【Flume学习之一】Flume简介
环境
apache-flume-1.6.0
Flume是分布式日志收集系统。可以将应用产生的数据存储到任何集中存储器中,比如HDFS,HBase;同类工具:Facebook Scribe,Apache chukwa,淘宝Time Tunnel
应用场景图
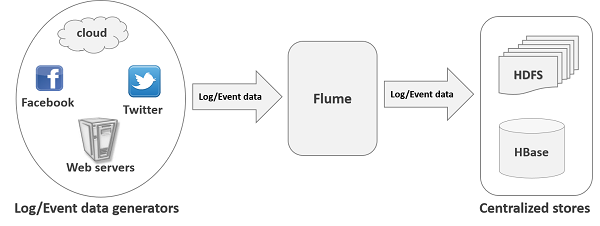
一、Flume核心组件
1、Event: 一个数据单元,消息头和消息体组成。(Events可以是日志记录、 avro 对象等。)
Flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。你可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。
2、Agent
Flume运行的核心是Agent。Flume以agent为最小的独立运行单位,一个agent就是一个JVM,它是一个完整的数据收集工具,含有三个核心组件,分别是source、 channel、 sink。通过这些组件, Event 可以从一个地方流向另一个地方,如下图所示。
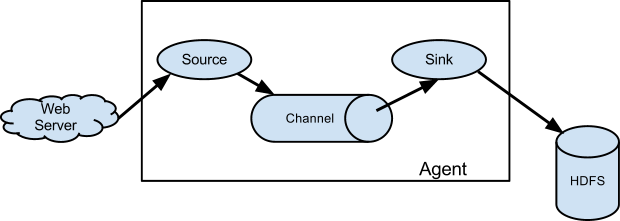
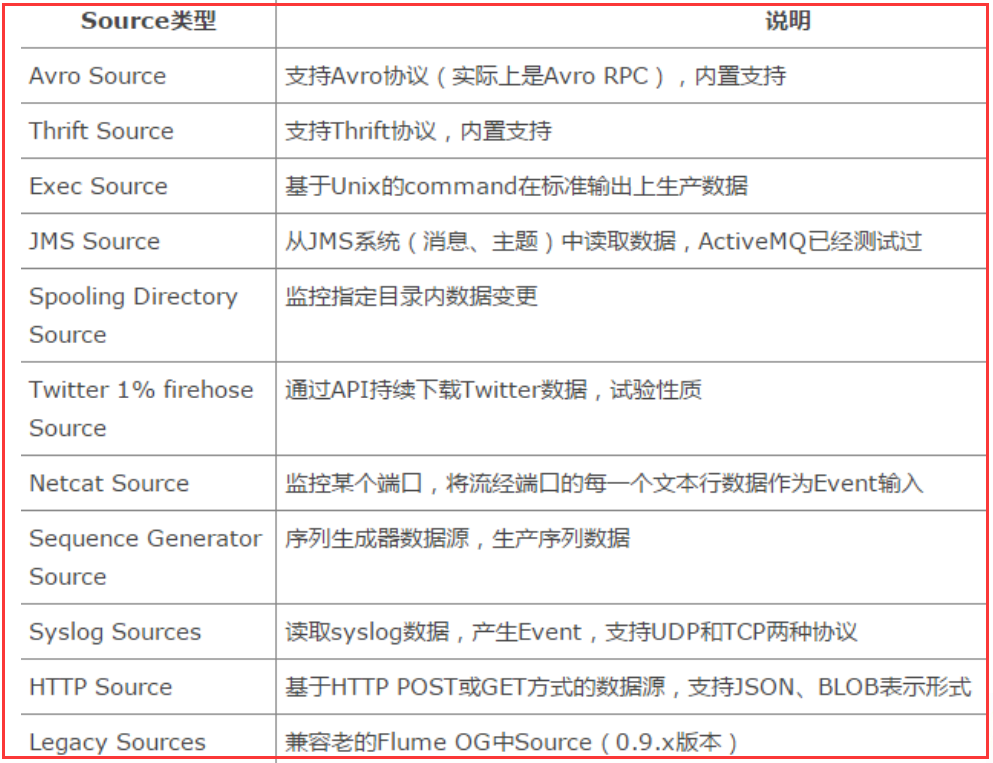
3、Source
Source是数据的收集端,负责将数据捕获后进行特殊的格式化,将数据封装到事件(event) 里,然后将事件推入Channel中。 Flume提供了很多内置的Source, 支持 Avro, log4j, syslog 和 http post(body为json格式)。可以让应用程序同已有的Source直接打交道,如AvroSource,SyslogTcpSource。 如果内置的Source无法满足需要, Flume还支持自定义Source。
4、Channel
Channel是连接Source和Sink的组件,大家可以将它看做一个数据的缓冲区(数据队列),它可以将事件暂存到内存中也可以持久化到本地磁盘上, 直到Sink处理完该事件。介绍两个较为常用的Channel, MemoryChannel和FileChannel。

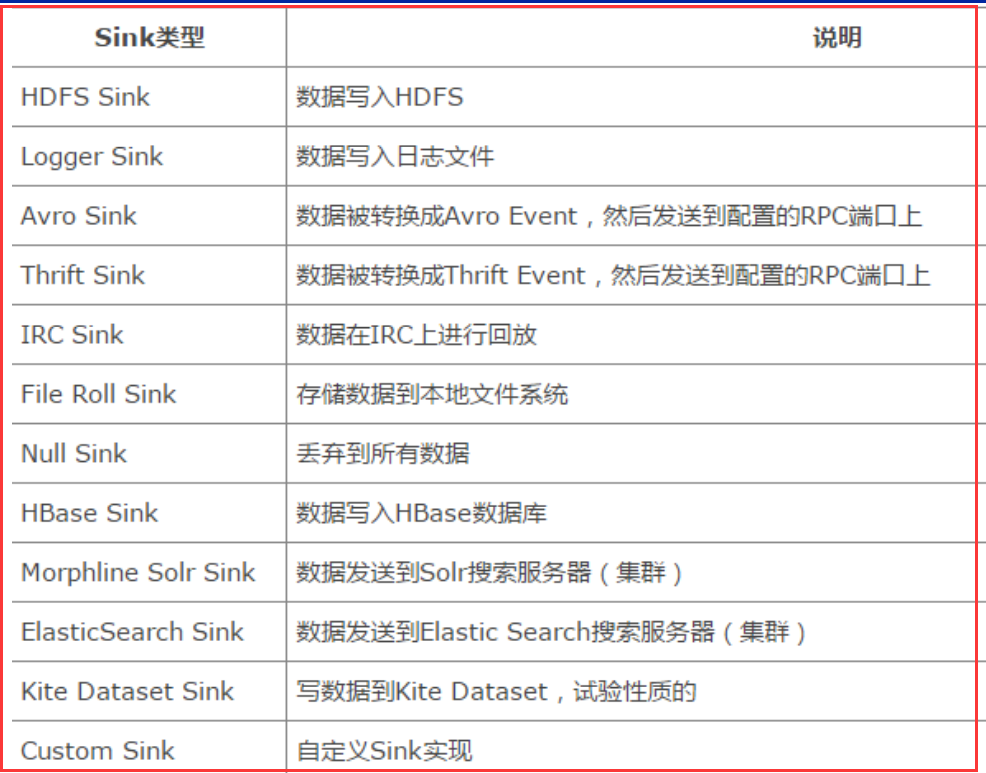
5、Sink
Sink从Channel中取出事件,然后将数据发到别处,可以向文件系统、数据库、 hadoop、hbase存数据, 也可以是其他agent的Source。在日志数据较少时,可以将数据存储在文件系统中,并且设定一定的时间间隔保存数据。
二、Flume 安装
1、解压 apache-flume-1.6.0-bin.tar.gz
[root@node101 src]# tar -zxvf apache-flume-1.6.-bin.tar.gz -C /usr/local/
2、配置jdk路径
[root@node101 conf]# cd /usr/local/apache-flume-1.6.-bin/conf && mv flume-env.sh.template flume-env.sh
[root@node101 conf]# vi flume-env.sh
export JAVA_HOME=/usr/local/jdk1..0_65
注意:JAVA_OPTS 配置 如果我们传输文件过大 报内存溢出时 需要修改这个配置项
3、配置环境变量
[root@node101 apache-flume-1.6.-bin]# vi /etc/profile

[root@node101 bin]# source /etc/profile
4、验证安装是否成功
[root@node101 bin]# flume-ng version
Flume 1.6.
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: 2561a23240a71ba20bf288c7c2cda88f443c2080
Compiled by hshreedharan on Mon May :: PDT
From source with checksum b29e416802ce9ece3269d34233baf43f
三、简单测试示例
1、flume agent配置文件
############################################################
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = # Describe the sink
a1.sinks.k1.type = logger # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
############################################################
Memory Chanel 配置:
capacity:默认该通道中最大的可以存储的event数量是100,
trasactionCapacity:每次最大可以source中拿到或者送到sink中的event数量也是100
keep-alive:event添加到通道中或者移出的允许时间
byte**:即event的字节量的限制,只包括eventbody
2、启动flume
flume-ng agent --conf /usr/local/apache-flume-1.6.0-bin/conf --conf-file /usr/local/apache-flume-1.6.0-bin/conf/option1 --name a1 -Dflume.root.logger=INFO,console
注意:参数的数序不要打乱 否则启动失败或卡住
--name 或 -n 指定agent的名字
--conf 或 -c 指定配置目录
--conf-file 或 -f 指定配置文件名字
-Dflume.root.logger 指定flume日志显示的级别和输出到控制台
[root@node101 conf]# flume-ng agent --conf /usr/local/apache-flume-1.6.-bin/conf --conf-file /usr/local/apache-flume-1.6.-bin/conf/option1 --name a1 -Dflume.root.logger=INFO,console
Info: Sourcing environment configuration script /usr/local/apache-flume-1.6.-bin/conf/flume-env.sh
Info: Including Hive libraries found via () for Hive access
+ exec /usr/local/jdk1..0_80/bin/java -Xmx20m -Dflume.root.logger=INFO,console -cp '/usr/local/apache-flume-1.6.0-bin/conf:/usr/local/apache-flume-1.6.0-bin/lib/*:/lib/*' -Djava.library.path= org.apache.flume.node.Application --conf-file /usr/local/apache-flume-1.6.-bin/conf/option1 --name a1
-- ::, (lifecycleSupervisor--) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider.start(PollingPropertiesFileConfigurationProvider.java:)] Configuration provider starting
-- ::, (conf-file-poller-) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:)] Reloading configuration file:/usr/local/apache-flume-1.6.-bin/conf/option1
-- ::, (conf-file-poller-) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:)] Added sinks: k1 Agent: a1
-- ::, (conf-file-poller-) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:)] Processing:k1
-- ::, (conf-file-poller-) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:)] Processing:k1
-- ::, (conf-file-poller-) [INFO - org.apache.flume.conf.FlumeConfiguration.validateConfiguration(FlumeConfiguration.java:)] Post-validation flume configuration contains configuration for agents: [a1]
-- ::, (conf-file-poller-) [INFO - org.apache.flume.node.AbstractConfigurationProvider.loadChannels(AbstractConfigurationProvider.java:)] Creating channels
-- ::, (conf-file-poller-) [INFO - org.apache.flume.channel.DefaultChannelFactory.create(DefaultChannelFactory.java:)] Creating instance of channel c1 type memory
-- ::, (conf-file-poller-) [INFO - org.apache.flume.node.AbstractConfigurationProvider.loadChannels(AbstractConfigurationProvider.java:)] Created channel c1
-- ::, (conf-file-poller-) [INFO - org.apache.flume.source.DefaultSourceFactory.create(DefaultSourceFactory.java:)] Creating instance of source r1, type netcat
-- ::, (conf-file-poller-) [INFO - org.apache.flume.sink.DefaultSinkFactory.create(DefaultSinkFactory.java:)] Creating instance of sink: k1, type: logger
-- ::, (conf-file-poller-) [INFO - org.apache.flume.node.AbstractConfigurationProvider.getConfiguration(AbstractConfigurationProvider.java:)] Channel c1 connected to [r1, k1]
-- ::, (conf-file-poller-) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:)] Starting new configuration:{ sourceRunners:{r1=EventDrivenSourceRunner: { source:org.apache.flume.source.NetcatSource{name:r1,state:IDLE} }} sinkRunners:{k1=SinkRunner: { policy:org.apache.flume.sink.DefaultSinkProcessor@71ae13c0 counterGroup:{ name:null counters:{} } }} channels:{c1=org.apache.flume.channel.MemoryChannel{name: c1}} }
-- ::, (conf-file-poller-) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:)] Starting Channel c1
-- ::, (lifecycleSupervisor--) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:)] Monitored counter group for type: CHANNEL, name: c1: Successfully registered new MBean.
-- ::, (lifecycleSupervisor--) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:)] Component type: CHANNEL, name: c1 started
-- ::, (conf-file-poller-) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:)] Starting Sink k1
-- ::, (conf-file-poller-) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:)] Starting Source r1
-- ::, (lifecycleSupervisor--) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:)] Source starting
-- ::, (lifecycleSupervisor--) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:)] Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:]
3、使用Telnet测试
[root@node101 ~]# telnet localhost
Trying ::...
telnet: connect to address ::: Connection refused
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
hello
OK
wjy
OK
haha
OK
^]
telnet> quit
Connection closed.
[root@node101 ~]#
flume控制台:
-- ::, (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:)] Event: { headers:{} body: 6C 6C 6F 0D hello. }
-- ::, (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:)] Event: { headers:{} body: 6A 0D wjy. }
-- ::, (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:)] Event: { headers:{} body: 0D haha. }
注意:先启动flume 44444 然后再telenet,否则Connection refused
退出: 按组合键 ctrl+] 出现
^]
telnet>
再输入quit即可退出
参考:
【Flume学习之一】Flume简介的更多相关文章
- Flume学习总结
Flume学习总结 flume是一个用来采集数据的软件,它可以从数据源采集数据到一个集中存放的地方. 最常用flume的数据采集场景是对日志的采集,不过,lume也可以用来采集其他的各种各样的数据,因 ...
- Apache Flume日志收集系统简介
Apache Flume是一个分布式.可靠.可用的系统,用于从大量不同的源有效地收集.聚合.移动大量日志数据进行集中式数据存储. Flume简介 Flume的核心是Agent,Agent中包含Sour ...
- 大数据技术之_09_Flume学习_Flume概述+Flume快速入门+Flume企业开发案例+Flume监控之Ganglia+Flume高级之自定义MySQLSource+Flume企业真实面试题(重点)
第1章 Flume概述1.1 Flume定义1.2 Flume组成架构1.2.1 Agent1.2.2 Source1.2.3 Channel1.2.4 Sink1.2.5 Event1.3 Flum ...
- flume学习(三):flume将log4j日志数据写入到hdfs(转)
原文链接:flume学习(三):flume将log4j日志数据写入到hdfs 在第一篇文章中我们是将log4j的日志输出到了agent的日志文件当中.配置文件如下: tier1.sources=sou ...
- Flume学习应用:Java写日志数据到MongoDB
概述 Windows平台:Java写日志到Flume,Flume最终把日志写到MongoDB. 系统环境 操作系统:win7 64 JDK:1.6.0_43 资源下载 Maven:3.3.3下载.安装 ...
- flume学习笔记——安装和使用
Flume是一个分布式.可靠.和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力. Flume是一 ...
- Apache Flume 学习笔记
# 从http://flume.apache.org/download.html 下载flume ############################################# # 概述: ...
- Apache Flume 学习
Apache Flume,又称Flume NG (next generation),前身是Cloudera公司的Flume项目 -- 又称Flume OG. 这货的功能就是从源中将数据收集到指定的目的 ...
- 【Flume学习之二】Flume 使用场景
环境 apache-flume-1.6.0 一.多agent连接 1.node101配置 option2 # Name the components on this agent a1.sources ...
随机推荐
- Spark 基础 —— 创建 DataFrame 的三种方式
1.自定义 schema(Rdd[Row] => DataSet[Row]) import org.apache.spark.sql.types._ val peopleRDD = spark. ...
- vue 选择之单选,多选,反选,全选,反选
1.单选 当我们用v-for渲染一组数据的时候,我们可以带上index以便区分他们我们这里利用这个index来简单地实现单选. <li v-for="(item,index) in r ...
- (生鲜项目)05. RESTful api, 和 VUE
第一步: 什么是 RESTful api 总结: 使用http协议作为介质, 达到客户端修改服务器端资源的目的, 服务器只需要提供指定的api接口, 客户端根据http协议中的post/get/put ...
- Spark-源码分析01-Luanch Driver
1.SparkSubmit.scala 什么是Driver 呢?其实application运行的进程 就是driver,也是我们所写的代码就是Driver. object DefaultPartiti ...
- C++编译器和连接器原理
本文转载自新浪永远即等待的博客 几个概念: 1.编译:编译器对源文件进行编译,就是把源文件中的文本形式存在的源代码翻译成机器语言形式的目标文件的过程,在这个过程中,编译器会进行一系列的语法检查.如果 ...
- a list of frequently asked questions about Circus
转自:https://circus.readthedocs.io/en/latest/faq/,可以帮助我们了解circus 的使用,以及问题解决 How does Circus stack comp ...
- zabbix显示 get value from agent failed:cannot connetct to xxxx:10050:[4] interrupted system call
在阿里云上部署的两台云主机,从server上 agent.ping不通agent10050端口,在agent上使用firewalld-cmd 添加了10050端口还不行,关闭了防火墙和selinux也 ...
- SQL基础-连接表
一.连接表 1.SQL JOIN 忘记在哪保存的某位网友的图,先明白SQL JOIN, 2.关于笛卡尔积 笛卡尔积: 两个集合的乘积 重新建student表和teacher表: student表: C ...
- 微信小程序七夕节礼物
VSCode Node.js HbuilderX 安装前端开发环境 [外链图片转存失败(img-aXUJRfXc-1565136341881)(https://upload-images.jiansh ...
- Approximate Search
题目链接:Gym-101492H 动态规划,应该是比较基础的,可是自己就是不会QAQ.... /* 把使用机会当成“花费” */ # include <iostream> # includ ...