hbase-列存储动态数据库
1) HBase是什么?
HBase是建立在Hadoop文件系统之上的分布式面向列的数据库。它是一个开源项目,是横向扩展的。
HBase是一个数据模型,类似于谷歌的大表设计,可以提供快速随机访问海量结构化数据。它利用了Hadoop的文件系统(HDFS)提供的容错能力。
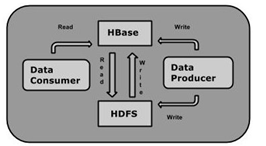
它是Hadoop的生态系统,提供对数据的随机实时读/写访问,是Hadoop文件系统的一部分。
人们可以直接或通过HBase的存储HDFS数据。使用HBase在HDFS读取消费/随机访问数据。 HBase在Hadoop的文件系统之上,并提供了读写访问。
2) HBase的存储机制
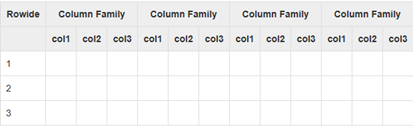
HBase是一个面向列的数据库,在表中它由行排序。表模式定义只能列族,也就是键值对。一个表有多个列族以及每一个列族可以有任意数量的列。后续列的值连续地存储在磁盘上。表中的每个单元格值都具有时间戳。
总之,在一个HBase:表是行的集合à行是列族的集合à列族是列的集合à列是键值对的集合,如图:
3) Hbase的特点
- 建立在HDFS之上,面向列的针对结构化数据的可伸缩、高可靠、高性能、分布式列存储的动态模式数据库,列式数据库(nosql)专门解决hadoop不擅长的工作。
- 采用BigTable的数据模型。增强的稀疏排序映射表(Key/Value),其中“键”是由行关键字、列关键字、时间截构成。
- 提供对大规模数据的随机、实时读写访问功能,其保存的数据可通过MapReduce处理。
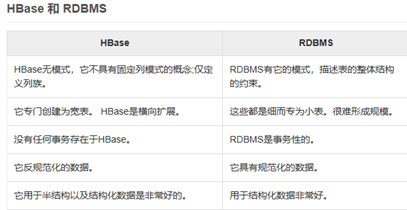
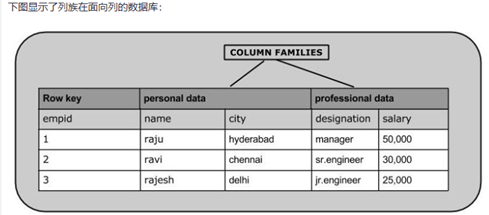
4) 行数据库与列数据库的区别

5) hbase表特点:
- 表比较大,一个表有数十亿行,上百万列;
- 无模式:每行都有一个可排序的主键和任意多的列,列可以根据需要冬天的增加,同一张表中的行也已有截然不同的列;
- 稀疏:空值列并不占用存储空间,列独立检索;
- 数据多版本:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入时间戳;
- 数据类型单一:数据都是字符串,没有类型
6) 存储核心—Hstore
Hstore分为menstore和storefiles两部分。
用户写入的数据首先会放入MemStore,当MemStore满了以后会Flush成一个StoreFile(底层实现是HFile),当StoreFile文件数量增长到一定阈值,会触发Compact合并操作,将多个StoreFiles合并成一个StoreFile,合并过程中会进行版本合并和数据删除
HBase其实只有增加数据,所有的更新和删除操作都是在后续的compact过程中进行的,这使得用户的写操作只要进入内存中就可以立即返回,保证了HBase I/O的高性能架构。
7) Hbase架构
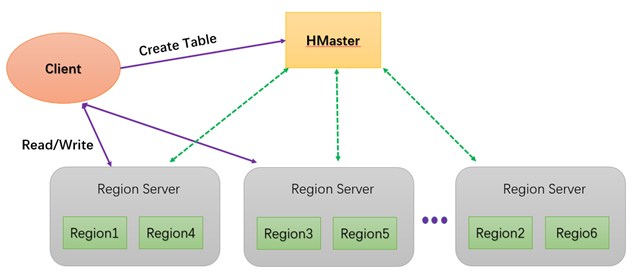
一个HMaster(管理服务器)控制多个Region Server(数据服务器);
- HMater负责表的创建、删除、维护以及Region的分配和负载均衡;
- Region Server负责管理维护Region以及响应读写请求;
- 客户端与HMaster进行有关表的元数据操作,之后直接读写Region servers。
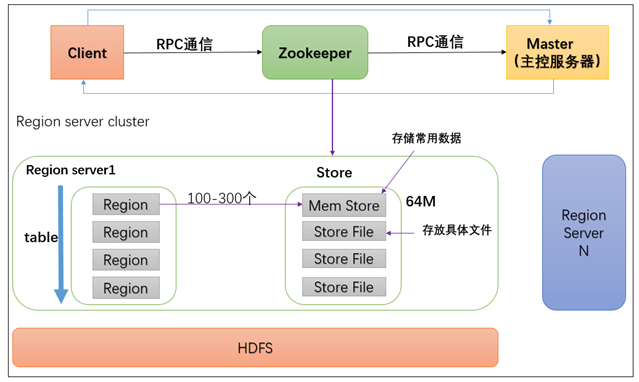
Master职责:
1. 为regionserver分配region;
2. 负责regionserver的负载均衡;
3. 垃圾文件回收;
4. 处理schema请求
Zookeeper职责:
- 保证集群只有一个Master;
- 监控Region Server状态,实时通知Master;
- Hbase目录入口地址;
- Hbase的Schema信息
Region职责:
- 对数据的读写支持;
- 对region管理的支持;
- Hbase目录入口地址;
- Hbase的Schema信息
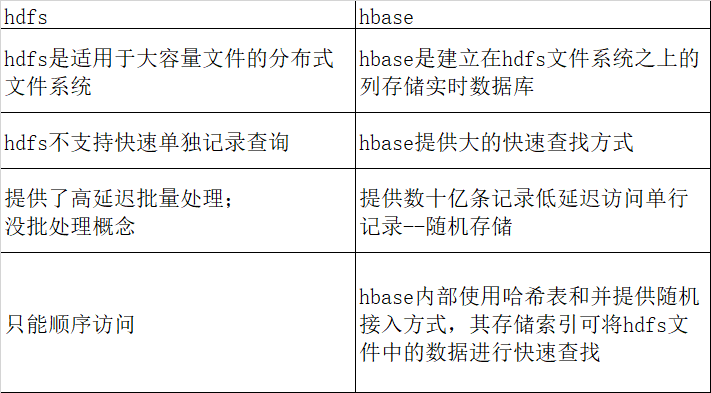
8) HBase 和 HDFS关系
9) hive与hbase区别
相同点:都是架构在hadoop之上,都是用hadoop作为底层存储
不同点:
Hive:
- 是批处理系统,目的是检索MapReduce jobs的编写工作;
- 是纯逻辑表并且是全表扫描,本身不存储和计算数据,完全依赖HDFS和MapReduce;
- 时效性低
Hbase:
- 是实时操作系统,目的是弥补hadoop的缺陷项目;
- 是物理表,采用列存储索引数据或实时数据,提供超大的内存hash表;
- 高时效性。
hbase-列存储动态数据库的更多相关文章
- HBase底层存储原理——我靠,和cassandra本质上没有区别啊!都是kv 列存储,只是一个是p2p另一个是集中式而已!
理解HBase(一个开源的Google的BigTable实际应用)最大的困难是HBase的数据结构概念究竟是什么?首先HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库.另一个不 ...
- hbase非结构化数据库与结构化数据库比较
目的:了解hbase与支持海量数据查询的特性以及实现方式 传统关系型数据库特点及局限 传统数据库事务性特别强,要求数据完整性及安全性,造成系统可用性以及伸缩性大打折扣.对于高并发的访问量,数据库性能不 ...
- HBase底层存储原理
HBase底层存储原理——我靠,和cassandra本质上没有区别啊!都是kv 列存储,只是一个是p2p另一个是集中式而已! 首先HBase不同于一般的关系数据库, 它是一个适合于非结构化数据存储的数 ...
- 【HBase】与关系型数据库区别、行式/列式存储
[HBase]与关系型数据库区别 1.本质区别 mysql:关系型数据库,行式存储,ACID,SQL,只能存储结构化数据 事务的原子性(Atomicity):是指一个事务要么全部执行,要么不执行,也就 ...
- OpenTSDB介绍——基于Hbase的分布式的,可伸缩的时间序列数据库,而Hbase本质是列存储
原文链接:http://www.jianshu.com/p/0bafd0168647 OpenTSDB介绍 1.1.OpenTSDB是什么?主要用途是什么? 官方文档这样描述:OpenTSDB is ...
- HBase与列存储
传统的行存储和(HBase)列存储的区别 1.为什么要按列存储 列式存储(Columnar or column-based)是相对于传统关系型数据库的行式存储(Row-basedstorage)来说的 ...
- HBase:分布式列式NoSQL数据库
传统的ACID数据库,可扩展性上受到了巨大的挑战.而HBase这类系统,兼具可扩展性的同时,也提出了类SQL的接口. HBase架构组成 HBase采用Master/Slave架构搭建集群,它隶属于H ...
- 一些开源搜索引擎实现——倒排使用原始文件,列存储Hbase,KV store如levelDB、mongoDB、redis,以及SQL的,如sqlite或者xxSQL
本文说明:除开ES,Solr,sphinx系列的其他开源搜索引擎汇总于此. A search engine based on Node.js and LevelDB A persistent, n ...
- 时间序列数据库——索引用ES、聚合分析时加载数据用什么?docvalues的列存储貌似更优优势一些
加载 如何利用索引和主存储,是一种两难的选择. 选择不使用索引,只使用主存储:除非查询的字段就是主存储的排序字段,否则就需要顺序扫描整个主存储. 选择使用索引,然后用找到的row id去主存储加载数据 ...
随机推荐
- Struts2中 Path (getContextPath与basePath)
struts2中的路径问题是根据action的路径而不是jsp路径来确定,所以尽量不要使用相对路径. 虽然可以用redirect方式解决,但redirect方式并非必要.解决办法非常简单,统一使用绝对 ...
- java jvm概述及工作过程中的内存管理
java jvm 有分层的思想. java类..java文件,源文件,源代码,源程序 编译器不能把源代码直接编译成0101,除非是java语言写的操作系统. windows认识的可执行文件 ...
- Angularjs 表格插件的使用
对于相关的table组件可以使用:UI Grid (ng-grid),ng-table,smart table,Angular-Datatables,tablelite,kendo-ui中的grid. ...
- JavaScript Web 应用最佳实践分析
[编者按]本文作者为 Mathias Schäfer,旨在回顾在客户端大量使用JavaScript 的最佳 Web应用实践.文章系国内 ITOM 管理平台 OneAPM 编译呈现. 对笔者来说,Jav ...
- statsmodels中的summary解读(以linear regression模型为例)
https://datatofish.com/statsmodels-linear-regression/ https://blog.datarobot.com/ordinary-least-squa ...
- python之线程、进程
线程语法 class Thread(_Verbose): """A class that represents a thread of control. This cla ...
- Oracle GoldenGate DDL 详细说明 使用手册(较早资料)
一. 概述 DDL 相关的参数包括:DDL.DDLERROR.DDLOPTIONS.DDLSUBST.DDLTABLE.GGSCHEMA. PURGEDDLHISTORY.PURGEMARKERHIS ...
- (matlab)plot画图的颜色线型(转)
http://wenku.baidu.com/link?url=SVVMVH8QlDIu2hVKDtoBYs6l0CnQvFnFHJJ9yexmYVKQqhz47qIr7aK7LOf8nN0qNdy8 ...
- Asp.net Core 2.0+EntityFrameWorkCore 2.0添加数据迁移
Asp.net Core 由于依赖注入的广泛使用,配置数据迁移,与Asp.net大不相同,本篇介绍一下Asp.net Core添加数据迁移的过程 添加Nuget包 Install-Package Mi ...
- if 里面嵌套一个if&else (我自己又细分了别的条件,加了elif)
场景: 一个陌生人敲门..... gender = input("你是男的是女的?") if gender == "女": print("请进&quo ...