Everybody Dance Now
一、摘要
作者提出了一种简单的动作迁移方法,实现了“do as I do”:给定一个人跳舞的源视频,作者可以在目标对象表演标准动作的短短几分钟后,将该表演转移到一个新的(业余的)目标上。作者提出了一个基于时空平滑的逐帧的时图像转换问题。用姿态检测作为源和目标之间的中间表示,作者学习了一个从姿态图片到目标对象外观的映射。作者将此设置应用于包括真实面部合成在内的时间上相干的视频生成。
二、引言
作者通过基于像素的端到端的原则实现两个对象之间的动作迁移,这种方法和以前的最近邻方法和动作重定位都有区别。在作者提出的框架上,作者创造出了很多视频。为了逐帧地实现两个视频对象的动作迁移,必须学习出两个独立图片之间的映射关系,即找到源和目标集合之间图像到图像的转换关系。然而没有两个对象表演相同的动作而产生的图像对,即使两个对象都在转圈,但是也没办法做到一模一样。
基于关键点的姿态内在地将人体姿势而不是外形进行编码。作者用姿势图作为每帧中人体的中间表示,对每帧图像进行姿态检测得到(姿态图像-目标人体图像)对应的图像对。有了这些图像对,作者便可以以有监督的学习出图像到图像的转换模型。为了将动作从源转换到对象上,作者将姿态图输入到训练好的模型上,然后在目标对象上得到和源相同的姿势。作者添加了两个部分来提结果的质量:为了让时序动作更流畅,在前一帧的基础上有条件地预测下一帧(we condition the prediction at each frame on that of the previous time step)。为了生成更加真实的脸部动作,作者训练了一个特殊的GAN来生成目标对象的面部。
作者提出了一种生成视频的方法,生成的视频将源视频的动作可以迁移到目标视频上,它不需要昂贵的3D或者动作捕捉数据就可以实现,作者主要提出了一种基于学习的不同视频人体动作迁移的方法。该方法可以实现复杂的动作迁移并且细节做的很好,做的很逼真,作者还在baseline上进行了各个部分的消融实验。
作者的故事讲得很好,在提到基于关节点的姿态之前,都让读者觉得让另外一个对象模拟源对象的动作是非常困难的事情,当作者提到姿态这个很常见的模式时,反过来看,才发现姿态原来很常见,但是作者前半段的叙述就让人很想看下去,看怎么去解决这个困难的问题
三、相关工作
作者是学习去合成新的动作,而不是操纵现有的视频帧。
人体动力学模型,得到3D节点估计
四、方法
给定一个源视频和另外一个目标人物,目标是生成一个新的视频,视频中的目标人物表演着和源视频中人物的相同的动作。这个任务分为三个部分进行:姿态检测、全局姿态归一化、从归一化的姿态图映射到目标对象上。在姿态检测中,作者用最优的姿态检测器生成源视频帧的姿态图。全局姿态归一化为了解决每一帧源和目标人体外形和未知的差异。设计了一个对抗训练系统将归一化的姿态图映射到目标对象上。
训练:
给定原始目标视频中的一帧\(y\),用姿态估计器\(p\)得到对应的姿态图\(x = P(y)\),在训练过程中,用\((x,y)\)对学习出一个映射函数\(G\),映射函数将生产目标人物的姿态图的合成图片,通过判别器\(D\)和用VGGNet预训练的感知重建损失\(dist\)来优化生成的虚拟图像\(G(x)\),使其更接近真实帧\(y\),判别器\(D\)用来判断真实对(x,y)和虚假对(x,G(x))。
判别器:D判断real image pairs 和fake image pairs,即(x,y)和(x, G(x))
生成器:G用姿态图生成虚拟图像G(x)
损失:y和G(x)之间的感知重建损失dist
转换
将源视频中的一帧\(y'\)用姿态估计器检测出姿态\(x'\),然后对其进行全局姿态归一化转化为\(x\),最后用生成器\(G\)生成最终的和\(y'\)帧动作一致的虚拟图像\(G(x)\)。
全局姿态归一化
分析每个对象姿态的高度和脚踝位置、在最近和最远脚踝位置用线性映射进行尺度和位移变化
1. 转换的具体过程

姿态检测→全局姿态归一化→从归一化的姿态图映射到目标对象上
- 用最优的姿态检测器生成源视频帧的姿态图
- 全局姿态归一化为了解决每一帧源和目标人体外形和未知的差异
- 设计了一个对抗训练系统将归一化的姿态图映射到目标对象上
2. 姿态估计
用openpose进行姿态估计产生关节点的二维坐标,作者将二维坐标点用线段连起来生成了如左图所示的火柴人。

3. 全局姿态归一化
- 为了解决源视频和目标视频中人体外形和未知差异
- 计算偏移量b
\[
b=t_{\min }+\frac{a_{\text {source }}-S_{\min }}{S_{\max }-S_{\min }}\left(t_{\max }-t_{\min }\right)-f_{\text {source }}
\]
- 尺度缩放比例scale
\[
\text { scale }=\frac{t_{\text {far }}}{S_{\text {far }}}+\frac{a_{\text {source }}-s_{\text {min }}}{S_{\text {max }}-s_{\text {min }}}\left(\frac{t_{\text {close }}}{s_{\text {close }}}-\frac{t_{\text {far }}}{S_{\text {far }}}\right)
\]
4. 训练生成器G
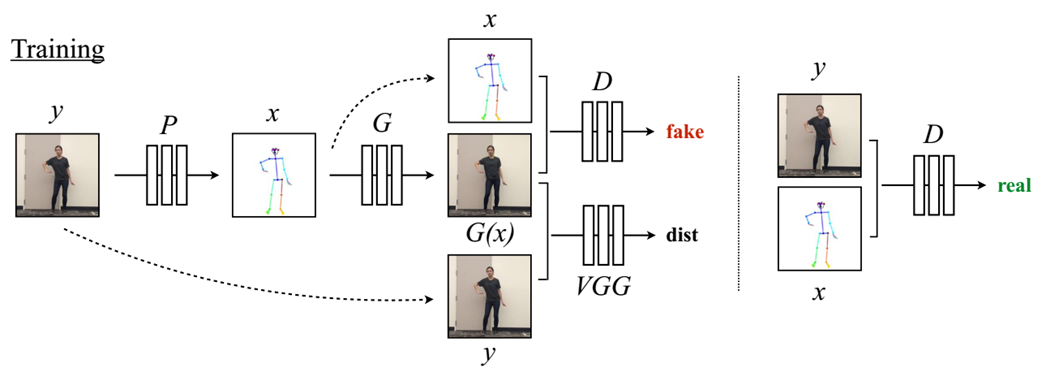
以pix2pixHD作为baseline:
\[
\min _{G}\left(\left(\max _{D_{1}, D_{2}, D_{3}} \sum_{k=1,2,3} \mathcal{L}_{\mathrm{GAN}}\left(G, D_{k}\right)\right)+\lambda_{F M} \sum_{k=1,2,3} \mathcal{L}_{\mathrm{FM}}\left(G, D_{k}\right)+\lambda_{V G G} \mathcal{L}_{V G G}(G(x), y)\right)
\]
第一项为对抗损失、第二项为特征匹配损失、第三项为感知重建损失
- 对抗损失:\(\mathcal{L}_{\mathrm{GAN}}(G, D)=\mathbb{E}_{(x, y)}[\log D(x, y)]+\mathbb{E}_{x}[\log (1-D(x, G(x))]\)
- 特征匹配损失:\(\mathcal{L}_{F \mathcal{M}}\left(G, D_{k}\right)=\mathbb{E}_{(s, \chi)} \sum_{i=1}^{T} \frac{1}{N_{i}}\left[\left\|D_{k}^{(i)}(s, x)-D_{k}^{(i)}(s, G(s))\right\|_{1}\right]\)
- 感知重建损失:\(\ell_{f e a t}^{\phi, j}(\hat{y}, y)=\frac{1}{C_{j} H_{j} W_{j}}\left\|\phi_{j}(\hat{y})-\phi_{j}(y)\right\|_{2}^{2}\)
相应参考文献:
High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
Perceptual Losses for Real-Time Style Transfer and Super-Resolution.
5.时间平滑
为了实现视频帧在时间上的连续性,作者修改单个图像生成设置来强制相邻帧之间的时间相干性。
生成器G的输入:当前帧t的姿态图+前一帧生成的虚拟图像
判别器:判断当前帧和前一帧成对的图像
在最大化D的能力的前提下,最小化D对G的判断能力
\[
\begin{array}{l}{\mathcal{L}_{\text {smooth }}(G, D)=\mathbb{E}_{(x, y)}\left[\log D\left(x_{t-1}, x_{t}, y_{t-1}, y_{t}\right)\right]+\mathbb{E}_{x}\left[\log \left(1-D\left(x_{t-1}, x_{t}, G\left(x_{t-1}\right), G\left(x_{t}\right)\right)\right]\right.}\end{array}
\]
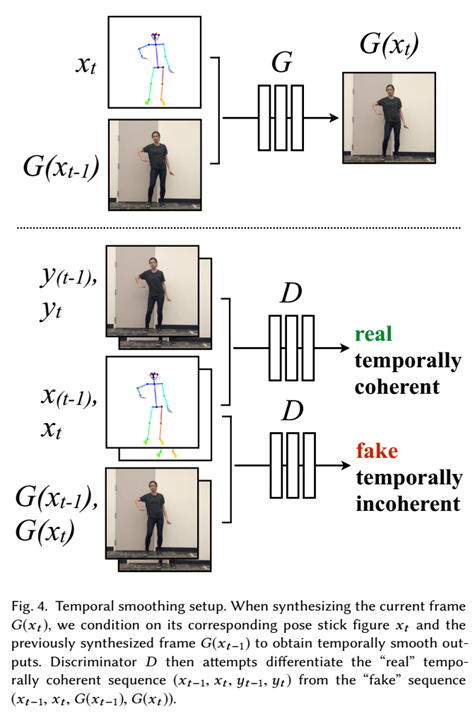
6.Face GAN
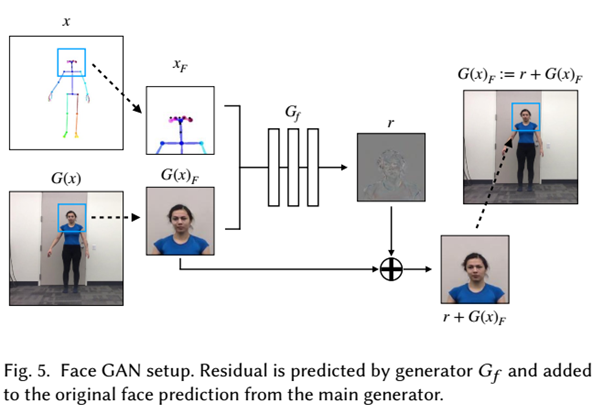
使用主生成器G生成场景的完整图像之后,输入以面部G(x)为中心的图像的较小部分和这个部分对应的姿势图。r为residual,最后的输出是残差r和原来生成的面部相加。
\[
\begin{array}{l}{\mathcal{L}_{\text {face }}\left(G_{f}, D_{f}\right)=\mathbb{E}_{\left(x_{F}, y_{F}\right)}\left[\log D_{f}\left(x_{F}, y_{F}\right)\right]+\mathbb{E}_{x_{F}}\left[\log \left(1-D_{f}\left(x_{F}, G(x)_{F}+r\right)\right)\right]}\end{array}
\]
四、实验结果
由于生成图像,没有相应的真实图像来评价,为了评价单个图像的质量,作者用structural
similarity(SSIM)和Learned Perceptual Image Patch Similarity(LPIPS)两个指标来评价生成图像的性能
相关参考文献:
Image quality assessment:from error visibility to structural similarity.
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric.
身体图像输出比较:

面部图像输出比较:

姿态距离:\(d\left(p, p^{\prime}\right)=\frac{1}{n} \sum_{k=1}^{n}\left\|p_{k}-p_{k}^{\prime}\right\|_{2}\)

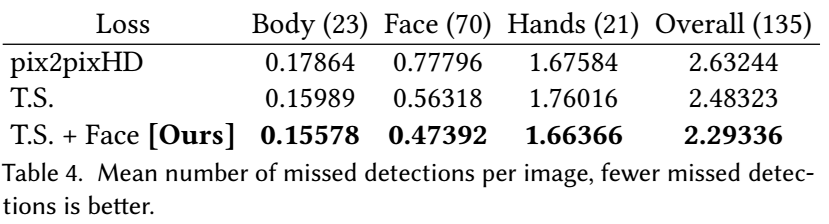
平均每幅图未检测到的连接点数量:
五、算法不足
姿态估计不准确导致生成的视频帧不准确、不连续,即使用时间平滑也无法完美解决这个问题
当输入的视频速度和训练的视频速度不相同时就会出现错误(作者使用120帧/秒的速度拍摄目标人物约20分钟)
实验结果还是会出现抖动和摇晃(对姿态图进行平滑处理会减少抖动现象)
参考博客
https://blog.csdn.net/gdymind/article/details/82696481
https://zhuanlan.zhihu.com/p/56808180
https://www.jiqizhixin.com/articles/2018-10-31-20
https://blog.csdn.net/weixin_39373480/article/details/86763715
https://blog.csdn.net/qq_36113487/article/details/85041755
Everybody Dance Now的更多相关文章
- BZOJ 1305: [CQOI2009]dance跳舞 二分+最大流
1305: [CQOI2009]dance跳舞 Description 一次舞会有n个男孩和n个女孩.每首曲子开始时,所有男孩和女孩恰好配成n对跳交谊舞.每个男孩都不会和同一个女孩跳两首(或更多)舞曲 ...
- Malek Dance Club(递推)
Malek Dance Club time limit per test 1 second memory limit per test 256 megabytes input standard inp ...
- iOS开发笔记15:地图坐标转换那些事、block引用循环/weak–strong dance、UICollectionviewLayout及瀑布流、图层混合
1.地图坐标转换那些事 (1)投影坐标系与地理坐标系 地理坐标系使用三维球面来定义地球上的位置,单位即经纬度.但经纬度无法精确测量距离戒面积,也难以在平面地图戒计算机屏幕上显示数据.通过投影的方式可以 ...
- BZOJ-1305 dance跳舞 建图+最大流+二分判定
跟随YveH的脚步又做了道网络流...%%% 1305: [CQOI2009]dance跳舞 Time Limit: 5 Sec Memory Limit: 162 MB Submit: 2119 S ...
- UVA 1291 十四 Dance Dance Revolution
Dance Dance Revolution Time Limit:3000MS Memory Limit:0KB 64bit IO Format:%lld & %llu Su ...
- UVALive 4222 Dance 模拟题
Dance 题目连接: https://icpcarchive.ecs.baylor.edu/index.php?option=com_onlinejudge&Itemid=8&pag ...
- HUST 1017 Exact cover dance links
学习:请看 www.cnblogs.com/jh818012/p/3252154.html 模板题,上代码 #include<cstdio> #include<cstring> ...
- Making the Elephant Dance: Strategic Enterprise Analysis
http://www.modernanalyst.com/Resources/Articles/tabid/115/ID/2934/categoryId/23/Making-the-Elephant- ...
- bzoj 1305: [CQOI2009]dance 二分+網絡流判定
1305: [CQOI2009]dance跳舞 Time Limit: 5 Sec Memory Limit: 162 MBSubmit: 1340 Solved: 581[Submit][Sta ...
- 持续集成之戏说Check-in Dance
尽管Thoughtworks的首席科学家Martion folwer 为“持续集成 ” 下了定义,但由于自身背景与经历的不同,每个人对其都有不同的理解.从狭义上讲,持续集成可以认为是一种基于某种或者某 ...
随机推荐
- 【bzoj4559】[JLoi2016]成绩比较(dp+拉格朗日插值)
bzoj 题意: 有\(n\)位同学,\(m\)门课. 一位同学在第\(i\)门课上面获得的分数上限为\(u_i\). 定义同学\(A\)碾压同学\(B\)为每一课\(A\)同学的成绩都不低于\(B\ ...
- prometheus数据可视化
一.prometheus自带简单的web可视化页面: http://192.168.1.28:9090/graph 二.grafana是一套开源的分析监视平台,支持prometheus等数据源:UI非 ...
- zz《百度地图商业选址》
作者 | 阚长城 编辑 | 张慧芳 题图 | 站酷海阔 人类几千年的文明催生了城市的发展,计算机与复杂科学带给我们新的资源——大数据.罗马非一日建成,人力和时间成本极大,但试想一下,如果有了大数据,罗 ...
- 浅谈DFS序
浅谈DFS序 本篇随笔简要讲解一下信息学奥林匹克竞赛中有关树的DFS序的相关内容. DFS序的概念 先来上张图: 树的DFS序,简单来讲就是对树从根开始进行深搜,按搜到的时间顺序把所有节点打上时间戳. ...
- Python thread & process
线程 点击查看 <- 进程 点击查看 <- 线程与进程的区别 线程共享内部空间:进程内存空间独立 同一个进程的线程之间可以直接交流:两个进程之间想通信必须通过一个中间代理 创建新线程很简单 ...
- 【oracle】DATE输出是什么东西
SELECT TO_CHAR(SYSDATE) FROM DUAL;
- Vue.js 创建第一个应用
VUE官网下载Vue.js文件或者用Vue的CDN地址 在项目中引入Vue.js文件 代码: <!doctype html> <html lang="en"> ...
- MNIST-神经网络的经典实践
MNIST手写体数字识别是神经网络的一个经典的入门案例,堪称深度学习界的”Hello Word任务”. 本博客基于python语言,在TensorFlow框架上对其进行了复现,并作了详细的注释,希望有 ...
- k8s云集群混搭模式落地分享
在 <k8s云集群混搭模式,可能帮你节省50%以上的服务成本>一文中,介绍了使用k8s + 虚拟节点混合集群的方式,为负载具有时间段波峰.波谷交替规律的业务节约成本,提高服务伸缩效率的部署 ...
- Go 程序编译成 DLL 供 C# 调用。
Go 程序编译成 DLL 供 C# 调用. C# 结合 Golang 开发 1. 实现方式与语法形式 基本方式:将 Go 程序编译成 DLL 供 C# 调用. 1.1 Go代码 注意:代码中 ex ...