爬取 豆瓣电影Top250
目标
学习爬虫,爬豆瓣榜单,获取爬取静态页面信息的能力
豆瓣电影 Top 250 https://movie.douban.com/top250
代码
import requests
from bs4 import BeautifulSoup
def getHTMLText(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return '产生异常' if __name__ == '__main__':
i = 0
urls = ['https://movie.douban.com/top250?start='+str(n)+'&filter=' for n in range(0,250,25)]
for url in urls:
r = getHTMLText(url)
soup = BeautifulSoup(r,'html.parser')
titles = soup.select('div.hd a')
rates = soup.select('span.rating_num')
pics = soup.select('img[width="100"]')
for title,rate,pic in zip(titles,rates,pics):
data={'title':list(title.stripped_strings),
'rate':rate.get_text(),
'pic':pic.get('src')}
i+=1
fileName=str(i)+'_'+data['title'][0]+' '+data['rate']+'分.jpg'
pic1 = requests.get(data['pic'])
with open('G:\\test\\'+fileName,'wb') as photo:
photo.write(pic1.content)
print(data)
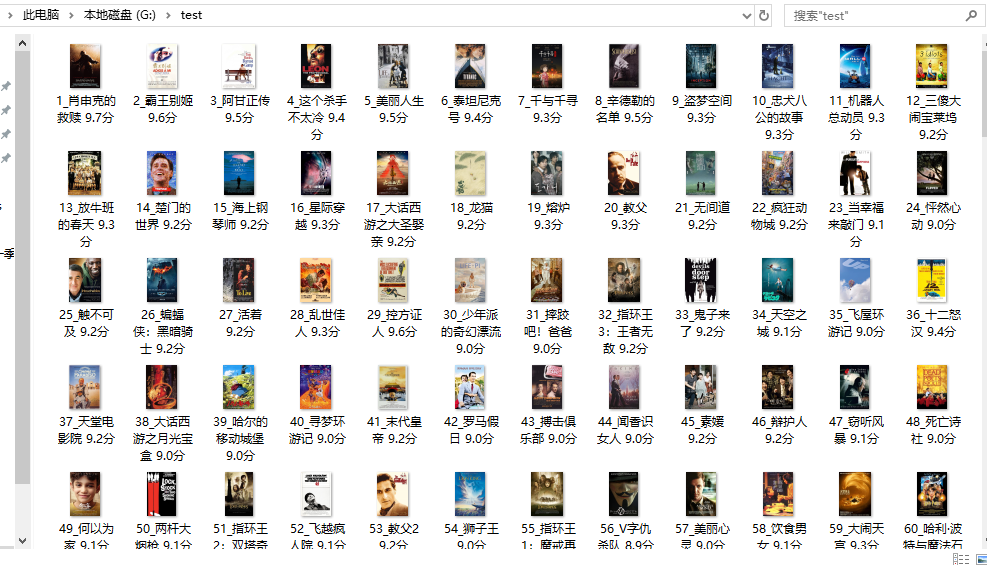
爬取结果
爬取 豆瓣电影Top250的更多相关文章
- urllib+BeautifulSoup无登录模式爬取豆瓣电影Top250
对于简单的爬虫任务,尤其对于初学者,urllib+BeautifulSoup足以满足大部分的任务. 1.urllib是Python3自带的库,不需要安装,但是BeautifulSoup却是需要安装的. ...
- python2.7爬取豆瓣电影top250并写入到TXT,Excel,MySQL数据库
python2.7爬取豆瓣电影top250并分别写入到TXT,Excel,MySQL数据库 1.任务 爬取豆瓣电影top250 以txt文件保存 以Excel文档保存 将数据录入数据库 2.分析 电影 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- scrapy爬取豆瓣电影top250
# -*- coding: utf-8 -*- # scrapy爬取豆瓣电影top250 import scrapy from douban.items import DoubanItem class ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- 【转】爬取豆瓣电影top250提取电影分类进行数据分析
一.爬取网页,获取需要内容 我们今天要爬取的是豆瓣电影top250页面如下所示: 我们需要的是里面的电影分类,通过查看源代码观察可以分析出我们需要的东西.直接进入主题吧! 知道我们需要的内容在哪里了, ...
- Scrapy中用xpath/css爬取豆瓣电影Top250:解决403HTTP status code is not handled or not allowed
好吧,我又开始折腾豆瓣电影top250了,只是想试试各种方法,看看哪一种的方法效率是最好的,一直进行到这一步才知道 scrapy的强大,尤其是和selector结合之后,速度飞起.... 下面我就采用 ...
- Python爬虫入门:爬取豆瓣电影TOP250
一个很简单的爬虫. 从这里学习的,解释的挺好的:https://xlzd.me/2015/12/16/python-crawler-03 分享写这个代码用到了的学习的链接: BeautifulSoup ...
- Scrapy爬虫(4)爬取豆瓣电影Top250图片
在用Python的urllib和BeautifulSoup写过了很多爬虫之后,本人决定尝试著名的Python爬虫框架--Scrapy. 本次分享将详细讲述如何利用Scrapy来下载豆瓣电影To ...
随机推荐
- k8s进入指定pod下的指定容器的命令
访问某pod的某个容器: kubectl --namespace=default exec -it user-deployment-54469dd57-vg87g --container user - ...
- Mybatis-Plus Bugs
Mybatis-Plus Bugs 实体类中属性和数据库字段对应异常 Caused by: java.sql.SQLSyntaxErrorException: Unknown column 'user ...
- c++中#ifndef ... 与#pragma once的区别
原文链接:https://www.cnblogs.com/qiang-upc/p/11407364.html (1)C/C++防止头文件被include多次的方法:#ifnde.. 及 #prag ...
- SpringCloud微服务实现生产者消费者以及ribbon负载均衡
一.SpringCloud_eureka_server 1.导入依赖 <dependencies> <dependency> <groupId>junit</ ...
- oracle--ORA-27125
一,问题描述 ORA-27125 unable to create shared memory segment 二,问题解决 查看系统的oracleid号 [root@dgwxpdb ~]# id o ...
- Oracle--DBV命令行工具用法详解及坏块修复
一,介绍 DBV(DBVERIFY)是Oracle提供的一个命令行工具,它可以对数据文件物理和逻辑两种一致性检查.但是这个工具不会检查索引记录和数据记录的匹配关系,这种检查必须使用analyze va ...
- 框架之jQuery妙用
1.jQuery介绍 jQuery是一个轻量级的.兼容多浏览器的JavaScript库. jQuery使用户能够更方便地处理HTML Document.Events.实现动画效果.方便地进行Ajax交 ...
- 安卓 apk 嵌入H5页面只显示部分
安卓 apk 嵌入H5页面只显示部分(有空白页出现) 解决方案 没有加载的是js部分,需要在安卓那边加上一串代码 webView.getSetting().setDomStorageEnabled(t ...
- Music模块
micro:bit中,MicroPython提供一个Music模块,提供播放音乐的方法,但值得注意的是,控制板上并没有蜂鸣器,所以要外接蜂鸣器,才能听到效果 ,一般接到pin0端口,和gnd地,rob ...
- "中台"论再议
前言:讲中台的太多了,好像似乎不提中台就没法在IT圈混,但对中台又缺少统一明确的定义,姑且听其言,择其精华.最近看到一篇将中台的,觉得还不错,记录下来,分享给大家. 硅谷的“中台论” 在国内创立智领云 ...