19...,31 。
所以导致ID不连续的原因是因为innodb_autoinc_lock_mode = 1时,会多申请id。好处是:一次性分配足够的auto_increment id,只会将整个分配的过程锁住。
5.1.22前 默认:innodb_autoinc_lock_mode = 0
root@localhost : test 04:25:12>show variables like 'innodb_autoinc_lock_mode';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| innodb_autoinc_lock_mode | 0 |
+--------------------------+-------+
1 row in set (0.00 sec) root@localhost : test 04:25:15>create table tmp_auto_inc(id int auto_increment primary key,talkid int)engine = innodb default charset gbk;
Query OK, 0 rows affected (0.17 sec) root@localhost : test 04:25:17>insert into tmp_auto_inc(talkid) select talkId from talk_dialog limit 10;
Query OK, 10 rows affected (0.00 sec)
Records: 10 Duplicates: 0 Warnings: 0 root@localhost : test 04:25:21>show create table tmp_auto_inc\G;
*************************** 1. row ***************************
Table: tmp_auto_inc
Create Table: CREATE TABLE `tmp_auto_inc` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`talkid` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=gbk
1 row in set (0.00 sec)
插入10条记录,但表的AUTO_INCREMENT=11,再插入一条的时候,表的自增id还是连续的。
innodb_autoinc_lock_mode = 2 和 innodb_autoinc_lock_mode = 1 的测试情况一样。但该模式下是来一个分配一个,而不会锁表,只会锁住分配id的过程,和1的区别在于,不会预分配多个,这种方式并发性最高。但是在replication中当binlog_format为statement-based时存在问题
解决:
尽量让主键ID没有业务意义,或则使用simple inserts模式插入。
结论:
当innodb_autoinc_lock_mode为0时候, 自增id都会连续,但是会出现表锁的情况,解决该问题可以把innodb_autoinc_lock_mode 设置为1,甚至是2。会提高性能,但是会在一定的条件下导致自增id不连续。
总结:
通过上面2个问题的说明,自增主键会产生表锁,从而引发问题;自增主键有业务意义,不连续的主键导致主从主键不一致到出现问题。对于simple inserts 的插入类型,上面的问题都不会出现。对于Bulk inserts的插入类型,会出现上述的问题。
更多信息:
http://dinglin.iteye.com/blog/1279536
http://hi.baidu.com/thinkinginlamp/item/a0320c82233c6c2a100ef3d0
http://dev.mysql.com/doc/refman/5.5/en/innodb-auto-increment-handling.html
http://blog.chinaunix.net/uid-9950859-id-181376.html
mysql获得自增字段下一个值
作者:@keenleung
本文为作者原创,转载请注明出处:http://www.cnblogs.com/KeenLeung/p/3864614.html
目录
初次研究:
表:
sql:
show table status from carsale_db LIKE 'tb_car'
结果:

想办法取得这其中的值....
在Internet上找到这个资料:
MySQL中可以使用 show table status 查看表的状态,但是不能像select 语句选出结果那样做结果过滤。
有没有办法像select语句那样过滤呢,答案是有的,就是从information_schema库的tables表中查询。
如下是模仿show table status 的SQL:
SELECT table_name,Engine,Version,Row_format,table_rows,Avg_row_length,
Data_length,Max_data_length,Index_length,Data_free,Auto_increment,
Create_time,Update_time,Check_time,table_collation,Checksum,
Create_options,table_comment
FROM information_schema.tables
WHERE Table_Schema='MyDataBaseName';
注意替换MyDataBaseName的名称为自己的库名称,这样就可以方便在Where部分添加各种条件过滤了。
(From URL:http://jishu.zol.com.cn/3689.html)
于是,复制->粘贴,修改所需字段:
SELECT table_name,Auto_increment,Engine,Version,Row_format,table_rows,Avg_row_length,
Data_length,Max_data_length,Index_length,Data_free,
Create_time,Update_time,Check_time,table_collation,Checksum,
Create_options,table_comment
FROM information_schema.`TABLES`
WHERE Table_Schema='carsale_db'
结果:
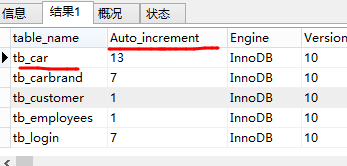
感觉表太多了,修改:
SELECT table_name,Auto_increment,Engine,Version,Row_format,table_rows,Avg_row_length,
Data_length,Max_data_length,Index_length,Data_free,
Create_time,Update_time,Check_time,table_collation,Checksum,
Create_options,table_comment
FROM information_schema.`TABLES`
WHERE Table_Schema='carsale_db'
AND table_name = 'tb_car'
结果:
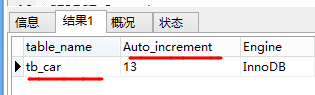
排除不需要的字段:
SELECT Auto_increment
FROM information_schema.`TABLES`
WHERE Table_Schema='carsale_db'
AND table_name = 'tb_car'
结果:
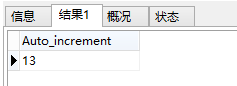
OK,这就是我想要的结果.....
INNODB自增主键的一些问题 vs mysql获得自增字段下一个值的更多相关文章
- mysql如何让有数据的表的自增主键重新设置从1开始连续自增
项目开发中,有些固定数据在数据表中,主键是从1自增的,有时候我们会删除一些数据, 这种情况下,主键就会不连续.如何恢复到像第一次插入数据一样主键从1开始连续增长, 这里我找到一种解决方法: 如上面一张 ...
- mysql获得自增字段下一个值
初次研究: 表: sql: show table status from carsale_db LIKE 'tb_car' 结果: 想办法取得这其中的值.... 在Internet上找到这个资料: M ...
- MySQL 中的自增主键
MySQL 的主键可以是自增的,那么如果在断电重启后新增的值还会延续断电前的自增值吗?自增值默认为1,那么可不可以改变呢?下面就说一下 MySQL 的自增值. 特点 保存策略 1.如果存储引擎是 My ...
- java面试一日一题:mysql中的自增主键
问题:请讲下mysql中的自增主键 分析:该问题主要考察对mysql中自增主键的掌握,使用场景及如何设置 回答要点: 主要从以下几点去考虑 1.什么自增主键 2.使用场景是什么: 3.innodb_a ...
- MySQL8自增主键变化
MySQL8自增主键变化 醉后不知天在水,满船清梦压星河. 一.简述 MySQL版本从5直接大跃进到8,相信MySQL8一定会有很多令人意想不到的改进,如果不想只会CRUD可以看看. 比如系统表引擎的 ...
- MYSQL获取自增主键【4种方法】
通常我们在应用中对mysql执行了insert操作后,需要获取插入记录的自增主键.本文将介绍java环境下的4种方法获取insert后的记录主键auto_increment的值: 通过JDBC2.0提 ...
- Mybatis批量插入返回自增主键(转)
我们都知道Mybatis在插入单条数据的时候有两种方式返回自增主键: 1.对于支持生成自增主键的数据库:useGenerateKeys和keyProperty. 2.不支持生成自增主键的数据库:< ...
- mybatis由浅入深day01_4.7根据用户名称模糊查询用户信息_4.8添加用户((非)自增主键返回)
4.7 根据用户名称模糊查询用户信息 4.7.1 映射文件 使用User.xml,添加根据用户名称模糊查询用户信息的sql语句. 4.7.2 程序代码 控制台: 4.8 添加用户 4.8.1 映射文件 ...
- MYSQL获取自增主键【4种方法】(转)
转自:http://blog.csdn.net/ultrani/article/details/9351573 作者已经写的非常好了,我不废话了,直接转载收藏: 通常我们在应用中对mysql执行了in ...
随机推荐
- mysql 主从复制原理(转)
本文转自https://blog.csdn.net/php_younger/article/details/59673879 mysql 主从复制原理 主从形式 mysql主从复制 灵活 一主一从 ...
- mormot当作内存数据库(缓存)使用
mormot当作内存数据库(缓存)使用 mormot的TSQLRestStorageInMemory可以作为内存数据库来使用. 上图是在笔者4代I5笔记本上做的测试,增加10万记录,耗时:562毫秒. ...
- SWT 全接触
http://www.ibm.com/developerworks/cn/opensource/os-swt/index.html 1.SWT简介 SWT-"Standard Widget ...
- R语言缺点
R的优点:免费,开源,体积小.缺点:对大文本处理差,另外一个也在于开源,package如果出错,烦死你.当你跑比较大的simulation,对效率有要求的时候,有时还是不得不用C,这可能是10小时和1 ...
- 再有人问你synchronized是什么,就把这篇文章发给他
在再有人问你Java内存模型是什么,就把这篇文章发给他.中我们曾经介绍过,Java语言为了解决并发编程中存在的原子性.可见性和有序性问题,提供了一系列和并发处理相关的关键字,比如synchronize ...
- GUI程序设计2
8. 按钮(JButton)使用示例 例14. 按钮使用示例. package GUI; import java.awt.BorderLayout; import java.awt.Container ...
- 集合 数组 定义 转换 遍历 Arrays API MD
Markdown版本笔记 我的GitHub首页 我的博客 我的微信 我的邮箱 MyAndroidBlogs baiqiantao baiqiantao bqt20094 baiqiantao@sina ...
- activity 保存数据
activity 保存数据对android的商业项目十分的重要,譬如你在发微博的时候,突然来了一个电话,你洋洋洒洒写了100个字,你不能保存的话,你岂不要卖要骂娘. 那activity究竟是保存数据的 ...
- 应用程序无法正常启动0xc000007b解决
可能原因: 1.电脑没有安装DirectX9或者DirectX 9.0 组件损坏; 2.电脑没有安装Microsoft Visual C++ 3.电脑上没有安装.net 解决方案: 1/2.下载Dir ...
- Configuring Time in Windows 7 and Win 200
http://www.windowsnetworking.com/articles-tutorials/windows-7/Configuring-Time-Windows-7-Win-2008-R2 ...