requests获取响应时间(elapsed)与超时(timeout)、小数四舍五入
前言
requests发请求时,接口的响应时间,也是我们需要关注的一个点,如果响应时间太长,也是不合理的。
如果服务端没及时响应,也不能一直等着,可以设置一个timeout超时的时间
elapsed官方文档
elapsed里面几个方法介绍
total_seconds 总时长,单位秒 days 以天为单位 microseconds (>= 0 and less than 1 second) 获取微秒部分,大于0小于1秒 seconds Number of seconds (>= 0 and less than 1 day) 秒,大于0小于1天 max = datetime.timedelta(999999999, 86399, 999999) 最大时间 min = datetime.timedelta(-999999999) 最小时间 resolution = datetime.timedelta(0, 0, 1) 最小时间单位
获取响应时间
1.获取elapsed不同的返回值
import requests
r = requests.get("https://home.cnblogs.com/u/lixy-88428977/")
print("elapsed: %s" % r.elapsed)
print("total_seconds: %s" % r.elapsed.total_seconds())
print("microseconds: %s" % r.elapsed.microseconds)
print("seconds: %s" % r.elapsed.seconds)
print("days: %s" % r.elapsed.days)
print("max: %s" % r.elapsed.max)
print("min: %s" % r.elapsed.min)
print("resolution: %s" % r.elapsed.resolution)
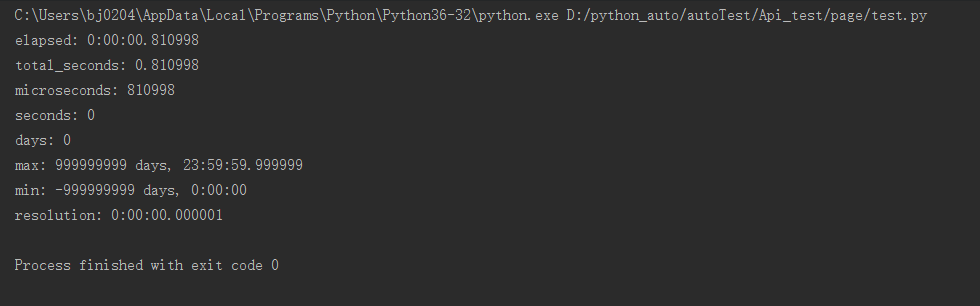
所以获取响应时间的正确姿势应该是:r.elapsed.total_seconds(),单位是s
timeout超时
1.如果一个请求响应时间比较长,不能一直等着,可以设置一个超时时间,让它抛出异常
2.如下请求,设置超时为0.5s,那么就会抛出这个异常:requests.exceptions.ConnectTimeout: HTTPConnectionPool
import requests
r = requests.get("https://home.cnblogs.com/u/lixy-88428977/", timeout=1)
print("elapsed: %s" % r.elapsed)
print("total_seconds: %s" % r.elapsed.total_seconds())
print("microseconds: %s" % r.elapsed.microseconds)

小数点后取2位(四舍五入)以及取2位(四舍五不入)的方法
一.小数点后取2位(四舍五入)的方法
方法一:round()函数
import requests
r = requests.get("https://home.cnblogs.com/u/lixy-88428977/", timeout=1)
time = r.elapsed.total_seconds()
print("原始数据: %s" % time)
print(round(time, 3))

方法二:’%.2f’ %f 方法
import requests
r = requests.get("https://home.cnblogs.com/u/lixy-88428977/", timeout=1)
time = r.elapsed.total_seconds()
print("原始数据: %s" % time)
print('%.2f' % time)

方法三:Decimal()函数
import requests
from decimal import Decimal r = requests.get("https://home.cnblogs.com/u/lixy-88428977/", timeout=1)
time = r.elapsed.total_seconds()
print("原始数据: %s" % time) a = Decimal(time).quantize(Decimal('0.00'))
print(a)

二.小数点后取2位(四舍五不入)的方法
import requests
def get_two_float(f_str, n):
f_str = str(f_str) # f_str = '{}'.format(f_str) 也可以转换为字符串
a, b, c = f_str.partition('.')
c = (c+""*n)[:n] # 如论传入的函数有几位小数,在字符串后面都添加n为小数0
return ".".join([a, c]) r = requests.get("https://home.cnblogs.com/u/lixy-88428977/", timeout=1)
time = r.elapsed.total_seconds()
print("原始数据: %s" % time) print(get_two_float(time, 2))

整理此篇文章,源于,接口自动化响应时间的获取,打印!
url = self.uri + "/json/crm/save.action"
data = self.s.post(url, data=self.testDody, verify=False)
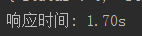
Time = str(data.elapsed.total_seconds())
print(('响应时间: '+'%.2f'% float(Time) +'s' ))
作者:含笑半步颠√
博客链接:https://www.cnblogs.com/lixy-88428977
声明:本文为博主学习感悟总结,水平有限,如果不当,欢迎指正。如果您认为还不错,欢迎转载。转载与引用请注明作者及出处。
requests获取响应时间(elapsed)与超时(timeout)、小数四舍五入的更多相关文章
- requests获取响应时间(elapsed)与超时(timeout)
前言 requests发请求时,接口的响应时间,也是我们需要关注的一个点,如果响应时间太长,也是不合理的.如果服务端没及时响应,也不能一直等着,可以设置一个timeout超时的时间 关于request ...
- python接口自动化20-requests获取响应时间(elapsed)与超时(timeout) ok试了 获取响应时间的
前言 requests发请求时,接口的响应时间,也是我们需要关注的一个点,如果响应时间太长,也是不合理的.如果服务端没及时响应,也不能一直等着,可以设置一个timeout超时的时间 关于request ...
- python接口自动化20-requests获取响应时间(elapsed)与超时(timeout)
前言 requests发请求时,接口的响应时间,也是我们需要关注的一个点,如果响应时间太长,也是不合理的. 如果服务端没及时响应,也不能一直等着,可以设置一个timeout超时的时间 关于reques ...
- request的响应时间elapsed和超时timeout
前言:requests发请求时,接口的响应时间,也是我们需要关注的一个点,如果响应时间太长,也是不合理的 1.获取接口请求的响应时间 r.elapsed.total_seconds() import ...
- 爬虫 Http请求,urllib2获取数据,第三方库requests获取数据,BeautifulSoup处理数据,使用Chrome浏览器开发者工具显示检查网页源代码,json模块的dumps,loads,dump,load方法介绍
爬虫 Http请求,urllib2获取数据,第三方库requests获取数据,BeautifulSoup处理数据,使用Chrome浏览器开发者工具显示检查网页源代码,json模块的dumps,load ...
- axios超时timeout拦截
应用场景: 在网络请求中,可能不可避免的会遇到网络差或者请求超时的情况,这时候,如果你采用的技术是axios,那就可以通过设置拦截器捕获这个异常情况,并做出下一步处理. 代码实践: ① 设置拦截器,返 ...
- requests获取所有状态码
requests获取所有状态码 requests默认是不会获取301/302的状态码的.可以设置allow_redirects=False,这样就可以获取所有的状态码了 import requests ...
- python3爬虫-通过requests获取拉钩职位信息
import requests, json, time, tablib def send_ajax_request(data: dict): try: ajax_response = session. ...
- 解决requests获取源代码时中文乱码问题
用requests获取源代码时,如果是中文网页,就可能会出现乱码,下面我以中关村的网站为例: import requests url = 'http://desk.zol.com.cn/meinv/' ...
随机推荐
- pandas基础操作
```python import pandas as pd import numpy as np ``` ```python s = pd.Series([1,3,6,np.nan,44,1]) s ...
- java LinkedHashMap实现LRUCache缓存
package java_map; import java.util.Collections; import java.util.LinkedHashMap; import java.util.Map ...
- Leetcode——3. 无重复字符的最长子串
难度: 中等 题目 Given a string, find the length of the longest substring without repeating characters. 给定一 ...
- 记一次wsl上的pip3安装失败问题 The following packages were automatically installed and are no longer required:
转载请注明来源.https://www.cnblogs.com/sogeisetsu/.然后我的CSDNhttps://blog.csdn.net/suyues/article/details/103 ...
- 08-numpy-笔记-sum
求和: axis = 0 按列求和 axis = 1 按行求和 >>> import numpy as np >>> a = np.mat([[1,2,3],[4, ...
- Java Scanner语法
1.导入: import java.util.Scanner; 2.创建对象 Scanner scan = new Scanner(System.in);//一般变量名为scan或者in 最后关闭,s ...
- 【java异常】redis.clients.jedis.exceptions.JedisConnectionException: Could not get a res
产生此错误的原因通常是: 一.Redis没有启动: 我自己遇到一次这样的问题.汗! 二.由于防火墙原因无法连接到Redis; 1.服务器防火墙入站规则. 2.访问Redis的应用程序所在主机的出站规则 ...
- Ajax 与 Django
目录 Django与AJAX orm优化查询: MTV 与 MVC模型 choices 参数 update 与 save的区别 AJAX导入: Jquery 实现AJAX ajax基本语法结构 原生J ...
- No module named 'requests_toolbelt'
pip install requests-toolbelt
- CF 494E Sharti
CF 494E Sharti 题意:一个\(n \times n\)的棋盘,共有m个矩形中的格子为白色.两个人需要博弈,每次操作选择一个边长不超过k的正方形并翻转颜色,每次翻转需要正方形的右下角为白色 ...