爬取 豆瓣电影Top250
目标
学习爬虫,爬豆瓣榜单,获取爬取静态页面信息的能力
豆瓣电影 Top 250 https://movie.douban.com/top250
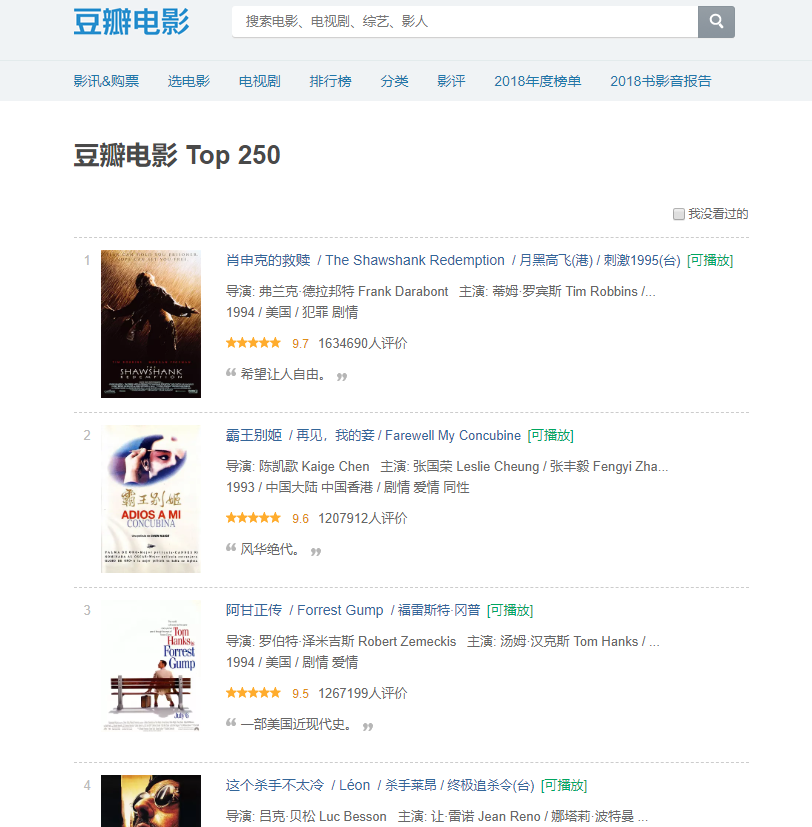
代码
import requests
from bs4 import BeautifulSoup
def getHTMLText(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return '产生异常' if __name__ == '__main__':
i = 0
urls = ['https://movie.douban.com/top250?start='+str(n)+'&filter=' for n in range(0,250,25)]
for url in urls:
r = getHTMLText(url)
soup = BeautifulSoup(r,'html.parser')
titles = soup.select('div.hd a')
rates = soup.select('span.rating_num')
pics = soup.select('img[width="100"]')
for title,rate,pic in zip(titles,rates,pics):
data={'title':list(title.stripped_strings),
'rate':rate.get_text(),
'pic':pic.get('src')}
i+=1
fileName=str(i)+'_'+data['title'][0]+' '+data['rate']+'分.jpg'
pic1 = requests.get(data['pic'])
with open('G:\\test\\'+fileName,'wb') as photo:
photo.write(pic1.content)
print(data)
爬取结果
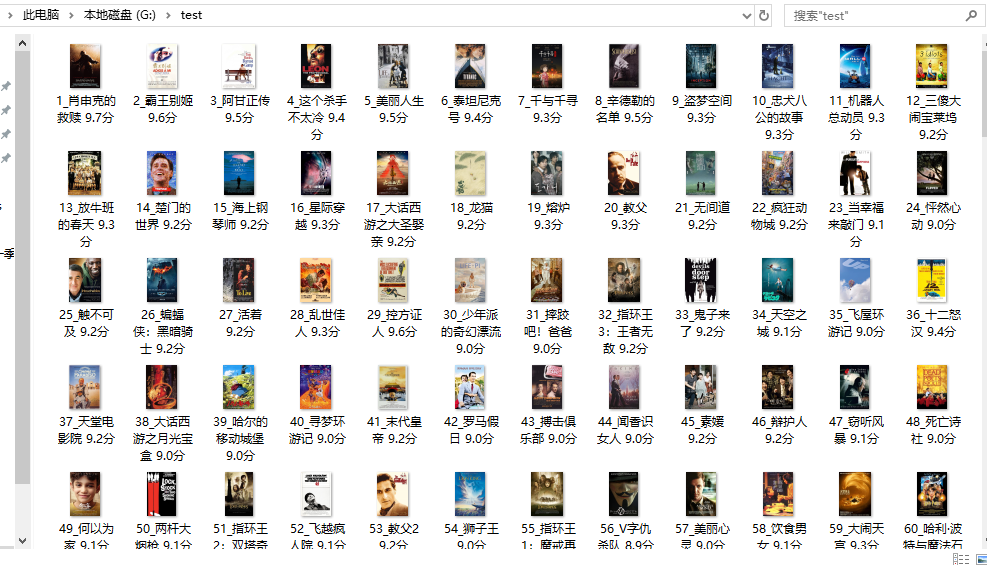
爬取 豆瓣电影Top250的更多相关文章
- urllib+BeautifulSoup无登录模式爬取豆瓣电影Top250
对于简单的爬虫任务,尤其对于初学者,urllib+BeautifulSoup足以满足大部分的任务. 1.urllib是Python3自带的库,不需要安装,但是BeautifulSoup却是需要安装的. ...
- python2.7爬取豆瓣电影top250并写入到TXT,Excel,MySQL数据库
python2.7爬取豆瓣电影top250并分别写入到TXT,Excel,MySQL数据库 1.任务 爬取豆瓣电影top250 以txt文件保存 以Excel文档保存 将数据录入数据库 2.分析 电影 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- scrapy爬取豆瓣电影top250
# -*- coding: utf-8 -*- # scrapy爬取豆瓣电影top250 import scrapy from douban.items import DoubanItem class ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- 【转】爬取豆瓣电影top250提取电影分类进行数据分析
一.爬取网页,获取需要内容 我们今天要爬取的是豆瓣电影top250页面如下所示: 我们需要的是里面的电影分类,通过查看源代码观察可以分析出我们需要的东西.直接进入主题吧! 知道我们需要的内容在哪里了, ...
- Scrapy中用xpath/css爬取豆瓣电影Top250:解决403HTTP status code is not handled or not allowed
好吧,我又开始折腾豆瓣电影top250了,只是想试试各种方法,看看哪一种的方法效率是最好的,一直进行到这一步才知道 scrapy的强大,尤其是和selector结合之后,速度飞起.... 下面我就采用 ...
- Python爬虫入门:爬取豆瓣电影TOP250
一个很简单的爬虫. 从这里学习的,解释的挺好的:https://xlzd.me/2015/12/16/python-crawler-03 分享写这个代码用到了的学习的链接: BeautifulSoup ...
- Scrapy爬虫(4)爬取豆瓣电影Top250图片
在用Python的urllib和BeautifulSoup写过了很多爬虫之后,本人决定尝试著名的Python爬虫框架--Scrapy. 本次分享将详细讲述如何利用Scrapy来下载豆瓣电影To ...
随机推荐
- Maven打包插件Assembly(七)
1. 在 dubbo 的 provider 项目(实现类项目dubbo-service-impl)中 pom.xml 配置 assembly插件信息 <!-- 指定项目的打包插件信息 --> ...
- luoguP4294 [WC2008]游览计划
题意 斯坦纳树裸题. 显然答案是棵树. 设\(f[i][s]\)表示以\(i\)为根,集合为\(s\)的最小代价. 先在同根之间转移: \(f[i][s]=min(f[i][t]+f[i][s\ xo ...
- wafer2的keng
一.之前用wafer2开发的小程序,今天突然Error: 用户未登录过,请先使用 login() 登录? 答:改用qcloud.login, 替换掉qcloud.loginWithCode (小程序代 ...
- Codeforces Round #576 (Div. 1)
Preface 闲来无事打打CF,就近找了场Div1打打 这场感觉偏简单,比赛时艹穿的人都不少,也没有3000+的题 两三个小时就搞完了吧(F用随机水过去了) A. MP3 题意不好理解,没用翻译看了 ...
- [LeetCode] 1028. Recover a Tree From Preorder Traversal 从先序遍历还原二叉树
We run a preorder depth first search on the rootof a binary tree. At each node in this traversal, we ...
- 第09组 Beta冲刺(4/5)
队名:观光队 链接 组长博客 作业博客 组员实践情况 王耀鑫 过去两天完成了哪些任务 文字/口头描述 学习 展示GitHub当日代码/文档签入记录 无 接下来的计划 完成短租车,页面美化 还剩下哪些任 ...
- Golang(十一)TLS 相关知识(二)OpenSSL 生成证书
0. 前言 接前一篇文章,上篇文章我们介绍了数字签名.数字证书等基本概念和原理 本篇我们尝试自己生成证书 参考文献:TLS完全指南(二):OpenSSL操作指南 1. OpenSSL 简介 OpenS ...
- Golang(八)go modules 学习
0. 前言 最近加入鹅厂学习 k8s,组内使用 Go 1.11 以上的 go modules 管理依赖,因此整理了相关资料 本文严重参考原文:初窥Go module 1. 传统 Golang 包依赖管 ...
- Qt Quick 组件与动态对象
博客24## 一.Components(组件) Component 是由 Qt 框架或开发者封装好的.只暴露了必要接口的 QML 类型,可以重复利用.一个 QML 组件就像一个黑盒子,它通过属性.信号 ...
- win10如何将wps设置成默认应用
1.在此之前,我们当然需要下载一个WPS软件了.如果还没有安装软件的,大家可以去网上搜一下“WPS”进入官网下载; 2.下载之后,我们进入开始菜单,然后点击所有应用,找到WPS; 3.之后就会看见“配 ...