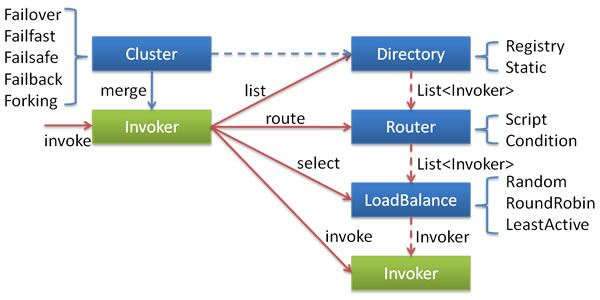
dubbo源码分析- 集群容错之Cluster(一)
1、集群容错的配置项
- failover - 失败自动切换,当出现失败,重试其他服务器(缺省),通常用于读操作,但重试会带来更长的延时。
- failfast - 快速失效,只发起一次调用,失败立即报错。通常用于非幂等性写操作,比如说新增记录
- failsafe - 失败安全,出现异常时,直接忽略,通常用于写入审计日志等操作
- failback - 失败自动恢复,后台记录失败请求,定时重发,通常用于消息通知操作
- forking - 并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多的服务器资源。
如果没有设置集群的cluster,则默认值为:failover;在cluster默认为failover时如果没有设置retries的值,则默认使用default.retries+1 = 0+1,即重试1次,如果设置了retries的值,则使用配置的值(比如:retries=2则重试2次)。
如果dubbo的provider所提供的服务中涉及到数据库操作,最好使用failfast,避免幂等操作抛出异常,或者使用默认cluster时可能导致的数据重试插入多条等情况。
@SuppressWarnings({"unchecked", "rawtypes"})
public Result doInvoke(Invocation invocation, final List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
List<Invoker<T>> copyinvokers = invokers;
checkInvokers(copyinvokers, invocation);
int len = getUrl().getMethodParameter(invocation.getMethodName(), Constants.RETRIES_KEY, Constants.DEFAULT_RETRIES) + 1;
if (len <= 0) {
len = 1;
}
// retry loop.
RpcException le = null; // last exception.
List<Invoker<T>> invoked = new ArrayList<Invoker<T>>(copyinvokers.size()); // invoked invokers.
Set<String> providers = new HashSet<String>(len);
for (int i = 0; i < len; i++) {
//Reselect before retry to avoid a change of candidate `invokers`.
//NOTE: if `invokers` changed, then `invoked` also lose accuracy.
if (i > 0) {
checkWhetherDestroyed();
copyinvokers = list(invocation);
// check again
checkInvokers(copyinvokers, invocation);
}
Invoker<T> invoker = select(loadbalance, invocation, copyinvokers, invoked);
invoked.add(invoker);
RpcContext.getContext().setInvokers((List) invoked);
try {
Result result = invoker.invoke(invocation);
if (le != null && logger.isWarnEnabled()) {
logger.warn("Although retry the method " + invocation.getMethodName()
+ " in the service " + getInterface().getName()
+ " was successful by the provider " + invoker.getUrl().getAddress()
+ ", but there have been failed providers " + providers
+ " (" + providers.size() + "/" + copyinvokers.size()
+ ") from the registry " + directory.getUrl().getAddress()
+ " on the consumer " + NetUtils.getLocalHost()
+ " using the dubbo version " + Version.getVersion() + ". Last error is: "
+ le.getMessage(), le);
}
return result;
} catch (RpcException e) {
if (e.isBiz()) { // biz exception.
throw e;
}
le = e;
} catch (Throwable e) {
le = new RpcException(e.getMessage(), e);
} finally {
providers.add(invoker.getUrl().getAddress());
}
}
throw new RpcException(le != null ? le.getCode() : 0, "Failed to invoke the method "
+ invocation.getMethodName() + " in the service " + getInterface().getName()
+ ". Tried " + len + " times of the providers " + providers
+ " (" + providers.size() + "/" + copyinvokers.size()
+ ") from the registry " + directory.getUrl().getAddress()
+ " on the consumer " + NetUtils.getLocalHost() + " using the dubbo version "
+ Version.getVersion() + ". Last error is: "
+ (le != null ? le.getMessage() : ""), le != null && le.getCause() != null ? le.getCause() : le);
}
2、集群容错的配置
- failover
<!-- Provider side -->
<dubbo:service retries="2" /> <!-- Consumer side -->
<dubbo:reference retries="2" /> <!-- Consumer side,Method -->
<dubbo:reference>
<dubbo:method name="findFoo" retries="2" />
</dubbo:reference>
- failfast
<!-- Provider side -->
<dubbo:service cluster="failfast"/> <!-- Consumer side -->
<dubbo:reference cluster="failfast"/>
- failsafe
<!-- Provider side -->
<dubbo:service cluster="failsafe"/> <!-- Consumer side -->
<dubbo:reference cluster="failsafe"/>
- failback
<!-- Provider side -->
<dubbo:service cluster="failback"/> <!-- Consumer side -->
<dubbo:reference cluster="failback"/>
- forking
<!-- Provider side -->
<dubbo:service cluster="forking"/> <!-- Consumer side -->
<dubbo:reference cluster="forking"/>
dubbo源码分析- 集群容错之Cluster(一)的更多相关文章
- Dubbo 源码分析 - 集群容错之 Cluster
1.简介 为了避免单点故障,现在的应用至少会部署在两台服务器上.对于一些负载比较高的服务,会部署更多台服务器.这样,同一环境下的服务提供者数量会大于1.对于服务消费者来说,同一环境下出现了多个服务提供 ...
- Dubbo 源码分析 - 集群容错之 LoadBalance
1.简介 LoadBalance 中文意思为负载均衡,它的职责是将网络请求,或者其他形式的负载"均摊"到不同的机器上.避免集群中部分服务器压力过大,而另一些服务器比较空闲的情况.通 ...
- Dubbo 源码分析 - 集群容错之 Router
1. 简介 上一篇文章分析了集群容错的第一部分 -- 服务目录 Directory.服务目录在刷新 Invoker 列表的过程中,会通过 Router 进行服务路由.上一篇文章关于服务路由相关逻辑没有 ...
- Dubbo 源码分析 - 集群容错之 Directory
1. 简介 前面文章分析了服务的导出与引用过程,从本篇文章开始,我将开始分析 Dubbo 集群容错方面的源码.这部分源码包含四个部分,分别是服务目录 Directory.服务路由 Router.集群 ...
- Dubbo源码(七) - 集群
前言 本文基于Dubbo2.6.x版本,中文注释版源码已上传github:xiaoguyu/dubbo 集群(cluster)就是一组计算机,它们作为一个总体向用户提供一组网络资源.这些单个的计算机系 ...
- Dubbo源码学习--集群负载均衡算法的实现
相关文章: Dubbo源码学习文章目录 前言 Dubbo 的定位是分布式服务框架,为了避免单点压力过大,服务的提供者通常部署多台,如何从服务提供者集群中选取一个进行调用, 就依赖Dubbo的负载均衡策 ...
- Dubbo 源码分析 - 服务调用过程
注: 本系列文章已捐赠给 Dubbo 社区,你也可以在 Dubbo 官方文档中阅读本系列文章. 1. 简介 在前面的文章中,我们分析了 Dubbo SPI.服务导出与引入.以及集群容错方面的代码.经过 ...
- dubbo服务引用与集群容错
服务引用无非就是做了两件事 将spring的schemas标签信息转换bean,然后通过这个bean的信息,连接.订阅zookeeper节点信息创建一个invoker 将invoker的信息创建一个动 ...
- Dubbo 源码分析 - 服务导出
1.服务导出过程 本篇文章,我们来研究一下 Dubbo 导出服务的过程.Dubbo 服务导出过程始于 Spring 容器发布刷新事件,Dubbo 在接收到事件后,会立即执行服务导出逻辑.整个逻辑大致可 ...
随机推荐
- python遍历列表删除多个元素的坑
如下代码,遍历列表,删除列表中的偶数时,结果与预期不符. a = [11, 20, 4, 5, 16, 28] for i in a: if i % 2 == 0: a.remove(i) print ...
- linux设备驱动程序-设备树(3)-设备树多级子节点的转换
linux设备驱动程序--设备树多级子节点的转换 在上一章:设备树处理之--device_node转换成platform_device中,有提到在设备树的device_node到platform_de ...
- Ansible--Ansible之Roles
Ansible之Roles Roles介绍 ansible自1.2版本引入的新特性,用于层次性.结构化地组织playbook.roles能够根据层次型结构自动装载变量文件.tasks以及handler ...
- git远程上的分支到本地
先想一个自己要在本地新建的分支名称,qianjinyan git checkout -b qianjinyan origin/SELLER-2248-1018 git branch 查看分支 git ...
- 个人作业第五次——Alpha项目测试
这个作业属于哪个课程 https://edu.cnblogs.com/campus/xnsy/2019autumnsystemanalysisanddesign/ 这个作业的要求在哪里 https:/ ...
- DFS(一):砌墙问题
问题描述 使用两种砖头砌墙,砖头A宽为2,高为1,砖头B宽为3,高为1,用这两种砖头砌一面宽为W,高为H的墙. 为了使墙牢固性高,要求每种砖只能横向摆放,不能竖起来,且除了两侧以外,不能出现上下对齐的 ...
- 删除或关闭Word中的超链接
最近使用的word老是会把一些文字内容或者标题转换成乱七八糟的格式,看的莫名其妙的,找了好久也不知道什么问题,后来一查才知道是因为这些文字包含超链接,word自动转换了...你说是不是莫名其妙. 要关 ...
- 2019年牛客多校第二场 F题Partition problem 爆搜
题目链接 传送门 题意 总共有\(2n\)个人,任意两个人之间会有一个竞争值\(w_{ij}\),现在要你将其平分成两堆,使得\(\sum\limits_{i=1,i\in\mathbb{A}}^{n ...
- Educational Codeforces Round 69 (Rated for Div. 2) E. Culture Code
Educational Codeforces Round 69 (Rated for Div. 2) E. Culture Code 题目链接 题意: 给出\(n\)个俄罗斯套娃,每个套娃都有一个\( ...
- centos设置开机自启动脚本
1.新建脚本文件 我这里是为了设置开机自动设置ipv6隧道,所以命名为ipv6tunnel.sh ifconfig sit0 up ifconfig sit0 inet6 tunnel ::66.22 ...