朴素贝叶斯算法源码分析及代码实战【python sklearn/spark ML】
一.简介
贝叶斯定理是关于随机事件A和事件B的条件概率的一个定理。通常在事件A发生的前提下事件B发生的概率,与在事件B发生的前提下事件A发生的概率是不一致的。然而,这两者之间有确定的
关系,贝叶斯定理就是这种关系的陈述。其中,L(A|B)表示在B发生的前提下,A发生的概率。L表示要取对数的意思。
关键词解释:
1.p(A),p(B)表示A,B发生的概率,也称先验概率或边缘概率。
2.p(B|A)表示在A发生的前提下,B发生的概率,也称后验概率。
基本公式:p(A|B) = p(AB)/p(B)
图解:

备注:p(AB) = p(BA)都是指A,B同时发生的概率,所以可得贝叶斯公式:p(B|A) = p(AB)/p(A) = p(A|B)p(B)/p(A)导入数据得 = 0.5*0.4/0.8 = 0.25
贝叶斯公式:p(B|A) = p(A|B)p(B)/p(A)
图解:同上
朴素贝叶斯分类是一种十分简单的分类算法,其算法基础是对于给出的待分类项,求解在此项出现的条件下各类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
实现步骤:

二.代码实现【python】
# -*- coding: utf- -*-
"""
Created on Tue Oct :: @author: zhen
"""
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report
# 数据获取
news = fetch_20newsgroups(subset='all') # 数据预处理:分割训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25, random_state=)
# 文本特征向量化
vec = CountVectorizer()
x_train = vec.fit_transform(x_train)
x_test = vec.transform(x_test) # 使用朴素贝叶斯进行训练(多项式模型)
mnb = MultinomialNB()
mnb.fit(x_train, y_train)
y_predict = mnb.predict(x_test) # 获取预测结果
print(classification_report(y_test, y_predict, target_names = news.target_names))
print("the accuracy of MultinomialNB is:", mnb.score(x_test, y_test))
三.结果【python】

四.代码实现【Spark】
package big.data.analyse.ml
import org.apache.log4j.{Level,Logger}
import org.apache.spark.NaiveBayes
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.ml.feature.LabeledPoint
import org.apache.spark.sql.{SparkSession}
/**
* Created by zhen on 2019/9/9.
*/
object NaiveBayesAnalyse {
Logger.getLogger("org").setLevel(Level.WARN)
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("NaiveBayes").master("local[2]").getOrCreate()
/**
* 加载数据
*/
val test_data_array = Array("0,1.2-0.5-0.2","0,2.1-0.3-0.2","0,3.6-0.1-1.0","0,4.6-0.3-0.2",
"1,0.4-1.5-0.2","1,0.2-2.6-0.8","1,0.6-3.3-0.6","1,0.1-4.3-0.4",
"2,0.1-0.4-1.8","2,0.2-0.4-2.1","2,0.3-0.1-3.3","2,0.5-0.2-4.1")
val sc = spark.sparkContext
val test_data = sc.parallelize(test_data_array).map(row => {
val array = row.split(",")
LabeledPoint(array(0).toDouble,Vectors.dense(array(1).split("-").map(_.toDouble)))
})
/**
* 拆分数据为训练数据和测试数据
*/
val splits = test_data.randomSplit(Array(0.8, 0.2), seed = 11L)
val train = splits(0)
val test = splits(1)
/**
* 创建朴素贝叶斯模型并训练
* 使用多项式模型
*/
val model = NaiveBayes.train(train, lambda = 1.0, modelType = "multinomial")
/**
* 预测
*/
val predict = test.map(row => (row.label, model.predict(row.features)))
val predict_show = predict.take(20)
val test_take = test.take(20)
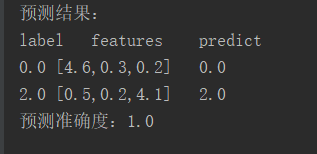
println("预测结果:")
println("label" + "\t" + "features" + "\t" + "predict")
for(i <- 0 until predict_show.length){
println(predict_show(i)._1 + "\t" + test_take(i).features +"\t" + predict_show(i)._2)
}
val acc = 1.0 * predict.filter(row => row._1 == row._2).count() / test.count()
println("预测准确度:"+acc)
}
}
五.模拟源码实现【Spark】
NaiveBayes朴素贝叶斯类:
package org.apache.spark import org.apache.spark.ml.feature.LabeledPoint
import org.apache.spark.ml.linalg.{BLAS, DenseVector, SparseVector, Vector}
import org.apache.spark.rdd.RDD /**
* Created by zhen on 2019/9/11.
*/
object NaiveBayes{
/**
* 多项式模型类别
*/
val Multinomial : String = "multinomial" /**
* 伯努利模式类型
*/
val Bernoulli : String = "bernoulli" /**
* 设置模型支持的类别
*/
val supportedModelTypes = Set(Multinomial, Bernoulli) /**
* 训练一个朴素贝叶斯模型
* @param input 样本RDD
* @return
*/
def train(input : RDD[LabeledPoint]) : NaiveBayesModel = {
new NaiveBayes().run(input)
} /**
* 训练一个朴素贝叶斯模型
* @param input 样本RDD
* @param lambda 平滑系数
* @return
*/
def train(input : RDD[LabeledPoint], lambda : Double) : NaiveBayesModel = {
new NaiveBayes(lambda, Multinomial).run(input)
} /**
* 训练一个朴素贝叶斯模型
* @param input 样本RDD
* @param lambda 平滑系数
* @param modelType 模型类型
* @return
*/
def train(input : RDD[LabeledPoint], lambda : Double, modelType : String) : NaiveBayesModel = {
require(supportedModelTypes.contains(modelType), s"NaiveBayes was created with an unknown modelType:$modelType.")
new NaiveBayes(lambda, modelType).run(input)
}
} /**
* 贝叶斯分类类
* @param lambda 平滑系数
* @param modelType 模型类型
*/
class NaiveBayes private(private var lambda : Double,
private var modelType : String) extends Serializable{ import NaiveBayes.{Bernoulli, Multinomial} def this(lambda : Double) = this(lambda, NaiveBayes.Multinomial) def this() = this(1.0, NaiveBayes.Multinomial) /**
* 设置平滑参数
* @param lambda
* @return
*/
def setLambda(lambda : Double) : NaiveBayes = {
this.lambda = lambda
this
} /**
* 获取平滑参数
* @return
*/
def getLambda : Double = this.lambda /**
* 设置模型类型
* @param modelType
* @return
*/
def setModelType(modelType : String) : NaiveBayes = {
require(NaiveBayes.supportedModelTypes.contains(modelType), s"NaiveBayes was created with an unknown modelType :$modelType.")
this.modelType = modelType
this
} /**
* 获取模型类型
* @return
*/
def getModelType : String = this.modelType /**
* 运行算法
* @param data
* @return
*/
def run(data : RDD[LabeledPoint]) : NaiveBayesModel = {
val requireNonnegativeValues : Vector => Unit = (v : Vector) => {
val values = v match {
case sv : SparseVector => sv.values
case dv : DenseVector => dv.values
}
if(!values.forall(_ >= 0.0)){
throw new SparkException(s"Naive Bayes requires nonnegative feature values but found $v.")
}
} val requireZeroOneBernoulliValues : Vector => Unit = (v : Vector) => {
val values = v match{
case sv : SparseVector => sv.values
case dv : DenseVector => dv.values
}
if(!values.forall(v => v == 0.0 || v == 1.0)){
throw new SparkException(s"Bernoulli naive Bayes requires 0 or 1 feature values but found $v.")
}
} /**
* 对每个标签进行聚合操作,求得每个标签标签对应特征的频数
* 以label为key,聚合同一个label的features,返回(label, (计数, features之和))
*/
println("训练数据:")
data.foreach(println)
val aggregated = data.map(row => (row.label, row.features))
.combineByKey[(Long, DenseVector)](
createCombiner = (v : Vector) => { //完成样本从v到c的转化:(v:Vector) -> (c:(Long, DenseVector))
if(modelType == Bernoulli){
requireZeroOneBernoulliValues(v)
}else{
requireNonnegativeValues(v)
}
(1L, v.copy.toDense)
},
mergeValue = (c : (Long, DenseVector), v : Vector) => { // 合并
requireNonnegativeValues(v)
BLAS.axpy(1.0, v, c._2)
(c._1 + 1L, c._2)
},
mergeCombiners = (c1 : (Long, DenseVector), c2 : (Long, DenseVector)) => {
BLAS.axpy(1.0, c2._2, c1._2)
(c1._1 + c2._1, c1._2)
}
).collect() val numLabels = aggregated.length // 类别标签数量 var numDocuments = 0L // 文档数量
aggregated.foreach{case (_, (n, _)) =>
numDocuments += n
} val numFeatures = aggregated.head match {case (_, (_, v)) => v.size} // 特征数量 val labels = new Array[Double](numLabels) // 标签列表列表 val pi = new Array[Double](numLabels) // pi类别的先验概率 val theta = Array.fill(numLabels)(new Array[Double](numFeatures)) // theta各个特征在类别中的条件概率 val piLogDenom = math.log(numDocuments + numLabels * lambda) //聚合计算theta var i = 0
aggregated.foreach{case (label, (n, sumTermFreqs)) =>
labels(i) = label
pi(i) = math.log(n + lambda) - piLogDenom // 计算先验概率,并取log
val thetaLogDenom = modelType match {
case Multinomial => math.log(sumTermFreqs.values.sum + numFeatures * lambda) // 多项式模型
case Bernoulli => math.log(n + 2.0 * lambda) // 伯努利模型
case _ => throw new UnknownError(s"Invalid modeType: $modelType.")
}
var j = 0
while(j < numFeatures){
theta(i)(j) = math.log(sumTermFreqs(j) + lambda) - thetaLogDenom // 计算各个特征在各个类别中的条件概率
j += 1
}
i+= 1
}
new NaiveBayesModel(labels, pi, theta, modelType)
}
}
NaiveBayesModel朴素贝叶斯模型类:
package org.apache.spark
import org.apache.spark.ml.linalg.{BLAS, Vector, DenseMatrix, DenseVector}
import org.apache.spark.mllib.util.Saveable
import org.apache.spark.rdd.RDD
/**
* Created by zhen on 2019/9/12.
*/
class NaiveBayesModel private[spark](
val labels : Array[Double],
val pi : Array[Double],
val theta : Array[Array[Double]],
val modelType : String
) extends Serializable with Saveable{
import NaiveBayes.{Bernoulli, Multinomial, supportedModelTypes}
private val piVector = new DenseVector(pi) // 类别的先验概率
private val thetaMatrix = new DenseMatrix(labels.length, theta(0).length, theta.flatten, true) // 各个特征在各个类别的条件概率
private[spark] def this(labels:Array[Double], pi:Array[Double], theta:Array[Array[Double]]) = this(labels, pi, theta, NaiveBayes.Multinomial)
/**
* java接口的构造函数
*/
private[spark] def this(
labels : Iterable[Double],
pi : Iterable[Double],
theta : Iterable[Iterable[Double]]
) = this(labels.toArray, pi.toArray, theta.toArray.map(_.toArray))
require(supportedModelTypes.contains(modelType), s"Invalid modelType $modelType.Supported modelTypes are $supportedModelTypes.")
/**
* 伯努利模型额外处理
*/
private val (thetaMinusNegTheta, negThetaSum) = modelType match {
case Multinomial => (None, None)
case Bernoulli =>
val negTheta = thetaMatrix.map(value => math.log(1.0 - math.exp(value)))
val ones = new DenseVector(Array.fill(thetaMatrix.numCols){1.0})
val thetaMinusNegTheta = thetaMatrix.map{value => value - math.log(1.0 - math.exp(value))}
(Option(thetaMinusNegTheta), Option(negTheta.multiply(ones)))
case _ => throw new UnknownError(s"Involid modelType: $modelType.")
}
/**
* 对样本RDD进行预测
*/
def predict(testData : RDD[Vector]) : RDD[Double] = {
val bcModel = testData.context.broadcast(this)
testData.mapPartitions{ iter =>
val model = bcModel.value
iter.map(model.predict) // 调用参数为一个样本的predict
}
}
/**
* 根据一个样本的特征向量进行预测
*/
def predict(testData : Vector) : Double = {
modelType match {
case Multinomial =>
val prob = thetaMatrix.multiply(testData)
RBLAS.axpy(1.0, piVector, prob)
labels(prob.argmax)
case Bernoulli =>
testData.foreachActive{(index, value) =>
if(value != 0.0 && value != 1.0){
throw new SparkException(s"Bernouslli naive Bayes requires 0 or 1 feature values but found $testData.")
}
}
val prob = thetaMinusNegTheta.get.multiply(testData)
BLAS.axpy(1.0, piVector, prob)
BLAS.axpy(1.0, negThetaSum.get, prob)
labels(prob.argmax)
case _ =>
throw new UnknownError(s"Involid modelType: $modelType.")
}
}
/**
* 保存模型
*/
def save(sc : SparkContext, path : String) : Unit = {
//val data = NaiveBayesModel.SaveLoadV2_0.Data(labels, pi, theta, modelType)
//NaiveBayesModel.SaveLoadV2_0.save(sc, path, data)
}
override protected def formatVersion : String = "2.0"
}
六.结果【Spark】

朴素贝叶斯算法源码分析及代码实战【python sklearn/spark ML】的更多相关文章
- 朴素贝叶斯算法下的情感分析——C#编程实现
这篇文章做了什么 朴素贝叶斯算法是机器学习中非常重要的分类算法,用途十分广泛,如垃圾邮件处理等.而情感分析(Sentiment Analysis)是自然语言处理(Natural Language Pr ...
- C#编程实现朴素贝叶斯算法下的情感分析
C#编程实现 这篇文章做了什么 朴素贝叶斯算法是机器学习中非常重要的分类算法,用途十分广泛,如垃圾邮件处理等.而情感分析(Sentiment Analysis)是自然语言处理(Natural Lang ...
- 朴素贝叶斯算法--python实现
朴素贝叶斯算法要理解一下基础: [朴素:特征条件独立 贝叶斯:基于贝叶斯定理] 1朴素贝叶斯的概念[联合概率分布.先验概率.条件概率**.全概率公式][条件独立性假设.] 极大似然估计 ...
- Python机器学习笔记:朴素贝叶斯算法
朴素贝叶斯是经典的机器学习算法之一,也是为数不多的基于概率论的分类算法.对于大多数的分类算法,在所有的机器学习分类算法中,朴素贝叶斯和其他绝大多数的分类算法都不同.比如决策树,KNN,逻辑回归,支持向 ...
- 【十大算法实现之naive bayes】朴素贝叶斯算法之文本分类算法的理解与实现
关于bayes的基础知识,请参考: 基于朴素贝叶斯分类器的文本聚类算法 (上) http://www.cnblogs.com/phinecos/archive/2008/10/21/1315948.h ...
- Python机器学习算法 — 朴素贝叶斯算法(Naive Bayes)
朴素贝叶斯算法 -- 简介 朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法.最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Baye ...
- 朴素贝叶斯算法java实现(多项式模型)
网上有很多对朴素贝叶斯算法的说明的文章,在对算法实现前,参考了一下几篇文章: NLP系列(2)_用朴素贝叶斯进行文本分类(上) NLP系列(3)_用朴素贝叶斯进行文本分类(下) 带你搞懂朴素贝叶斯分类 ...
- 什么是机器学习的分类算法?【K-近邻算法(KNN)、交叉验证、朴素贝叶斯算法、决策树、随机森林】
1.K-近邻算法(KNN) 1.1 定义 (KNN,K-NearestNeighbor) 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类 ...
- 【数据挖掘】朴素贝叶斯算法计算ROC曲线的面积
题记: 近来关于数据挖掘学习过程中,学习到朴素贝叶斯运算ROC曲线.也是本节实验课题,roc曲线的计算原理以及如果统计TP.FP.TN.FN.TPR.FPR.ROC面积等等.往往运用 ...
随机推荐
- ARM USB 通信(转)
ARM USB 通信 采用ZLG的动态链接库,动态装载. ARM是Context-M3-1343. 在C++ Builder 6 中开发的上位机通信软件. USB通信代码如下: //--------- ...
- Win10 LTSC 2019 长期支持版
win 10 LTSB 2016 文件名:cn_windows_10_enterprise_2016_ltsb_x86_dvd_9057089.iso (2.62GB) 语言: Chinese – S ...
- egg.js 相关
egg sequelize 建表规范 CREATE TABLE `wx_member` ( `id` ) NOT NULL AUTO_INCREMENT COMMENT 'primary key' ...
- matlab学习笔记6--性能剖析
一起来学matlab-matlab学习笔记6 性能剖析 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考书籍 <matlab 程序设计与综合应用>张德丰等著 感谢张老师的书籍, ...
- springboot 整合Elasticsearch
Elasticsearch Elasticsearch 是一个分布式.可扩展.实时的搜索与数据分析引擎. 它能从项目一开始就赋予你的数据以搜索.分析和探索的能力,可用于实现全文搜索和实时数据统计. 在 ...
- postgrelsql 的 wm_concat : string_agg
string_agg,array_agg 这两个函数的功能大同小异,只不过合并数据的类型不同 array_agg(expression) 把表达式变成一个数组 一般配合 array_to_string ...
- [LeetCode] 93. Restore IP Addresses 复原IP地址
Given a string containing only digits, restore it by returning all possible valid IP address combina ...
- RDB和AOF持久化
RDB和AOF持久化 https://www.cnblogs.com/Tu9oh0st/p/11229317.html Redis提供了不同的持久化选项: RDB持久化以指定的时间间隔保存那个时间点的 ...
- 基于Mac的Appium环境搭建(java)
一.jdk安装 1.下载地址 http://www.oracle.com/technetwork/java/javase/downloads/index.html 2.安装 3.配置环境变量: ope ...
- LeetCode 503. 下一个更大元素 II(Next Greater Element II)
503. 下一个更大元素 II 503. Next Greater Element II 题目描述 给定一个循环数组(最后一个元素的下一个元素是数组的第一个元素),输出每个元素的下一个更大元素.数字 ...