(转载)MySQL数据库的几种常见高可用方案
- 如果数据库发生了宕机或者意外中断等故障,能尽快恢复数据库的可用性,尽可能的减少停机时间,保证业务不会因为数据库的故障而中断。
- 用作备份、只读副本等功能的非主节点的数据应该和主节点的数据实时或者最终保持一致。
- 当业务发生数据库切换时,切换前后的数据库内容应当一致,不会因为数据缺失或者数据不一致而影响业务。
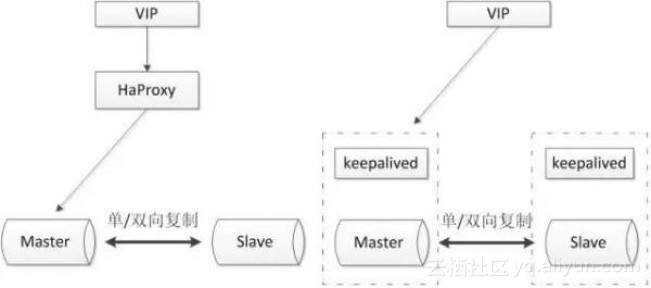
- 架构比较简单,使用原生半同步复制作为数据同步的依据;
- 双节点,没有主机宕机后的选主问题,直接切换即可;
- 双节点,需求资源少,部署简单;
- 完全依赖于半同步复制,如果半同步复制退化为异步复制,数据一致性无法得到保证;
- 需要额外考虑haproxy、keepalived的高可用机制。
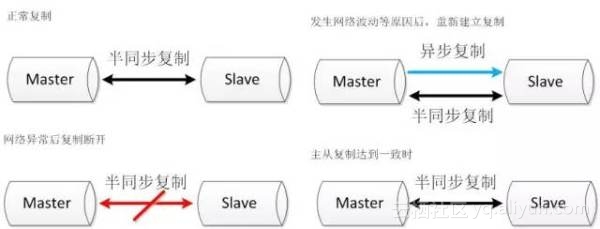
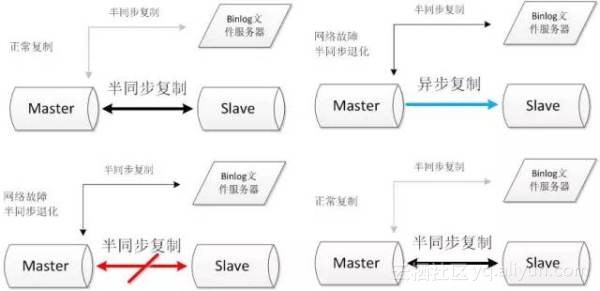
- 双节点,需求资源少,部署简单;
- 架构简单,没有选主的问题,直接切换即可;
- 相比于原生复制,优化后的半同步复制更能保证数据的一致性。
- 需要修改内核源码或者使用mysql通信协议。需要对源码有一定的了解,并能做一定程度的二次开发。
- 依旧依赖于半同步复制,没有从根本上解决数据一致性问题。
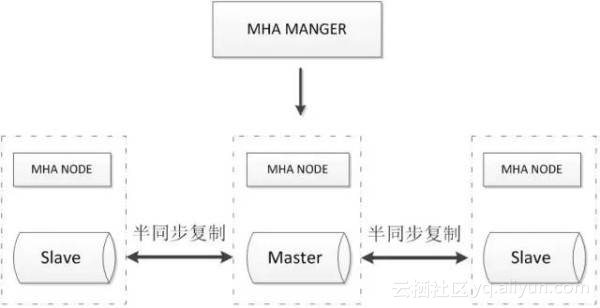
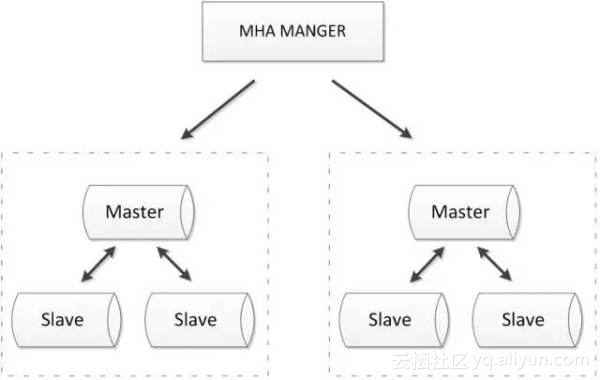
- 可以进行故障的自动检测和转移;
- 可扩展性较好,可以根据需要扩展MySQL的节点数量和结构;
- 相比于双节点的MySQL复制,三节点/多节点的MySQL发生不可用的概率更低
- 至少需要三节点,相对于双节点需要更多的资源;
- 逻辑较为复杂,发生故障后排查问题,定位问题更加困难;
- 数据一致性仍然靠原生半同步复制保证,仍然存在数据不一致的风险;
- 可能因为网络分区发生脑裂现象;
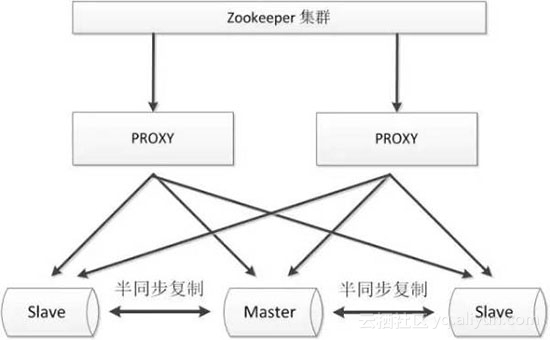
- 较好的保证了整个系统的高可用性,包括proxy、MySQL;
- 扩展性较好,可以扩展为大规模集群;
- 数据一致性仍然依赖于原生的mysql半同步复制;
- 引入zk,整个系统的逻辑变得更加复杂;
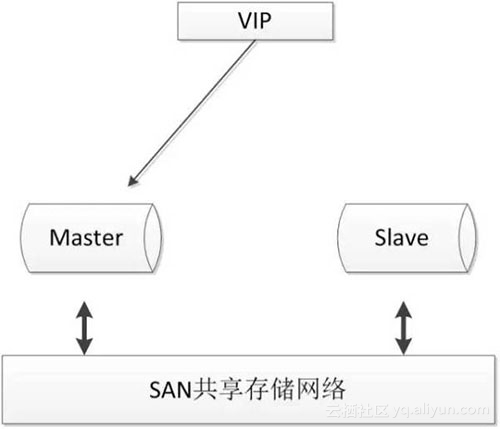
- 两节点即可,部署简单,切换逻辑简单;
- 很好的保证数据的强一致性;
- 不会因为MySQL的逻辑错误发生数据不一致的情况;
- 需要考虑共享存储的高可用;
- 价格昂贵;
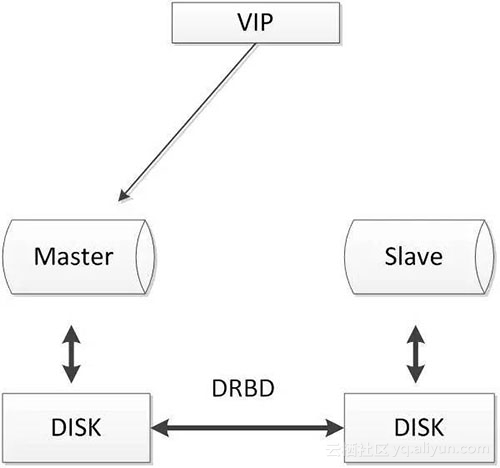
- 两节点即可,部署简单,切换逻辑简单;
- 相比于SAN储存网络,价格低廉;
- 保证数据的强一致性;
- 对io性能影响较大;
- 从库不提供读操作;
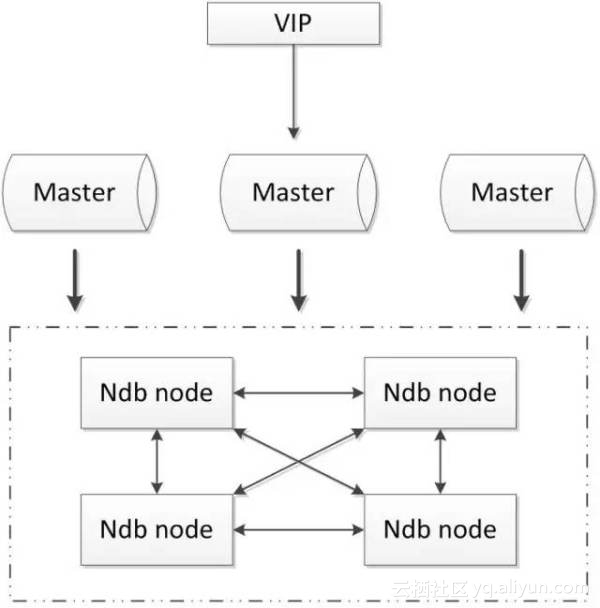
- 全部使用官方组件,不依赖于第三方软件;
- 可以实现数据的强一致性;
- 国内使用的较少;
- 配置较复杂,需要使用NDB储存引擎,与MySQL常规引擎存在一定差异;
- 至少三节点;
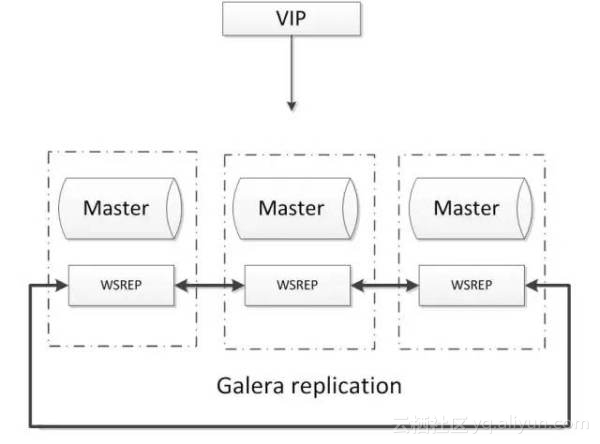
- 多主写入,无延迟复制,能保证数据强一致性;
- 有成熟的社区,有互联网公司在大规模的使用;
- 自动故障转移,自动添加、剔除节点;
- 需要为原生MySQL节点打wsrep补丁
- 只支持innodb储存引擎
- 至少三节点;
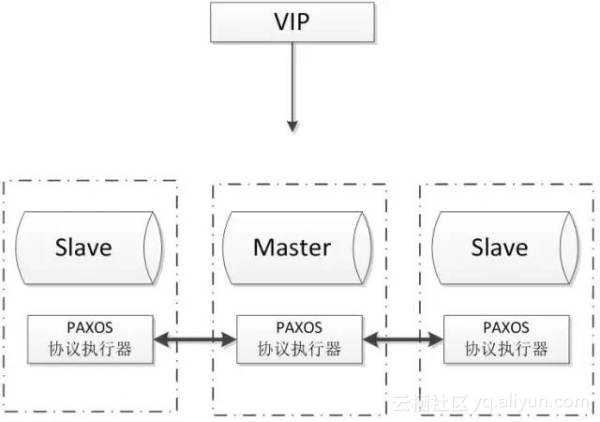
- 多主写入,无延迟复制,能保证数据强一致性;
- 有成熟理论基础;
- 自动故障转移,自动添加、剔除节点;
- 只支持innodb储存引擎
- 至少三节点;
(转载)MySQL数据库的几种常见高可用方案的更多相关文章
- [转载] 单表60亿记录等大数据场景的MySQL优化和运维之道 | 高可用架构
原文: http://mp.weixin.qq.com/s?__biz=MzAwMDU1MTE1OQ==&mid=209406532&idx=1&sn=2e9b0cc02bdd ...
- 【转】单表60亿记录等大数据场景的MySQL优化和运维之道 | 高可用架构
此文是根据杨尚刚在[QCON高可用架构群]中,针对MySQL在单表海量记录等场景下,业界广泛关注的MySQL问题的经验分享整理而成,转发请注明出处. 杨尚刚,美图公司数据库高级DBA,负责美图后端数据 ...
- Mysql+Keepalived双主热备高可用操作记录
我们通常说的双机热备是指两台机器都在运行,但并不是两台机器都同时在提供服务.当提供服务的一台出现故障的时候,另外一台会马上自动接管并且提供服务,而且切换的时间非常短.MySQL双主复制,即互为Mast ...
- 单表60亿记录等大数据场景的MySQL优化和运维之道 | 高可用架构
015-08-09 杨尚刚 高可用架构 此文是根据杨尚刚在[QCON高可用架构群]中,针对MySQL在单表海量记录等场景下,业界广泛关注的MySQL问题的经验分享整理而成,转发请注明出处. 杨尚刚,美 ...
- [转]MYSQL高可用方案探究(总结)
前言 http://blog.chinaunix.net/uid-20639775-id-3337432.htmlLvs+Keepalived+Mysql单点写入主主同步高可用方案 http://bl ...
- 五大常见的MySQL高可用方案
1. 概述 我们在考虑MySQL数据库的高可用的架构时,主要要考虑如下几方面: 1.1 如果数据库发生了宕机或者意外中断等故障,能尽快恢复数据库的可用性,尽可能的减少停机时间,保证业务不会因为数据 ...
- [转载] MySQL高可用方案选型参考
原文: http://imysql.com/2015/09/14/solutions-of-mysql-ha.shtml?hmsr=toutiao.io&utm_medium=toutiao. ...
- MYSQL数据库高可用方案探究
MySQL作为最关键的应用数据存储中心,如何保证MySQL服务的可靠性和持续性,是我们不得不细致考虑的一个问题.当master宕机的时候,我们如何保证数据尽可能的不丢失,如何保证快速的获知master ...
- 五大常见的MySQL高可用方案【转】
1. 概述 我们在考虑MySQL数据库的高可用的架构时,主要要考虑如下几方面: 如果数据库发生了宕机或者意外中断等故障,能尽快恢复数据库的可用性,尽可能的减少停机时间,保证业务不会因为数据库的故障而中 ...
随机推荐
- 用Micro:bit播放生日快乐歌
Micro:bit自带一个有趣的功能就是可以生成音乐播放,今天做一个简单实用的案例,用Micro:bit播放生日快乐歌. 算法: 按下按键A,显示生日快乐 播放D 播放D 播放E 播放D 播放G 播放 ...
- 简单字典实现(KV问题)
搜索二叉树基本概念请看上篇博客 这两个问题都是典型的K(key)V(value)问题,我们用KV算法解决. 判断一个单词是否拼写正确:假设把所有单词都按照搜索树的性质插入到搜索二叉树中,我们判断一个单 ...
- UNITY_资源路径与加载外部文件
UNITY_资源路径与加载外部文件 https://www.tuicool.com/articles/qMNnmm6https://blog.csdn.net/appppppen/article/de ...
- IP地址相关知识
IP地址基本概念 ...
- LimeSDR在windows下使用Gqrx来接收FM广播
本文内容.开发板及配件仅限用于学校或科研院所开展科研实验! 淘宝店铺名称:开源SDR实验室 LimeSDR链接:https://item.taobao.com/item.htm?spm=a230r.1 ...
- 【Docker】第三篇 Docker容器管理
一.Docker容器概述: 简单理解容器是镜像的一个实例. 镜像是静态的只读文件,而容器的运行需要可写文件层. 二.创建容器 [root@web130 ~]# docker create -it ub ...
- Spring的bean创建详解
IoC容器,又名控制反转,全称为Inverse of Control,其是Spring最为核心的一个组件,其他的组件如AOP,Spring事务等都是直接或间接的依赖于IoC容器的.本文主 ...
- BugPhobia开发篇章:Scurm Meeting-更新至0x02
0x01 :目录与摘要 If you weeped for the missing sunset, you would miss all the shining stars 索引 提纲 整理与更新记录 ...
- Scrum Meeting 11.10
成员 今日任务 明日计划 用时 徐越 调试前端代码 协助重构UI,完善前端逻辑 2h 赵庶宏 调出不能显示回答列表的bug,是后端数据库建库问题 与前一组进行数据库统一 3h 薄霖 UI代码 ...
- sprint站立会议
索引卡: 工作认领: 时间 ...