python爬虫 TapTap
作业要求来自于https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075
- 对象 - TapTap
TapTap 是一个高品质手游玩家社区,只提供原版和官服游戏下载购买的平台。开发者无需接入SDK,即可上传游戏,海内外开发者都有机会在这里售卖正版安卓游戏。TapTap 提供真实排行榜单和玩家评价,坚持编辑独立评测推荐。在TapTap 社区,用户与开发者直接交流,推动游戏改进。
- 范围 - “Android游戏榜”各大榜单的TOP150游戏
taptap安卓游戏榜有五个榜单,分别为热门榜(根据下载量)、新品榜(根据近期发行游戏下载量)、预约榜(根据预约量)、热卖榜(根据游戏售卖量)和热玩榜(根据玩家游戏启动量)。注:热卖榜只有TOP35。

- 爬取限制 - ajax异步请求链接获取数据
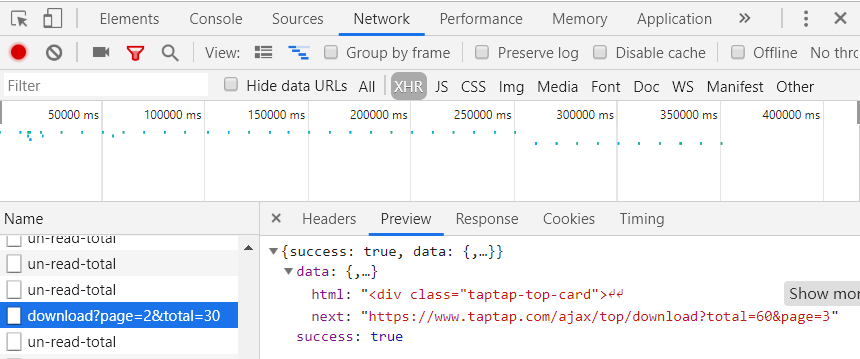
在爬取过程中,如果只是根据html元素来爬取网站数据,只能爬到30条数据。由于排行榜的数据是分页的,在点击“更多”的按钮之后才会显示下一页的数据,而且网址并没有发生变化。通过观察发现网站是通过ajax异步请求了一条链接获取数据,为了爬取整个榜单的数据信息,因此要分析该页面的请求。
首先打开浏览器的开发者工具Network中的XHR(通过XMLHttpRequest方法发送的请求),点击“更多”后发现一条新请求,进去就会发现这是查看更多数据的异步请求。
其次找到需要爬取的内容——爬取data里的html所有内容。
最后把json格式的响应内容用BeautifulSoup(html, 'html.parser')方法解析,通过对标签的筛选获得需要的信息。
为了防止在爬取过程中ip被限制,这里设置了合理的爬取间隔和使用user-agent模拟真实的浏览器提取内容(详细见下面代码)。user-agent可以在开发者工具→Network→Headers里面找到。
- 爬取内容 - 游戏名、厂商、分类、标签、评分、排名
详细代码如下:
import pymysql
from sqlalchemy import create_engine
import pandas as pd
import requests
from bs4 import BeautifulSoup
import time
import random
from urllib.parse import urlencode
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from os import path
from PIL import Image
import numpy as np
#爬取一条游戏的信息
def agame(url):
gamesDetail = {}
res = requests.get(url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'html.parser')
gamesDetail['游戏名'] = soup.select('h1')[0].text.rstrip(' CN')#截取掉游戏名后面的空格和CN标签
gamesDetail['厂商'] = soup.select('.header-text-author')[0].select('span')[1].text
if len(soup.select('.app-rating-score')) >0:#如果游戏存在评分
gamesDetail['评分'] = soup.select('.app-rating-score')[0].text
else:#如果游戏不存在评分
gamesDetail['评分'] = soup.select('.app-rating-no-score')[0].text
gamesDetail['分类'] = soup.select('li')[12].text.lstrip().rstrip()
gamesDetail['标签'] =' '.join(soup.select('#appTag')[0].text.lstrip().rstrip().split())#获取标签并转为字符串
return gamesDetail
#将一页游戏编码为utf-8
def toalist(url):
res = requests.get(url)
res.encoding = 'utf-8'
soup = my_get_soup(url)#模拟真实浏览器访问
return alist(soup)
#获取一页游戏信息
def alist(soup):
sleep()#设置合理的爬取间隔
gamesList = []
for games in soup.select('.taptap-top-card'):
if len(games.select('div'))>0:#如果存在游戏信息
gamesUrl = games.select('a')[0]['href']#获取每个游戏详情页面的网址
gamesRank = games.select('span')[1].text#获取游戏排名
gamesDict = agame(gamesUrl)
gamesDict['排名'] = gamesRank
gamesList.append(gamesDict)#把每个游戏的信息放进字典扩展到列表里
return gamesList
#设置合理的爬取间隔
def sleep():
for i in range(5):
time.sleep(random.random()*3)#沉睡随机数的3倍秒数
#随机选择user-agent
def get_ua():
au = random.choice(uas)
return au
#模拟真实浏览器访问
def my_get_soup(url):
headers = {'user-agent':get_ua()}
res = requests.get(url,headers = headers)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'html.parser')
return soup
#获取ajax异步请求的网址
def get_page(i,page):
params = {
'page':page+1,
'total': 30 * page,
}
url = 'https://www.taptap.com/ajax/top/{}?'.format(i)+ urlencode(params) #拼接URL
try:
r = requests.get(url)
if r.status_code == 200:
return r.json() # 返回json格式的响应内容
except:
return None
#在异步请求里找到需要的信息
def get_html(jsondata):
if jsondata.get('data'):
data = jsondata.get('data')
yield {
data.get('html'),
}
#解析json返回的内容
def get_soup(i,page):
jsondata = get_page(i, page)
for item in get_html(jsondata):
html = ''.join(item)
soup = BeautifulSoup(html, 'html.parser')
return soup
#保存每个游戏的标签
def save_tags(wtxt,games):
wclist = []
for j in range(len(games)):
wclist.append(games[j]['标签'])
for x in wclist:
wtxt.write(x)
wtxt.write('\n')
wtxt.close()
#保存评分最高的前30的游戏标签
def save_score(wtxt,games):
wclist = []
sorted_x = sorted(games, key=lambda x : x['评分'], reverse=True)#游戏以评分降序排列
# 输出词频最大TOP30
for j in range(len(sorted_x[:30])):
wclist.append(sorted_x[j]['标签'])
for x in wclist:
wtxt.write(x)
wtxt.write('\n')
wtxt.close()
#生成词云
def wordCloud(txt):
# 分词
wordsls = jieba.lcut(txt)
wcdict = {}
for word in wordsls:
if word != ' ':
wcdict[word] = wcdict.get(word, 0) + 1
# 排序
wcls = list(wcdict.items())
wcls.sort(key=lambda x: x[1], reverse=True)
# 去掉文件名,返回目录
d = path.dirname(__file__)
# 打开蒙版图片
alice_mask = np.array(Image.open(path.join(d, "mask.jpg")))
# 设置词云的一些属性
wc = WordCloud(background_color="white", max_words=2000, mask=alice_mask)
# 生成词云
wc.generate(txt)
# 保存到本地
wc.to_file(path.join(d, "image.png"))
# 展示
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show() downloadGames = []#热门榜
newGames = []#新品榜
reserveGames = []#预约榜
sellGames = []#热卖榜
playedGames = []#热门榜
rankList={"download","new","reserve","sell","played"}
#不同浏览器访问
uas = ["Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36",\
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/17.17134",\
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0"]
#连接mysql的账户
conInfo = "mysql+pymysql://root:123456@localhost:3306/taptap?charset=utf8"
engine = create_engine(conInfo, encoding='utf-8')#初始化引擎
for i in rankList:
rankUrl = 'https://www.taptap.com/top/{}'.format(i)#获取不同榜单的链接
if(i == 'download'):
for page in range(5):
if(page == 0):#第一页,没有异步请求
downloadGames.extend(toalist(rankUrl))#把一页的游戏信息添加到列表里
if (page > 0):#二到五页,有异步请求
soup = get_soup(i,page)
downloadGames.extend(alist(soup))
twtxt = open('tagsDownload.txt', 'w', encoding='utf-8')#将每个游戏标签写到文本里
save_tags(twtxt,downloadGames)#保存
tagstxt = open('tagsDownload.txt', 'r', encoding='utf-8').read()#打开标签文本
wordCloud(tagstxt)#生成标签词云
swtxt = open('scoreDownload.txt', 'w', encoding='utf-8')#将每个游戏评分高的标签写到文本里
save_score(swtxt,downloadGames)#保存
scoretxt = open('scoreDownload.txt', 'r', encoding='utf-8').read()#打开评分文本
wordCloud(scoretxt)#生成评分高的标签词云
gamesdf = pd.DataFrame(downloadGames)#形成表格
gamesdf.to_sql(name='download', con=engine, if_exists='append', index=False)#存储表
conn = pymysql.connect(host='localhost', port=3306, user='root', passwd='', db='taptap', charset='utf8')#连接数据库
if(i == 'new'):
for page in range(5):
if (page == 0):
newGames.extend(toalist(rankUrl))
if (page > 0):
soup = get_soup(i,page)
newGames.extend(alist(soup))
twtxt = open('tagsNew.txt', 'w', encoding='utf-8')
save_tags(twtxt,newGames)
tagstxt = open('tagsNew.txt', 'r', encoding='utf-8').read()
wordCloud(tagstxt)
swtxt = open('scoreNew.txt', 'w', encoding='utf-8')
save_score(swtxt,newGames)
scoretxt = open('scoreNew.txt', 'r', encoding='utf-8').read()
wordCloud(scoretxt)
gamesdf = pd.DataFrame(newGames)
gamesdf.to_sql(name='new', con=engine, if_exists='append', index=False)
conn = pymysql.connect(host='localhost', port=3306, user='root', passwd='', db='taptap', charset='utf8')
if (i == 'reserve'):
for page in range(5):
if (page == 0):
reserveGames.extend(toalist(rankUrl))
if (page > 0):
soup = get_soup(i,page)
reserveGames.extend(alist(soup))
twtxt = open('tagsReserve.txt', 'w', encoding='utf-8')
save_tags(twtxt,reserveGames)
tagstxt = open('tagsReserve.txt', 'r', encoding='utf-8').read()
wordCloud(tagstxt)
swtxt = open('scoreReserve.txt', 'w', encoding='utf-8')
save_score(swtxt,reserveGames)
scoretxt = open('scoreReserve.txt', 'r', encoding='utf-8').read()
wordCloud(scoretxt)
gamesdf = pd.DataFrame(reserveGames)
gamesdf.to_sql(name='reserve', con=engine, if_exists='append', index=False)
conn = pymysql.connect(host='localhost', port=3306, user='root', passwd='', db='taptap', charset='utf8')
if (i == 'sell'):
for page in range(5):
if (page == 0):
sellGames.extend(toalist(rankUrl))
if (page > 0):
soup = get_soup(i,page)
sellGames.extend(alist(soup))
twtxt = open('tagsSell.txt', 'w', encoding='utf-8')
save_tags(twtxt,sellGames)
tagstxt = open('tagsSell.txt', 'r', encoding='utf-8').read()
wordCloud(tagstxt)
swtxt = open('scoreSell.txt', 'w', encoding='utf-8')
save_score(swtxt,sellGames)
scoretxt = open('scoreSell.txt', 'r', encoding='utf-8').read()
wordCloud(scoretxt)
gamesdf = pd.DataFrame(sellGames)
gamesdf.to_sql(name='sell', con=engine, if_exists='append', index=False)
conn = pymysql.connect(host='localhost', port=3306, user='root', passwd='', db='taptap', charset='utf8')
if (i == 'played'):
for page in range(5):
if (page == 0):
playedGames.extend(toalist(rankUrl))
if (page > 0):
soup = get_soup(i,page)
playedGames.extend(alist(soup))
twtxt = open('tagsPlayed.txt', 'w', encoding='utf-8')
save_tags(twtxt,playedGames)
tagstxt = open('tagsPlayed.txt', 'r', encoding='utf-8').read()
wordCloud(tagstxt)
swtxt = open('scorePlayed.txt', 'w', encoding='utf-8')
save_score(swtxt,playedGames)
scoretxt = open('scorePlayed.txt', 'r', encoding='utf-8').read()
wordCloud(scoretxt)
gamesdf = pd.DataFrame(playedGames)
gamesdf.to_sql(name='played', con=engine, if_exists='append', index=False)
conn = pymysql.connect(host='localhost', port=3306, user='root', passwd='', db='taptap', charset='utf8')
爬取taptap
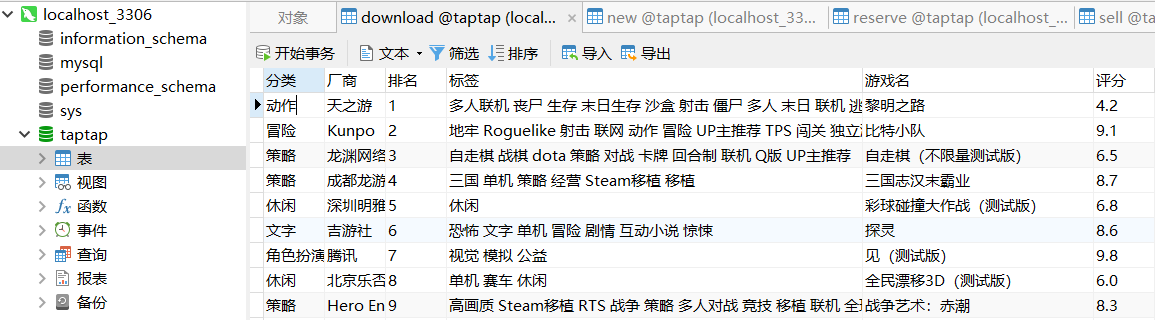
数据已存到数据库,热门榜如下图所示:
新品榜如下图所示:

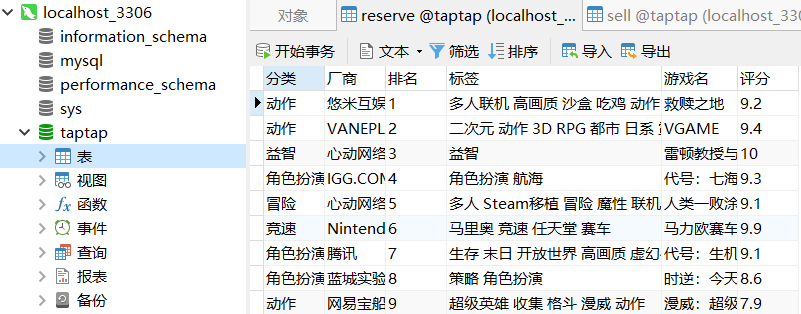
预约榜如下图所示:
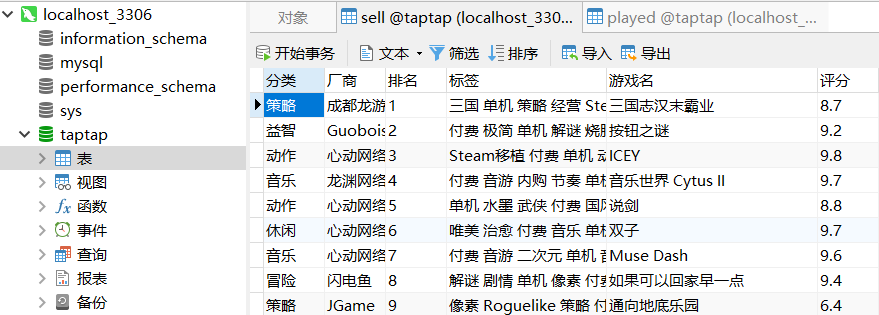
热卖榜如下图所示:
热玩榜如下图所示:

- 数据分析及文本分析
首先分别爬取了五个榜单TOP150的游戏标签,看看玩家都喜欢玩什么类型的游戏。词云生成结果如下图所示。

其中发现玩家比较喜欢玩的类型集中于多人、联机、中文、冒险和策略的游戏(基于热门榜和热玩榜),而对新游戏的期待类型则为角色扮演和策略这方面(基于新品榜和预约榜)。由于大部分的玩家为免费玩家,那么付费玩家对于游戏更热衷于单机、益智、解密和独立游戏(基于热卖榜)。
由此可见,现今对于玩家来说可玩性较高的游戏大多为联机的多人冒险游戏,,但对于玩家所期待的角色扮演和策略游戏在市场上受大众欢迎的不多,另外付费玩家想在游戏体现的更趋向于独立完成和需要动脑的,因此各大游戏厂商要想做出一个大卖、口碑又好的游戏需要定期了解玩家的游戏喜好。
接下来分析排行榜中高分游戏TOP30的游戏有哪些。由于评分是根据数以万计的玩家打的分数来的,高分游戏的类型更能体现玩家真实的喜好。词云生成结果如下图所示。

其中高分游戏排行与综合榜单的游戏类型有所不同,比较受欢迎的是单机、中文、独立游戏和UP主推荐的游戏(基于热门榜和热玩榜),最受期待的是角色扮演和单机游戏(基于新品榜和预约榜),但对于付费玩家来说游戏类型并没有过多的变化(热卖榜只有TOP35所以有影响)。
可以看出,口碑好的高分游戏大多集中于单机和独立游戏,而多数付费游戏基本上评分比免费游戏要高。一般来说,单机和独立游戏更加注重玩家的体验性,而多人联机的游戏更注重于商业化,要做出好口碑并不容易。因此,游戏制作公司如果把大多心思放在游戏剧本、提高玩家的游戏体验性和玩家与游戏的融合度,将能得到更好的口碑,也会有更多的玩家愿意为这个游戏付费。
之后来分析各大榜单上评分的数值分布。能上榜的游戏与宣传力度也有很大关系,但是游戏是否与宣传所说的那么好玩还是需要参考一下评分。分析图如下图所示。
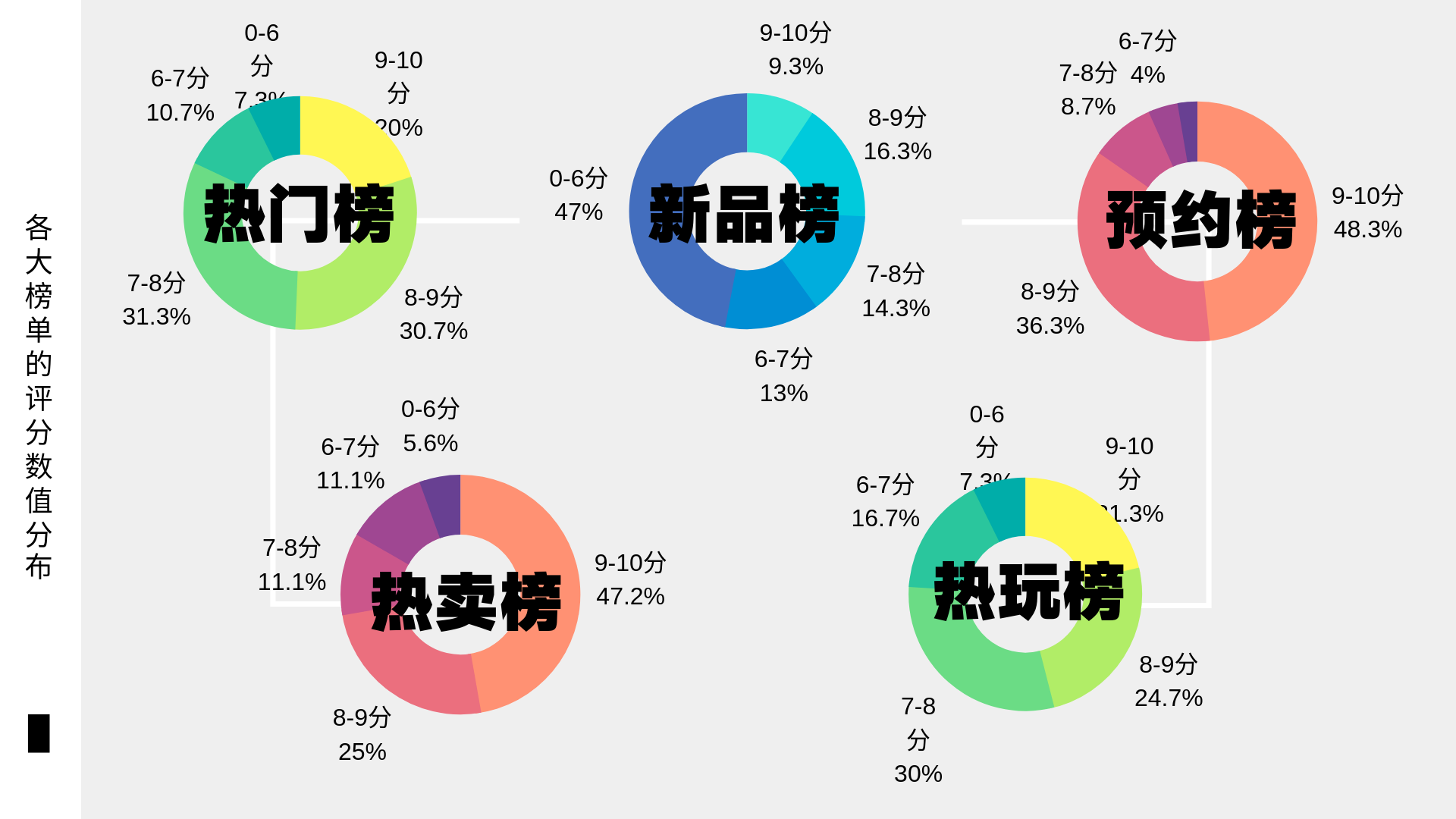
从中发现,预约榜和热卖榜高分段的游戏居多,热门榜和热玩榜分值偏中上,只有新品榜的游戏低分接近一般。由此可知,游戏在未面世时厂商的宣传度会大大影响玩家的期待值,因此许多玩家对新游戏抱有很大的期待,可当开始内测、公测的时候,游戏可能并没有厂商说的那么好,导致大量玩家对该游戏失望甚至“脱坑”,之后只有经历过玩家的一番筛选,好的游戏才慢慢脱颖而出,最终受到玩家的追捧并大卖。
最后看一下各大榜单评分TOP10的游戏。结果如下图所示。

爬虫测试到此结束。
python爬虫 TapTap的更多相关文章
- Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的博客,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了 ...
- python爬虫成长之路(一):抓取证券之星的股票数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一.鉴于此,我拾起了Python这把利器,开启了网络爬虫之路. 本篇使用的版本为python3.5,意在抓取证券之星上当天所 ...
- python爬虫学习(7) —— 爬取你的AC代码
上一篇文章中,我们介绍了python爬虫利器--requests,并且拿HDU做了小测试. 这篇文章,我们来爬取一下自己AC的代码. 1 确定ac代码对应的页面 如下图所示,我们一般情况可以通过该顺序 ...
- python爬虫学习(6) —— 神器 Requests
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 模块提供了你所需要的大多数 H ...
- 批量下载小说网站上的小说(python爬虫)
随便说点什么 因为在学python,所有自然而然的就掉进了爬虫这个坑里,好吧,主要是因为我觉得爬虫比较酷,才入坑的. 想想看,你可以批量自动的采集互联网上海量的资料数据,是多么令人激动啊! 所以我就被 ...
- python 爬虫(二)
python 爬虫 Advanced HTML Parsing 1. 通过属性查找标签:基本上在每一个网站上都有stylesheets,针对于不同的标签会有不同的css类于之向对应在我们看到的标签可能 ...
- Python 爬虫1——爬虫简述
Python除了可以用来开发Python Web之后,其实还可以用来编写一些爬虫小工具,可能还有人不知道什么是爬虫的. 一.爬虫的定义: 爬虫——网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区 ...
- Python爬虫入门一之综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- [python]爬虫学习(一)
要学习Python爬虫,我们要学习的共有以下几点(python2): Python基础知识 Python中urllib和urllib2库的用法 Python正则表达式 Python爬虫框架Scrapy ...
随机推荐
- php长连接应用
php长连接和短连接 2012-12-05 17:25 3529人阅读 评论(0) 收藏 举报 分类: 我的收藏(8) 什么是长连接,如果你没听说过,可以往下看! 长连接到底有什么用?我想你应该见 ...
- IntelliJ IDEA 快捷键(转载收藏)
自动代码 常用的有fori/sout/psvm+Tab即可生成循环.System.out.main方法等boilerplate样板代码 . 例如要输入for(User user : users)只需输 ...
- 如何免费试用SAP的Fiori应用
什么是SAP Fiori?SAP Fiori不是SAP发布的某款产品,而是SAP新一代UI设计风格和用户体验的代号. Fiori是一个意大利语中的单词,意思是"花": 不得不说SA ...
- scrapy 写文件进行debug调试
首先进入和setting同级目录 新建run.py文件 # *_*coding:utf-8 *_* from scrapy import cmdline cmdline.execute('scrapy ...
- 【DATAGUARD】物理dg的failover切换(六)
[DATAGUARD]物理dg的failover切换(六) 一.1 BLOG文档结构图 一.2 前言部分 一.2.1 导读 各位技术爱好者,看完本文后,你可以掌握如下的技能,也可以学到一些其它你 ...
- day 09作业 预科
作业 1.简述定义函数的三种方式. 定义函数的三种方式为空函数,有参函数和无参函数 2.简述函数的返回值. 如果函数没有返回值,会直接返回到None: 函数可以通过return返回出返回值: retu ...
- MySQL Others--约束(Constraint)示例
ENUM约束 --使用ENUM来限制用户输入 CREATE TABLE Student ( StudentID INT AUTO_INCREMENT PRIMARY KEY, ClassID INT, ...
- python测试开发django-44.xadmin上传图片和文件
前言 xadmin上传图片和上传文件功能 依赖环境 如果没安装Pillow的话,会有报错:practise.Upload.upload_image: (fields.E210) Cannot use ...
- VMware15.5版本通过挂载系统光盘搭建yum仓库
VMware15.5版本通过挂载系统光盘搭建yum仓库一.1.打开CentOS 7虚拟机. 2.登录虚拟机,选择未列出 用户名:root 密码:输入自己设置的密码 点击登录. 3.右键单击打开终端. ...
- PC软件/web网站/小程序/手机APP产品如何增加个人收款接口
接入前准备 通过 XorPay 注册个人收款接口,原理是帮助你签约支付宝和微信(不需要营业执照)支持个人支付宝和个人微信支付接口,大概几分钟可以开通,开通后即可永久使用 PC 网站接入 效果:用户点击 ...