24、Checkpoint原理剖析
一、原理
1、Checkpoint是什么
Checkpoint,是Spark提供的一个比较高级的功能。
有的时候,比如说,我们的Spark应用程序,特别的复杂,然后呢,从初始的RDD开始,到最后整个应用程序完成,有非常多的步骤,
比如超过20个transformation操作。而且呢,整个应用运行的时间也特别长,比如通常要运行1~5个小时。 在上述情况下,就比较适合使用checkpoint功能。因为,对于特别复杂的Spark应用,有很高的风险,会出现某个要反复使用的RDD,
因为节点的故障,虽然之前持久化过,但是还是导致数据丢失了。那么也就是说,出现失败的时候,没有容错机制,所以当后面的transformation操作,
又要使用到该RDD时,就会发现数据丢失了(CacheManager),此时如果没有进行容错处理的话,那么可能就又要重新计算一次数据。 简而言之,针对上述情况,整个Spark应用程序的容错性很差;
2、Checkpoint的功能
所以,针对上述的复杂Spark应用的问题(没有容错机制的问题)。就可以使用checkponit功能。
checkpoint功能是什么意思?checkpoint就是说,对于一个复杂的RDD chain,我们如果担心中间某些关键的,在后面会反复几次使用的RDD,
可能会因为节点的故障,导致持久化数据的丢失,那么就可以针对该RDD格外启动checkpoint机制,实现容错和高可用。 checkpoint,就是说,首先呢,要调用SparkContext的setCheckpointDir()方法,设置一个容错的文件系统的目录,比如说HDFS;
然后,对RDD调用调用checkpoint()方法。之后,在RDD所处的job运行结束之后,会启动一个单独的job,来将checkpoint过的RDD的数据写入之前设置的文件系统,进行高可用、容错的类持久化操作。
那么此时,即使在后面使用RDD时,它的持久化的数据,不小心丢失了,但是还是可以从它的checkpoint文件中直接读取其数据,而不需要重新计算。(CacheManager)
3、图解
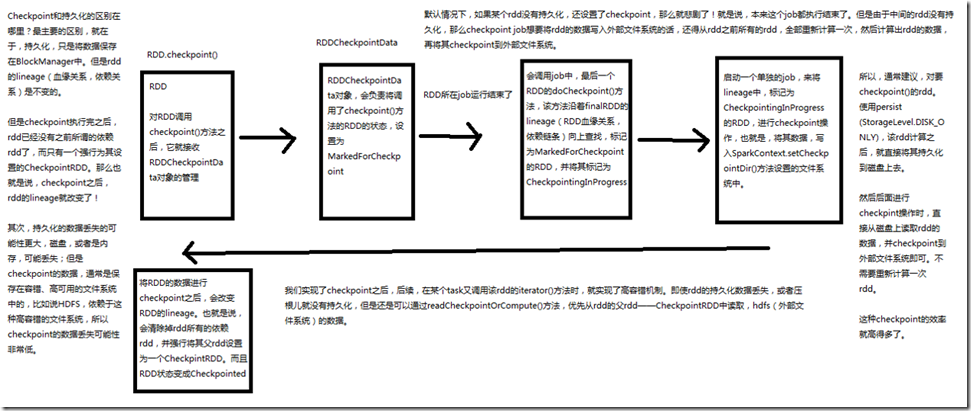
Checkpoint和持久化的最主要的区别,就在于,持久化,只是将数据保存在BlockManager中,但是RDD的lineage(血缘关系、依赖关系)是不变的; 但是CheckPoint执行完之后,rdd已经没有了之前所谓的依赖rdd了,而只有一个强行为其设置的checkpointRDD,也就是说,checkpoint后,rdd的lineage就改变了; 其次,持久化的数据丢失的可能性更大,磁盘,或者是内存,可能丢失,但是checkpoint的数据,通常是保存在容错、高可用的文件系统中的,比如说HDFS、依赖于这种
高容错的文件系统,所以checkpoint的数据丢失可能性非常低; 默认情况下,如果某个rdd没有持久化,还设置了checkpoint,就是说,本来这个job都执行结束了,但是由于中间的rdd没有持久化,那么checkpoint job想要将rdd的数据写
入外部文件系统的话,还得从之前所有的rdd,全部重新计算一次,然后计算出rdd的数据,再将其checkpoint到外部文件系统; 所以,通常建议,对要checkpoint()的rdd,使用persist(StorageLevel.DISK_ONLY),该RDD计算之后,就直接将其持久化到磁盘上去,然后后面进行checkpoint操作时,直接
从磁盘上读取rdd的数据,并checkpoint到外部文件系统即可,不需要重新计算一次rdd,这种checkpoint的效率就高很多了; 我们实现了checkpoint之后,后续,在某个task又调用该rdd的iterator()方法时,就实现了高容错机制,即使rdd的持久化数据丢失,或者就没有持久化,但是还是可以
通过readCheckpointOrComputer()方法,优先从rdd的父rdd的chechpointrdd中读取,hdfs(外部文件系统的数据);
二、源码
###org.apache.spark.rdd/RDD.scala /**
* 先presist()再checkpoint()原理如下
* 那么首先执行到该rdd的iterator()之后,会先发现storageLevel != StorageLevel.NONE,那么就会通过CacheManager读获取数据,此时会发现通过
* BlockManager获取不到数据(第一次执行)
* 第一次还是会计算一次该RDD的数据,然后通过CacheManager的putInBlockManager()将其通过BlockManager进行持久化
* rdd所在的job运行结束了,然后启动单独job进行checkpoint操作,此时就又执行到该rdd的iterator()方法,那么就会发现storageLevel != StorageLevel.NONE
* 默认从BlockManager直接读取持久化数据(正常情况下,是可以的),如果非正常情况下,持久化数据丢失了,那么此时会走else,调用computeOrReadCheckpoint()
* 方法,判断如果rdd的isCheckPoint为true,那么就会用它的父rdd的iterator()方法,其实就是从checkpoint外部文件系统中读取数据
*/
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
if (storageLevel != StorageLevel.NONE) {
// cacheManager相关东西
// 如果storageLevel不为NONE,就是说,我们之前持久化过RDD,那么就不要直接去父RDD执行算子,计算新的RDD的partition了
// 优先尝试使用CacheManager,去获取持久化的数据
SparkEnv.get.cacheManager.getOrCompute(this, split, context, storageLevel)
} else {
// 进行rdd partition的计算
computeOrReadCheckpoint(split, context)
}
} ###org.apache.spark.rdd/CheckpointRDD.scala override def compute(split: Partition, context: TaskContext): Iterator[T] = {
// 使用hadoop的api Path 创建了一个,针对hdfs文件的路径,然后用checkpointRDD的readFromFile()方法,来读取hdfs中的数据
val file = new Path(checkpointPath, CheckpointRDD.splitIdToFile(split.index))
CheckpointRDD.readFromFile(file, broadcastedConf, context)
} ###org.apache.spark.rdd/CheckpointRDD.scala def readFromFile[T](
path: Path,
broadcastedConf: Broadcast[SerializableWritable[Configuration]],
context: TaskContext
): Iterator[T] = {
val env = SparkEnv.get
// 调用hdfs的api,FileSystem
//
val fs = path.getFileSystem(broadcastedConf.value.value)
val bufferSize = env.conf.getInt("spark.buffer.size", 65536)
// FileSystem的open()方法,打开针对hdfs文件的输入流
val fileInputStream = fs.open(path, bufferSize)
// 对输入流进行了反序列化流的一个包装
val serializer = env.serializer.newInstance()
// 使用deserializeStream的asIterator()方法读取数据
val deserializeStream = serializer.deserializeStream(fileInputStream) // Register an on-task-completion callback to close the input stream.
context.addTaskCompletionListener(context => deserializeStream.close()) deserializeStream.asIterator.asInstanceOf[Iterator[T]]
}
24、Checkpoint原理剖析的更多相关文章
- NameNode和SecondaryNameNode工作原理剖析
NameNode和SecondaryNameNode工作原理剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode中的元数据是存储在那里的? 1>.首先,我 ...
- NameNode与DataNode的工作原理剖析
NameNode与DataNode的工作原理剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS写数据流程 >.客户端通过Distributed FileSyst ...
- ThreadLocal及InheritableThreadLocal的原理剖析
我们知道,线程的不安全问题,主要是由于多线程并发读取一个变量而引起的,那么有没有一种办法可以让一个变量是线程独有的呢,这样不就可以解决线程安全问题了么.其实JDK已经为我们提供了ThreadLocal ...
- JVM Attach实现原理剖析
本文转载自JVM Attach实现原理剖析 前言 本文旨在从理论上分析JVM 在 Linux 环境下 Attach 操作的前因后果,以及 JVM 为此而设计并实现的解决方案,通过本文,我希望能够讲述清 ...
- ext文件系统机制原理剖析
本文转载自ext文件系统机制原理剖析 导语 将磁盘进行分区,分区是将磁盘按柱面进行物理上的划分.划分好分区后还要进行格式化,然后再挂载才能使用(不考虑其他方法).格式化分区的过程其实就是创建文件系统. ...
- Dubbo原理剖析 之 @DubboReference.version设置为*
原文链接 Dubbo原理剖析 之 @DubboReference.version设置为* 1 背景 Dubbo在消费端提供了一个功能,即将消费者的版本号指定为*,那么不管服务端的接口版本是啥,都可以调 ...
- DelayQueue延迟队列原理剖析
DelayQueue延迟队列原理剖析 介绍 DelayQueue队列是一个延迟队列,DelayQueue中存放的元素必须实现Delayed接口的元素,实现接口后相当于是每个元素都有个过期时间,当队列进 ...
- synchronized原理剖析
synchronized原理剖析 并发编程存在什么问题? 1️⃣ 可见性 可见性:是指当一个线程对共享变量进行了修改,那么另外的线程可以立即看到修改后的最新值. 案例演示:一个线程A根据 boolea ...
- ASP.NET Core 运行原理剖析2:Startup 和 Middleware(中间件)
ASP.NET Core 运行原理剖析2:Startup 和 Middleware(中间件) Startup Class 1.Startup Constructor(构造函数) 2.Configure ...
随机推荐
- [清晰] kubernets权威指南第2版
------ 郑重声明 --------- 资源来自网络,纯粹共享交流, 如果喜欢,请您务必支持正版!! --------------------------------------------- 下 ...
- 报告题目:HAO智能:HI + AI + OI
报告题目:HAO智能:HI + AI + OI 报告摘要:大数据面向异构自治的多源海量数据, 旨在挖掘数据间复杂且演化的关联.大数据知识工程(BigKE)从大数据的 HACE定理开始, 从大知识建模 ...
- HelloWorld! C++纠错版
例题:1 #include<iostream> int main() { cout << "HelloWorel!" ; ; } #include < ...
- fetch() without execute() [for Statement "SHOW VARIABLES LIKE 'wsrep_on'
增加栏位: pt-online-schema-change --user=root --password=a099e0 --alter "ADD COLUMN IS_MOBILE INT ...
- svn忘记密码怎么办?如何获取svn账号和密码?
SVN作为一种开放源代码的集中式版本控制系统,一直以来都深受所有公司的喜爱.伴随着它使用范围的广泛,一系列问题也随之接踵而至. 我们今天就来谈谈比较常见的但一般除了一个人干着急没办法解决的问题,那就是 ...
- 高效内存池的设计方案[c语言]
一.前言概述 本人在转发的博文<内存池的设计和实现>中,详细阐述了系统默认内存分配函数malloc/free的缺点,以及进行内存池设计的原因,在此不再赘述.通过对Nginx内存池以及< ...
- MQTT的websockets应用_转
转自:mosquitto 与websocket 的结合 前言 mosquitto 作为一个消息代理, 客户端与 mosquitto 服务端的通信时基于 MQTT 协议的, 而现在的主流 web 应用时 ...
- Flink原理(二)——资源
前言 本文主要是想简要说明Flink在集群部署.任务提交.任务运行过程中资源情况,若表述有误欢迎大伙留言分享,非常感谢! 一.集群部署阶段 集群部署这里指的是Flink standalone模式,因为 ...
- http通信示例Httpclient和HttpServer
本示例源于为朋友解决一个小问题,数据库到服务器的数据传输,由于本人能力有限,暂时将它理解为从数据库中获取数取表数据,实际上有可能是文件或者其他形式的数据,不过原理都得用流传输, 首先httpclien ...
- 【转】spring 自定义注解(annotation)与 aop获取注解
首先我们先介绍Java自定义注解. 在开发过程中,我们实现接口的时候,会出现@Override,有时还会提示写@SuppressWarnings.其实这个就是Java特有的特性,注解. 注解就是某种注 ...