Mysql数据库索引IS NUll ,IS NOT NUll ,!= 是否走索引
声明在前面
总结就是 不能单纯说 走和不走,需要看数据库版本,数据量等 ,希望不要引起大家的误会,也不要被标题党误导了。
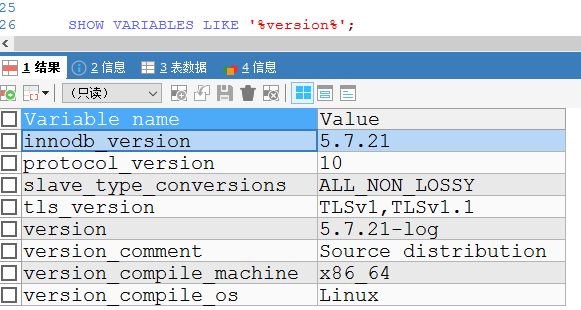
1 数据库版本:
2 建表语句
CREATE TABLE s1 (
id INT NOT NULL AUTO_INCREMENT,
key1 VARCHAR(200),
key2 VARCHAR(200),
key3 VARCHAR(200),
key_part1 VARCHAR(200),
key_part2 VARCHAR(200),
key_part3 VARCHAR(200),
common_field VARCHAR(200),
PRIMARY KEY (id)
) ENGINE=INNODB CHARSET=utf8;
3 建索引语句
CREATE INDEX isz_key1 ON s1(key1); CREATE INDEX isz_key2 ON s1(key2); CREATE INDEX isz_key3 ON s1(key3); CREATE INDEX idx_key_part ON s1 (key_part1, key_part2, key_part3);
4 铺底数据
DELIMITER $$ CREATE PROCEDURE pre ()
BEGIN
DECLARE i INT;
SET i = 0;
WHILE
i < 9000 DO
INSERT INTO s1 (
key1,
key2,
key3,
key_part1,
key_part2,
key_part3,
common_field
)
VALUES
(
'a',
'注意应收热热账款状态为有效状态下,应收账款编号与应热热付流水号一一对应,(已结佣、已热热、已失效3种情况为无效热热,其他均为有效状态)',
'cc',
'a应收账款状态为a',
'cc',
'注意应erect账款状态为有效状态下,应收账款编号与应付流水号一一对应,(已结佣、已热热无效、已失效3种情况为热热状态,其他均为有效状态)',
'ddff'
);
SET i = i + 1;
END WHILE;
END $$ CALL pre ();
DROP PROCEDURE pre;
select COUNT(1)FROM s1;
IS NULL ,IS NOT NUll 是否走索引

EXPLAIN SELECT *FROM s1 WHERE s1.`key1` IS NULL; 表里 key1 为is null的总数为0 查询is null 走索引
 EXPLAIN SELECT *FROM s1 WHERE s1.`key1` IS not NULL; 表里 key1 的列 is not null 的总数为0,不存在值为null 查询is not null 不走索引
EXPLAIN SELECT *FROM s1 WHERE s1.`key1` IS not NULL; 表里 key1 的列 is not null 的总数为0,不存在值为null 查询is not null 不走索引
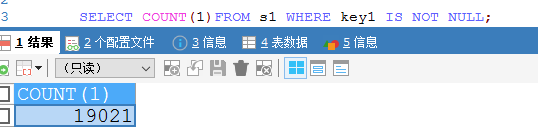
 Is null count为19012条 ,is not count为9条 实验结果 is null 和 is not null 都走索引
Is null count为19012条 ,is not count为9条 实验结果 is null 和 is not null 都走索引
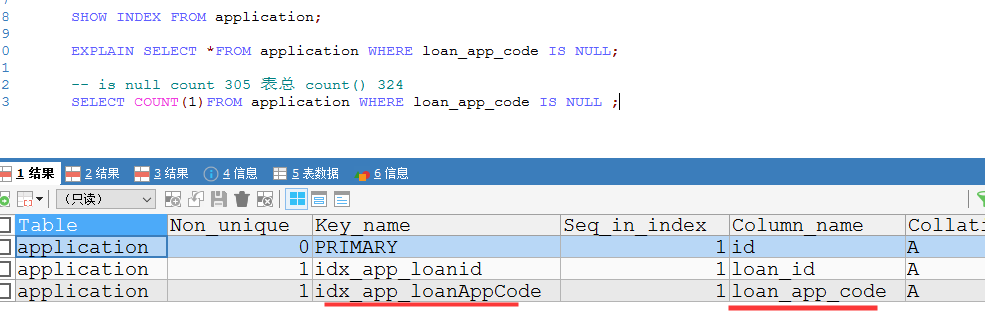
 测试application 表,is null count有305条,表总有324条 ,is null 不走索引
测试application 表,is null count有305条,表总有324条 ,is null 不走索引

总结: 并不是 is null ,is not null走和不走索引是和数据量或者和其他元素有关系(这里我只是测试到和数据量有关系) sql优化器在执行的时候会计算成本,其实和基数,选择性,直方图有关,其实就是看你所搜索的部分占全表的比例是走索引还是全表成本低。
!=走索引吗?
<> 和!= 是同一个意思 ,都是不等于
测试一 <> 走索引,存在<>的数据量有9条

测试二<>走索引存在不等于的数据量有305条
 测试三 <> 不走索引 值都是“abc”,不是“abc”的总条数为0
测试三 <> 不走索引 值都是“abc”,不是“abc”的总条数为0
SELECT COUNT(1)FROM s1 WHERE s1.`key3` ='abc'; -- 0
测试四 <>走索引
总结:并不能一句话说 走和不走,需要看条件,比如数据量,等于“abc”的数据量和不等于“abc”的量,mysql在执行的时候会判断走索引的成本和全表扫描的成本,然后选择成本小的那个
Mysql数据库索引IS NUll ,IS NOT NUll ,!= 是否走索引的更多相关文章
- mysql数据库从删库到跑路之mysq索引
一 介绍 为何要有索引? 一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句 ...
- MYSQL数据库性能调优之四:解决慢查询--索引
为什么索引能够提高查询速度?没有索引 检索数据的方式是从头到尾一条一条挨着匹配,这是慢的根本原因:索引类型BTREE:二叉树类型,原理图如下:对表创建一个二叉树,记录中间数据的物理磁盘地址,二叉树检索 ...
- mysql数据库优化之 如何选择合适的列建立索引
1. 在where 从句,group by 从句,order by 从句,on 从句中出现的列: 2. 索引字段越小越好: 3. 离散度大的列放到联合索引的前面:比如: select * from p ...
- MySql 的SQL执行计划查看,判断是否走索引
在select窗口中,执行以下语句: set profiling =1; -- 打开profile分析工具show variables like '%profil%'; -- 查看是否生效show p ...
- 第二百八十八节,MySQL数据库-索引、limit分页、执行计划、慢日志查询
MySQL数据库-索引.limit分页.执行计划.慢日志查询 索引,是数据库中专门用于帮助用户快速查询数据的一种数据结构.类似于字典中的目录,查找字典内容时可以根据目录查找到数据的存放位置,然后直接获 ...
- 重新学习MySQL数据库4:Mysql索引实现原理
重新学习Mysql数据库4:Mysql索引实现原理 MySQL索引类型 (https://www.cnblogs.com/luyucheng/p/6289714.html) 一.简介 MySQL目前主 ...
- 重新学习Mysql数据库4:Mysql索引实现原理和相关数据结构算法
本文转自互联网 本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 https://github.com/h2pl/Java-Tutorial ...
- mysql 中查询一个字段是否为null的sql
查询mysql数据库表中字段为null的记录: select * 表名 where 字段名 is null 查询mysql数据库表中字段不为null的记录: select * 表名 where 字段名 ...
- MySQL数据库SQL语句基本操作
一.用户管理: 创建用户: create user '用户名'@'IP地址' identified by '密码'; 删除用户: drop user '用户名'@'IP地址'; 修改用户: renam ...
- 百万年薪python之路 -- MySQL数据库之 存储引擎
MySQL之存储引擎 一. 存储引擎概述 定义: 存储引擎是mysql数据库独有的存储数据.为数据建立索引.更新数据.查询数据等技术的实现方法 首先声明一点: 存储引擎这个概念只有MySQL才有. ...
随机推荐
- HBase学习笔记之BulkLoad
HBase学习之BulkLoad bulkload的学习以后再写文章. 参考资料: 1.https://blog.csdn.net/shixiaoguo90/article/details/78038 ...
- 51nod1463 找朋友
[传送门] 写的时候一直没有想到离线解法,反而想到两个比较有趣的解法.一是分块,$f[i][j]$表示第$i$块块首元素到第$j$个元素之间满足条件的最大值(即对$B_l + B_r \in K$的$ ...
- Comet OJ - Contest #14 转转的数据结构题 珂朵莉树+树状数组
题目链接: 题意:有两个操作 操作1:给出n个操作,将区间为l到r的数字改为x 操作2:给出q个操作,输出进行了操作1中的第x到x+y-1操作后的结果 解法: 把询问离线,按照r从小到大排序 每次询问 ...
- 学习Spring-Data-Jpa(十五)---Auditing与@MappedSuperclass
1.Auditing 一般我们针对一张表的操作需要记录下来,是谁修改的,修改时间是什么,Spring-Data为我们提供了支持. 1.1.在实体类中使用Spring-Data为我们提供的四个注解(也可 ...
- web前端开发面试被虐篇(一)
地点:北京 职位:前端开发工程师 要求:达到中级开发,JS基础足够扎实,css基础扎实,要求纯手写代码 面试过程: 进门一个面相老成的大叔递给我一份题,说别的都不好使先做题看看水平,说话语气很温和明显 ...
- 这里是DDOSvoid的blog
由于博主已经退役,博客现由 @一扶苏一 代为维护. DDOSvoid 在生前退役前写下了大量的 blog 存在本地,现在由他的弟子 一扶苏一 整理编纂成为题单慢慢上传,是为<论语>< ...
- Java int 与 Integer 区别
学习借鉴(其实搬了别人的好多)和自己的理解,可能会有较多错误,如有疑问联系我呀. int 是基本数据类型, Integer 是引用类型,也就是一个对象. int 储存的是数值,Integer 储存的 ...
- Automatic Annotation of Airborne Images by Label Propagation Based on a Bayesian-CRF Model
贝叶斯+全连接条件场,无人机和航片数据,通过标注航片数据自动生成无人机标注数据,具体不懂
- Nessus简单使用
1.更新插件 上次搭建完后总觉得不踏实,因为老是提示插件多久没更新了,然后果断花了1.25美刀买了台vps,终于把最新的插件下载下来了,总共190M,需要的QQ私信我.
- D3.js的v5版本入门教程(第九章)——完整的柱状图
D3.js的v5版本入门教程(第九章) 一个完整的柱状图应该包括的元素有——矩形.文字.坐标轴,现在,我们就来一一绘制它们,这章是前面几章的综合,这一章只有少量新的知识点,它们是 d3.scaleBa ...