spark 机器学习 决策树 原理(一)
1.什么是决策树
决策树(decision tree)是一个树结构(可以是二叉树或者非二叉树)。决策树分为分类树和回归树两种,分类树对离散变量做决策树,回归树对连续变量做决策树。
其中每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放在一个类别。
使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,知道到达叶子节点,将叶子节点存放的类别作为决策结果。
决策树学习算法主要由三部分构成
1.1特征选择
特征选择是指从训练数据中众多的特征中选择一个特征作为当前节点的分裂标准,如何选择特征有着很多不同量化评估标准,从而衍生出不同的决策树算法。
1.2决策树生成
根据选择的特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树停止生长。树结构来说,递归结构是最容易理解的方式。
1.3决策树的剪枝
决策树容易过拟合,一般来需要剪枝,缩小树结构规则,缓解过拟合,剪枝技术有预剪枝和后剪枝两种。
2.例子
一天,老师问了个问题,只根据头发和声音怎么判断一位同学的性别。
为了解决这个问题,同学们马上简单的统计了7位同学的相关特征,数据如下: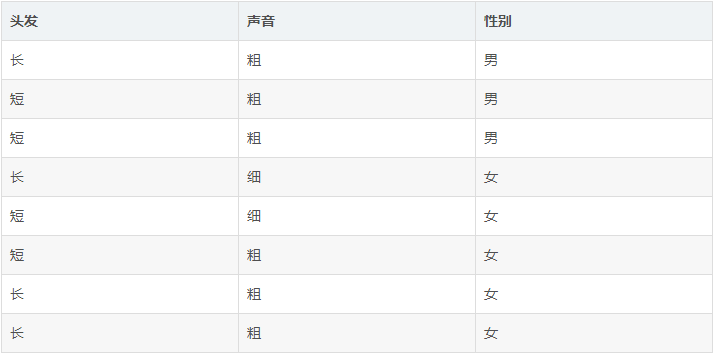
同学A想了想,先根据头发判断,若判断不出,再根据声音判断,于是画了一幅图,如下: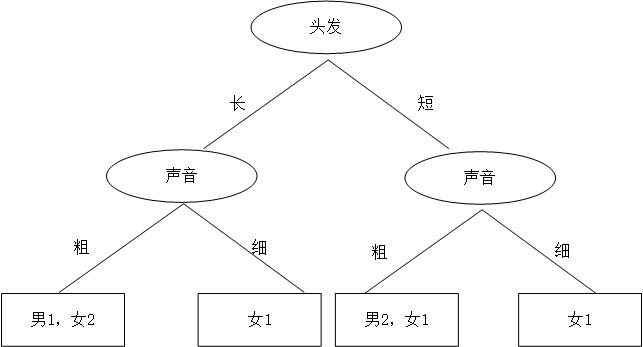
同学B,想先根据声音判断,然后再根据头发来判断,如是大手一挥也画了个决策树: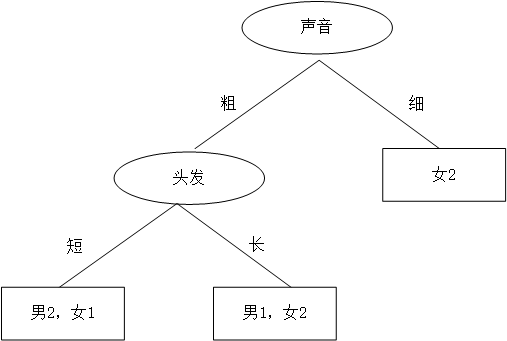
同学A和同学B谁的决策树好些?
3.决策树的特征选择
我们可以使用多种方法划分数据集,但是每种方法都有各自的优缺点。于是我们这么想,如果我们能测量数据的复杂度,对比按不同特征分类后的数据复杂度,若按某一特征分类后复杂度减少的更多,那么这个特征即为最佳分类特征。
Claude Shannon 定义了熵(entropy)和信息增益(information gain)。
3.1信息熵
首先了解一下信息量:信息量是对信息的度量,就跟时间的度量是秒一样,当我们考虑一个离散的随机变量 x 的时候,当我们观察到的这个变量的一个具体值的时候,我们接收到了多少信息呢?
信息的大小跟随机事件的概率有关。越小概率的事情发生了产生的信息量越大,如中国足球队勇夺世界杯冠军,越大概率的事情发生了产生的信息量越小,如太阳从东边升起来了(肯定发生嘛, 没什么信息量)。
在信息论与概率论中,熵(entropy)用于表示“随机变量不确定性的度量”
X代表样本总数据量,n代表结果分类,p(xi)代表xi的概率(就是结果其中一个分类的概率):
例子: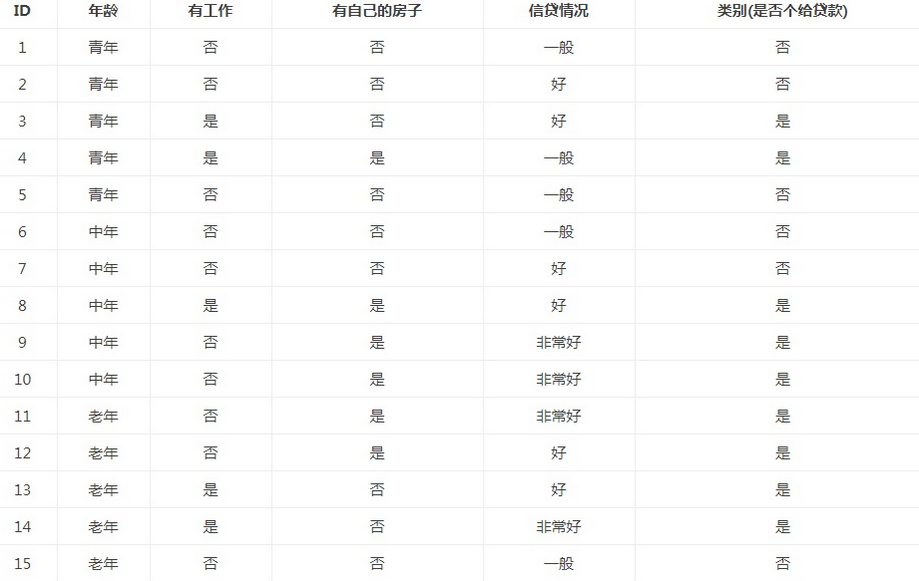
在15个数据中,结果分类为2个,放贷或不放贷,9个数据的结果为放贷,6个数据的结果为不放贷。所以数据集X的信息熵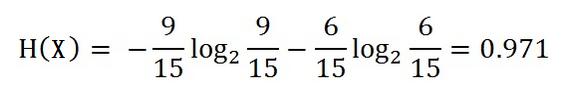
3.2信息增益(information gain)
我们已经说过,如何选择特征,需要看信息增益。也就是说,信息增益是相对于特征而言的,信息增益越大,特征对最终的分类结果影响也就越大,我们就应该选择对最终分类结果影响最大的那个特征作为我们的分类特征。
在讲解信息增益定义之前,我们还需要明确一个概念,条件熵。
接下来,让我们说说信息增益。前面也提到了,信息增益是相对于特征而言的。所以,特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差,即:
以贷款申请样本数据表为例进行说明。看下年龄这一列的数据,也就是特征A1,一共有三个类别,分别是:青年、中年和老年。我们只看年龄是青年的数据,年龄是青年的数据一共有5个,所以年龄是青年的数据在训练数据集出现的概率是十五分之五,也就是三分之一。同理,年龄是中年和老年的数据在训练数据集出现的概率也都是三分之一。现在我们只看年龄是青年的数据的最终得到贷款的概率为五分之二,因为在五个数据中,只有两个数据显示拿到了最终的贷款,同理,年龄是中年和老年的数据最终得到贷款的概率分别为五分之三、五分之四。所以计算年龄的信息增益,过程如下: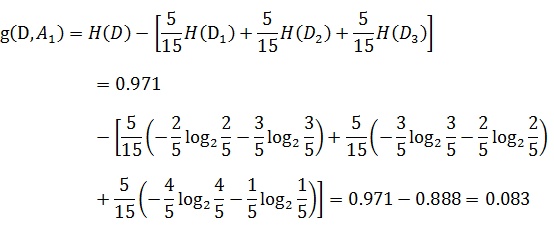
同理,计算其余特征的信息增益g(D,A2)、g(D,A3)和g(D,A4)。分别为: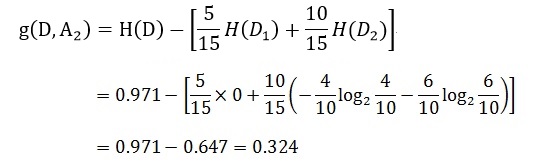


最后,比较特征的信息增益,由于特征A3(有自己的房子)的信息增益值最大,所以选择A3作为最优特征。
spark 机器学习 决策树 原理(一)的更多相关文章
- spark 机器学习 ALS原理(一)
1.线性回归模型线性回归是统计学中最常用的算法,当你想表示两个变量间的数学关系时,就可以用线性回归.当你使用它时,你首先假设输出变量(相应变量.因变量.标签)和预测变量(自变量.解释变量.特征)之间存 ...
- spark 机器学习 knn原理(一)
1.knnK最近邻(k-Nearest Neighbor,KNN)分类算法,在给定一个已经做好分类的数据集之后,k近邻可以学习其中的分类信息,并可以自动地给未来没有分类的数据分好类.我们可以把用户分 ...
- 【Spark机器学习速成宝典】模型篇05决策树【Decision Tree】(Python版)
目录 决策树原理 决策树代码(Spark Python) 决策树原理 详见博文:http://www.cnblogs.com/itmorn/p/7918797.html 返回目录 决策树代码(Spar ...
- 机器学习实战(Machine Learning in Action)学习笔记————03.决策树原理、源码解析及测试
机器学习实战(Machine Learning in Action)学习笔记————03.决策树原理.源码解析及测试 关键字:决策树.python.源码解析.测试作者:米仓山下时间:2018-10-2 ...
- 掌握Spark机器学习库(课程目录)
第1章 初识机器学习 在本章中将带领大家概要了解什么是机器学习.机器学习在当前有哪些典型应用.机器学习的核心思想.常用的框架有哪些,该如何进行选型等相关问题. 1-1 导学 1-2 机器学习概述 1- ...
- 决策树原理、Scikit-learn实现及其在生物信息中的应用
之前转过一篇文章:2016年GitHub排名前20的Python机器学习开源项目(转),说明现在已经有了很多很好的机器学习的包,我们不必从底层开始实现,只要懂点算法.会看文档,一般人也能玩好机器学习. ...
- Spark机器学习之协同过滤算法
Spark机器学习之协同过滤算法 一).协同过滤 1.1 概念 协同过滤是一种借助"集体计算"的途径.它利用大量已有的用户偏好来估计用户对其未接触过的物品的喜好程度.其内在思想是相 ...
- Spark机器学习解析下集
上次我们讲过<Spark机器学习(上)>,本文是Spark机器学习的下部分,请点击回顾上部分,再更好地理解本文. 1.机器学习的常见算法 常见的机器学习算法有:l 构造条件概率:回归分 ...
- Spark生态以及原理
spark 生态及运行原理 Spark 特点 运行速度快 => Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算.官方提供的数据表明,如果数据由磁盘读取,速度是Hadoop MapR ...
随机推荐
- 如何开发一个npm包并发布到npm中央仓库
转自: https://liaolongdong.com/2019/01/24/publish-public-npm.html 如何开发一个npm包并发布到npm中央仓库需求背景:平时在项目工作中可能 ...
- 【Git】The authenticity of host '192.168.1.1 (192.168.1.1)' can't be established.
背景,在服务器用www用户身份 执行拉取命令报错 sudo -u www git pull 原因分析: 在新生成密钥之后,在.ssh文件夹中少了known_hosts文件 解决办法: Are you ...
- 转 perl DBI 总结
https://www.cnblogs.com/homezzm/archive/2011/07/22/2113618.html ##查看已经安装的包 #!/usr/bin/perluse strict ...
- python提取mysql中指定列参数,并循环打印
试验环境: Python 3.7.0 Mysql 5.0 实验目的: 使用python将数据库中指定的列中的数值取出来,并循环遍历,用以当成参数传递给需要它的方法. 本次实验取的是para列的数据 实 ...
- LinkedBlockingQueue与ArrayBlockingQueue
阻塞队列与普通的队列(LinkedList/ArrayList)相比,支持在向队列中添加元素时,队列的长度已满阻塞当前添加线程,直到队列未满或者等待超时:从队列中获取元素时,队列中元素为空 ,会将获取 ...
- [LeetCode] 687. Longest Univalue Path 最长唯一值路径
Given a binary tree, find the length of the longest path where each node in the path has the same va ...
- 【Django单元测试方法】
一.前言/准备 测Django的东西仅限于在MTV模型.哪些可以测?哪些不可以. 1.html里的东西不能测.①Html里的HTML代码大部分都是写死的②嵌套在html中的Django模板语言也不能测 ...
- Python Tkinter 窗口创建与布局
做界面,首先需要创建一个窗口,Python Tkinter创建窗口很简单:(注意,Tkinter的包名因Python的版本不同存在差异,有两种:Tkinter和tkinter,读者若发现程序不能运行, ...
- LeetCode 859. 亲密字符串(Buddy Strings) 23
859. 亲密字符串 859. Buddy Strings 题目描述 给定两个由小写字母构成的字符串 A 和 B,只要我们可以通过交换 A 中的两个字母得到与 B 相等的结果,就返回 true:否则返 ...
- 13 JSP、MVC开发模式、EL表达式和JSPL标签+软件设计架构---学习笔记
1.JSP (1)JSP概念:Java Server Pages 即java服务器端页面可以理解为:一个特殊的页面,其中既可以指定定义html标签,又可以定义java代码用于简化书写!!! (2)原理 ...